
Table of Contents
Your AI pilot worked. The demo impressed the board. Then you tried to scale it, and it stopped.
Not because the model was wrong. Not because the team lacked talent. The problem is older than all of that: your systems weren’t built to connect to anything new. Legacy AI integration doesn’t fail in the proof-of-concept phase. It fails the moment you try to run it on the infrastructure your business actually depends on.
The bottleneck isn’t your AI strategy. It’s the foundation strategy that runs on.
The AI Ambition Gap: Why Strategy Is Outpacing Infrastructure
CEOs now own the AI decision, but ownership doesn’t equal infrastructure readiness. Most organizations have the ambition. Few have the foundation.
72% of CEOs now own the AI decision, but ownership doesn’t equal readiness
According to the World Economic Forum (2026), 72% of respondents now identify the CEO as the primary decision-maker on AI, a significant jump from one-third the year before. That’s a striking shift in who holds the mandate.
But there’s a gap between holding a mandate and having the infrastructure to execute it. The WEF data shows confidence at the strategy level. What it doesn’t measure is whether the underlying systems can support the AI tools the strategy calls for.
Most can’t. Not because leadership isn’t serious, but because the systems those organizations depend on were designed before real-time AI inference, API-driven architectures, or vector databases existed. Deciding to adopt AI doesn’t change what your ERP was built to do.
“As Eric Kutcher, McKinsey North America Chair, has stated: companies that don’t move on AI won’t survive.” That’s the urgency framing boardrooms are working with. The problem is that urgency at the strategy layer can’t accelerate infrastructure that physically can’t support the next step.
What ‘AI-ready’ actually requires at the infrastructure level
Being AI-ready isn’t a posture. It’s a technical checklist that your systems either pass or fail.
At a minimum, AI-ready infrastructure requires:
- Real-time data access, AI models need to query live data, not yesterday’s batch export
- Callable APIs, AI agents, and tools need clean endpoints to trigger actions across your systems
- Data quality and schema consistency, models trained on dirty, siloed, inconsistently labeled data, produce unreliable outputs
- Observability, you need to know what the AI system is doing, why, and when it fails
Most legacy systems fail two or more of these tests. That’s not a reflection of past engineering decisions; it’s a reflection of when those systems were built. The requirements simply didn’t exist.
AI readiness assessment, read: “Legacy Systems: Close the AI Readiness Gap.”
What Makes a System ‘Legacy’ in an AI Context
‘Legacy’ in an AI context doesn’t mean old. It means architecturally incompatible with what AI systems require to function.
Batch processing vs. real-time inference: why the architectural mismatch matters
Your ERP runs nightly batch jobs. Your AI model needs to query data in milliseconds. These two facts are incompatible, and no middleware wrapper makes them compatible at scale.
Batch-processing architectures move data in scheduled cycles. They were designed for reporting and record-keeping, not for the sub-second response loops required by AI inference. When you try to layer an AI layer on top, you get two outcomes: either the AI model runs on stale data (reducing accuracy), or you build an increasingly expensive real-time data pipeline on top of an architecture that wasn’t designed to support one.
Neither is a solution. Both are expensive. The AI system you’re running on top of a batch architecture is never the AI system the demo showed you.
Data silos and the dirty data problem AI exposes
AI doesn’t hide bad data. It amplifies it.
When your sales data lives in Salesforce, your operational data in a 15-year-old on-prem database, and your finance data in a combination of spreadsheets and a custom ERP, any AI system that touches all three immediately surfaces every inconsistency, duplicate record, and missing field that your team has quietly managed around for years.
According to McKinsey, 70% of software in Fortune 500 companies is over two decades old. Those systems weren’t designed with data interoperability as a requirement. Every year of operation adds more idiosyncratic data structures, more schema drift, and more tribal knowledge about what the data “really means.” AI can’t work with tribal knowledge.
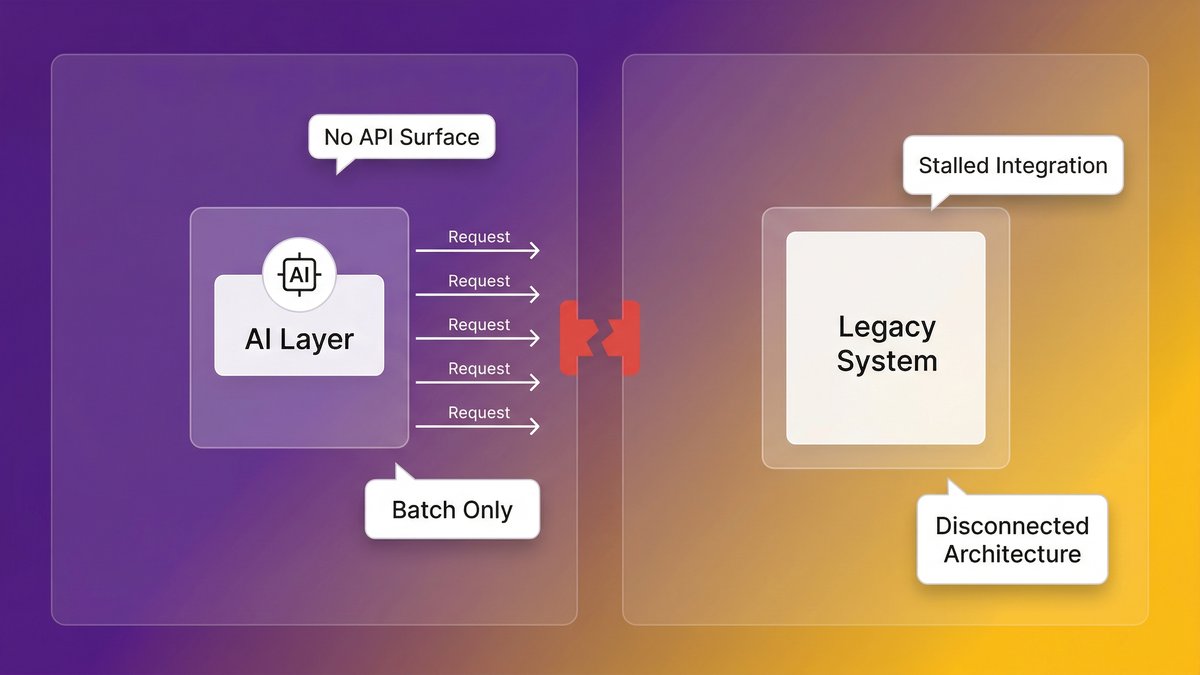
The API gap: when your systems can’t talk to anything new
Modern AI tools, and especially AI agents, operate by calling endpoints. They need to be able to query your data, trigger actions, and receive structured responses. This requires a clean API layer.
Most legacy systems don’t have one. They were built in an era of tight coupling, direct database calls, and human-driven workflows. Connecting them to an AI tool requires either building an API wrapper around an architecture that wasn’t designed for it or accepting that the AI tool simply can’t touch those systems. For mid-market companies where legacy systems hold the most operationally critical data, that second option is rarely viable.
The Hidden Cost: What Technical Debt Is Actually Doing to Your AI Timeline
Technical debt doesn’t just slow development. It consumes the budget and engineering capacity that AI adoption requires, before AI spending even starts.
Technical debt consumes 21–40% of IT budgets before AI spending begins
According to Deloitte’s 2026 Global Technology Leadership Study, technical debt accounts for 21% to 40% of an organization’s IT spending. That’s not the AI budget line. That’s the maintenance tax your team pays just to keep existing systems running.
It compounds directly with the AI readiness problem. The same engineering capacity that would build the API layers, clean the data pipelines, and modernize the architecture is already spoken for, maintaining systems that were supposed to be replaced years ago.
According to Making Sense (citing enterprise survey data from 2026), enterprises lose around $370 million annually due to outdated technology and technical debt, including maintenance costs, failed modernization attempts, and operational drag.
That’s not an abstract number. For a mid-market company operating at 1/100th of enterprise scale, the proportional cost still runs into seven figures annually, money that isn’t available for AI infrastructure investment because it’s already spent keeping the current infrastructure alive.
The opportunity cost: every month of delay is a month competitors are shipping AI features
This is the part that board conversations underweight: the cost of delay isn’t just the maintenance budget. It’s the compounding competitive disadvantage of watching competitors ship AI-native features while your team is buried in patch cycles.
Competitors who modernized their infrastructure 18 months ago are now deploying AI agents in production. They’re reducing operational costs, accelerating decision cycles, and building AI capabilities into products your team can’t replicate on your current stack.
Every month of delay isn’t neutral. It widens the gap. Technical debt cost
Why AI Projects Fail at Scale (And It’s Not the Model)
AI projects fail in production not because of the model, talent, or strategy, but because of the infrastructure. That’s a counterintuitive finding for teams that invest heavily in all three.
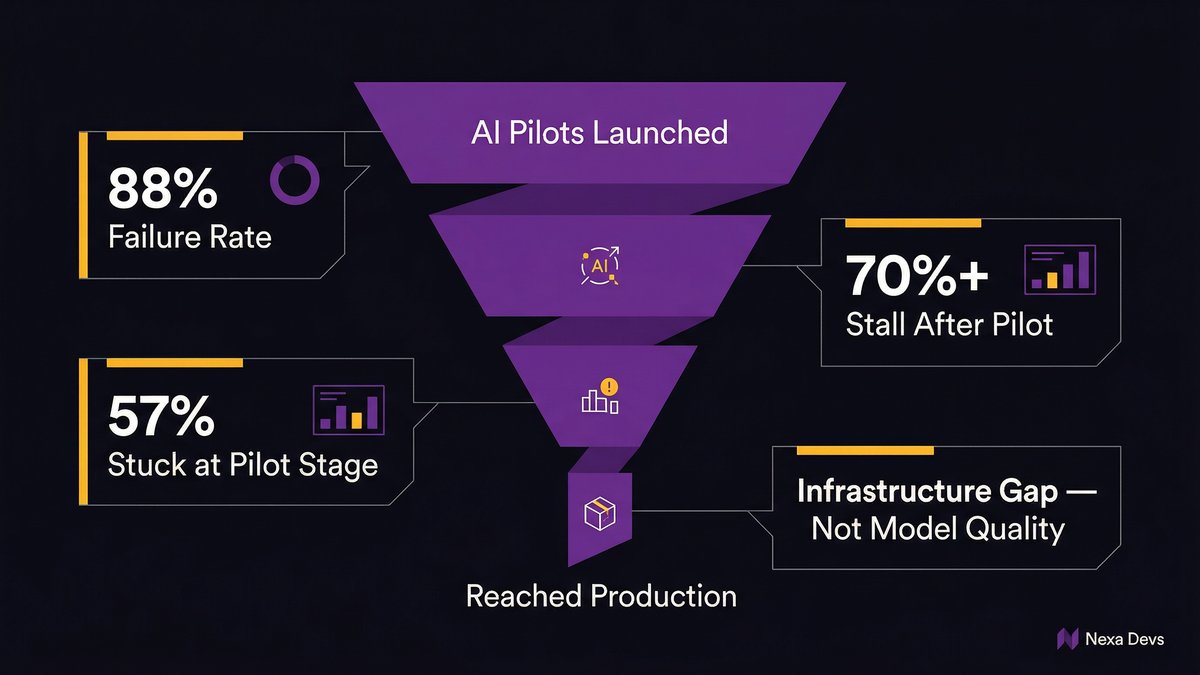
Over 70% of AI initiatives stall after pilot phases, due to infrastructure explanation
Over 70% of AI initiatives stall after pilot phases, even in organizations with advanced cloud and DevOps practices, with primary causes being structural platform limitations, not model performance or talent shortages, according to Arbisoft’s analysis of enterprise surveys (2026).
The pilot environment hides the problem. Pilots run on clean data extracts, controlled environments, and hand-selected use cases. None of those conditions exists in production. Production means the full data mess, the legacy system dependencies, the undocumented edge cases, and the latency requirements that a batch-processing architecture can never meet.
According to IDC Research, for every 33 AI pilots launched, only 4 reach production, an 88% failure rate. The gap between pilot and production is almost never a model problem. It’s an infrastructure problem.
This matters for how you frame the AI investment decision internally. If you’re evaluating whether to invest in AI, the first question isn’t “which AI tool should we buy?” It’s “Does our current infrastructure support what that tool needs to run?”
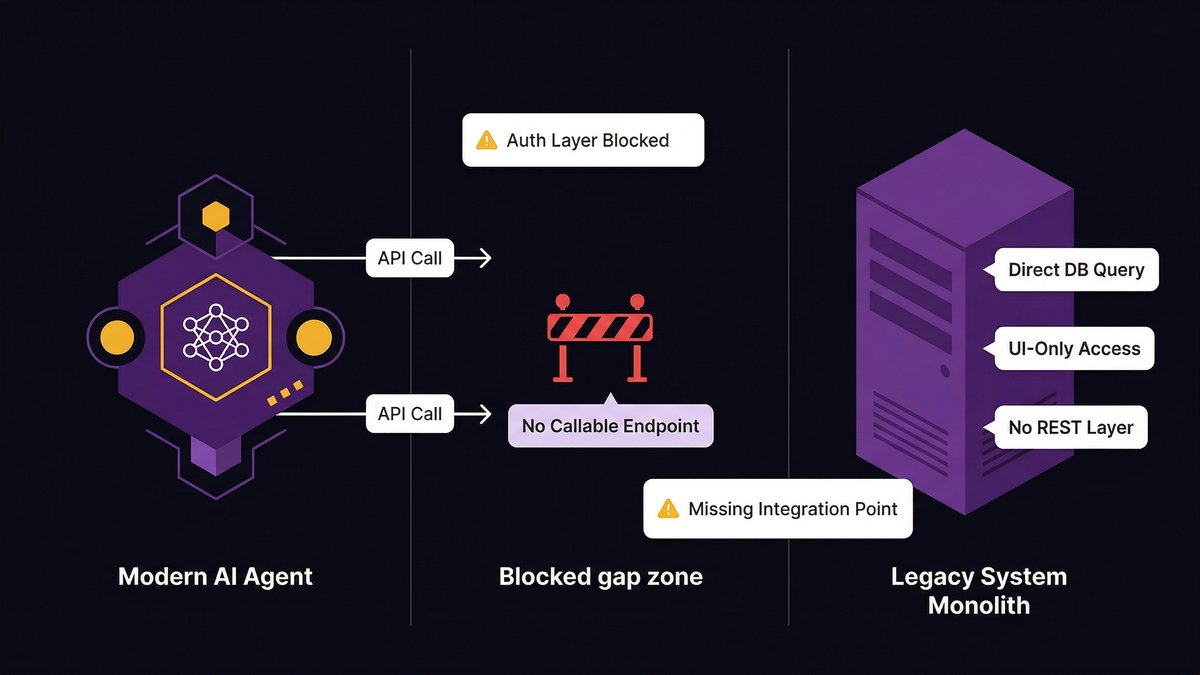
Agentic AI and real-time decisions expose legacy limits that prototypes hide
AI agents are more demanding than AI tools. A tool responds to a query. An agent takes multi-step actions: it calls an API, reads a result, decides what to do next, calls another system, and writes a record. Each step requires a clean, low-latency, reliable endpoint.
Legacy systems fail this test in ways that prototypes never reveal. A prototype that runs on a pre-extracted CSV file looks identical to a production agent until you try to give the agent live access to the system from which the CSV came. At that point, the architectural gap becomes visible, and it’s rarely fixable with a configuration change.
According to ITBrief (2026), 57% of enterprises remain in the pilot stage for agentic AI; only 15% have operationalized agents at scale. The 85% gap between aspiration and production isn’t a talent shortage. It’s a foundation shortage.
The Modernization Spectrum: From Duct Tape to a Real AI Foundation
Modernization isn’t binary. There’s a spectrum of approaches, each with different costs, timelines, and AI-readiness outcomes.
The 5 R’s: Rehost, Refactor, Rearchitect, Rebuild, Replace, what each buys you
The 5 R’s framework is the standard vocabulary for modernization decisions. Here’s what each option actually delivers in terms of AI readiness:
- Refactor and optimize existing code without changing the architecture. Improves performance marginally. Still doesn’t produce the API layer or data accessibility that AI requires. Better than nothing; not sufficient for AI readiness.
- Rehost (lift-and-shift): move the system to the cloud as-is. Fast and cheap. Produces zero AI readiness improvement. Your system is still batch-processing, still silo-enclosed, still without APIs. The only thing that changed is which data center it runs in.
- Rearchitect, Restructure the application to a more modern architecture (microservices, event-driven, API-first). This is where AI readiness becomes achievable. Expensive and time-consuming. Requires significant engineering investment. Worth it if executed correctly.
- Rebuild, rewrite from scratch on a modern stack. Maximum AI readiness potential. Maximum risk. Mid-market companies rarely have the runway for a clean rebuild of a production-critical system.
- Replace or swap with a commercial off-the-shelf system. Sometimes the right answer. Creates new integration dependencies and rarely produces the custom API surface your specific AI use cases need.
Most mid-market companies need a combination of approaches applied to different systems, not a single strategy applied uniformly.
API layering: the fastest path to AI connectivity without a full rewrite
For systems where a full rearchitecture isn’t feasible in the near term, API layering is the pragmatic path to AI connectivity. The approach: build a modern API layer on top of the legacy system, abstracting the underlying architecture from the AI tools that need to access it.
This isn’t a permanent solution. The underlying system is still batch-processing, still accumulating technical debt, still structurally limited. But it creates a bridge, a way to connect AI tools to legacy data without requiring a full rearchitecture first.
The key constraint: API layering works when the underlying system can surface data with acceptable latency. If the legacy system can’t serve results fast enough to support real-time inference, the API layer becomes a well-engineered dead end.
When phased modernization works, and when it just delays the reckoning
Phased modernization works when each phase produces a working, AI-ready component. It stalls when phases are planned around technical milestones rather than AI capability unlocks.
The difference is in how you sequence the work. A phase that produces a clean API surface for your highest-priority data domain is immediately valuable; AI tools can start using that domain while subsequent phases continue. A phase that cleans up internal code without producing any new external interface produces nothing your AI strategy can use until the next phase completes.
Sequencing phases by AI capability unlock, not by technical convenience, is the difference between phased modernization that builds momentum and one that takes 3 years to produce the first usable result.
The Trap: Why Most Modernization Programs Fail to Deliver AI Readiness
The standard modernization playbook is designed for a world where the goal is a better system. That goal has changed; now the goal is an AI-ready system. Those aren’t the same thing, and most programs haven’t caught up.
Modernization projects that run separately from product delivery create two-year delays
The conventional approach: stand up a modernization workstream, run it in parallel with the product team, reconnect them when modernization is “done.” This approach fails for mid-market companies for a specific reason: they don’t have the engineering capacity to run two parallel workstreams.
What actually happens: the modernization project competes with the product roadmap for engineering time. Product wins, because the product has visible deliverables and stakeholders applying deadline pressure. Modernization slips. The timeline extends. Two years become three. Competitors who didn’t wait are shipping AI features.
Legacy modernization projects run 45% over budget and 7% behind schedule on average, according to Fingent’s analysis of enterprise modernization data (2026). That’s the average. Mid-market companies, with thinner engineering benches and fewer resources to absorb overruns, perform worse.
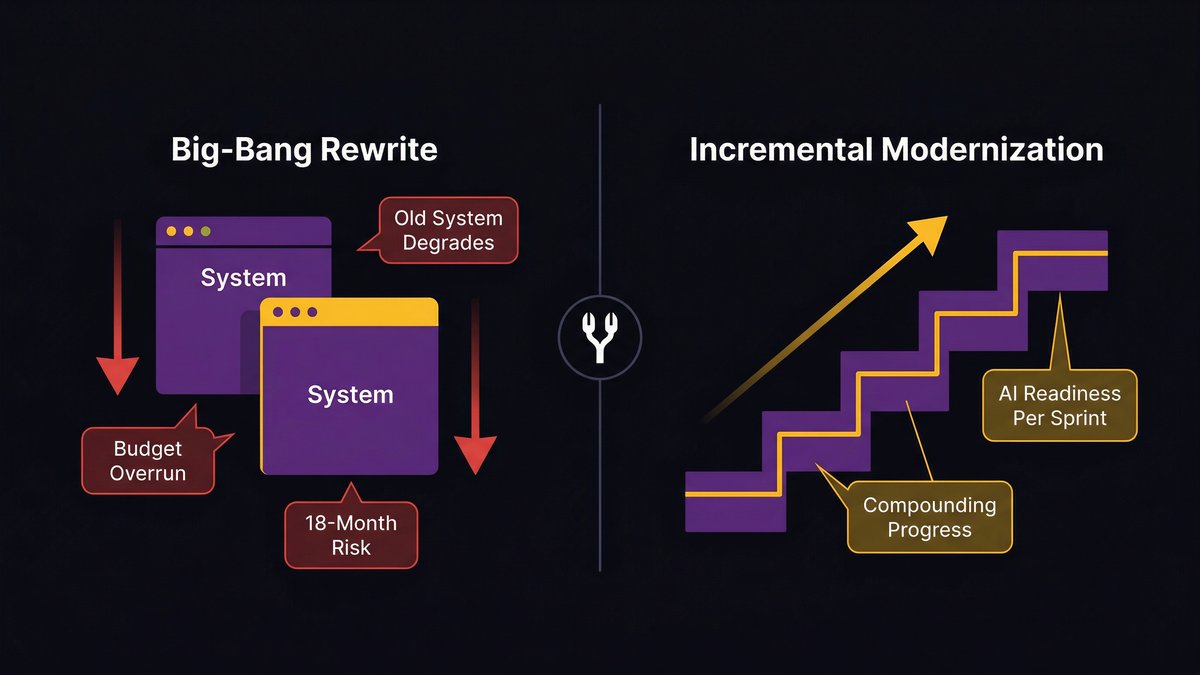
The ‘big bang’ rewrite risk: why it stalls mid-market companies specifically
The big-bang rewrite is the scenario every CTO fears and every board eventually proposes. The logic sounds reasonable: stop patching, start fresh, build the AI-ready system you should have built five years ago.
The execution is almost always a disaster. Here’s why it’s especially dangerous for mid-market companies:
A big-bang rewrite requires running two systems in parallel: the old system (which the business depends on) and the new system (which the team is building). Mid-market engineering teams rarely have the capacity to maintain production fidelity on a live system while simultaneously building its replacement from scratch.
The result: the old system degrades (because maintenance capacity is diverted), the new system takes longer than planned (because scope always expands), and the business ends up in a worse position at month 18 than it was at month zero, having spent the modernization budget, delayed AI adoption, and accumulated new risk on both systems simultaneously.
Nearshore doesn’t fix this by itself. But it changes the capacity constraint, which is what makes the alternative model viable.
A Different Model: Modernizing the Foundation While You Build
The right answer for mid-market companies isn’t choosing between modernizing and shipping. It’s finding a delivery model where modernization is a byproduct of delivery.
What AI-augmented delivery looks like in practice
AI-augmented delivery means applying AI across every phase of the software development lifecycle, not just at the code generation step.
At the requirements phase, AI surfaces architecture conflicts and integration risks before a line of code is written. At the design phase, AI generates architecture diagrams and API specifications that would otherwise take weeks to produce manually. During implementation, AI accelerates code generation while enforcing the clean architecture patterns required for AI readiness. At testing, AI generates comprehensive test coverage alongside delivery, not as a separate phase after.
The output isn’t just faster delivery. It’s delivery that produces cleaner systems with better documentation, higher test coverage, and more consistent architecture than traditional delivery. Systems that emerge from an AI-augmented delivery process are structurally more AI-ready than systems built the conventional way, because the process itself enforces the architectural patterns AI tools need.
How nearshore teams compress the modernization timeline without offshore risk
Nearshore teams operating in the U.S. timezone alignment change the capacity equation for mid-market companies specifically. Instead of choosing between a two-year modernization project and a big-bang rewrite, nearshore augmentation creates a third option: a dedicated team working in real-time coordination with your internal engineers, modernizing and building simultaneously.
This isn’t theoretical. It’s a delivery model. The nearshore team isn’t working on a separate track; it’s integrated into the delivery cycle, working the same hours and in the same Scrum process, producing both feature delivery and the architectural improvements that make future AI integration possible.
As Ashwin Ballal, CIO at Freshworks, has noted, adding vendors to complex systems risks trading one problem for another. The nearshore model only avoids that trap if the delivery process produces clean documentation and clean architecture, so the team that inherits the system (whether internal or external) actually understands what was built.
The ‘getting there in the process’ principle: AI readiness as a byproduct of delivery
The framing shift is this: AI readiness doesn’t have to be a precondition for AI adoption. It can be a byproduct of how you build.
If each sprint produces both a working feature and a cleaner architectural layer, a new API endpoint, a resolved data silo, a documented service boundary, then AI readiness accumulates over time as a function of delivery, not as a separate workstream competing with delivery.
At Nexa Devs, every engagement is structured this way. Systems emerge from the delivery process with clean architecture, complete documentation, and API surfaces that AI tools can actually use. The client doesn’t wait for a two-year modernization project to complete before AI adoption becomes possible. They’re getting there in the process.
Nearshore AI development, read: “AI legacy modernization 2026 window.”
Where to Start: A Practical AI Readiness Assessment for Mid-Market Leaders
You don’t need a six-month consulting engagement to know whether your infrastructure can support AI. Three questions will tell you most of what you need to know.
Three questions that reveal your actual AI readiness (not your strategic intentions)
Question 1: Can your highest-priority AI use case access live data, not a batch export?
Name the AI capability you most want to deploy. Now ask: Does it need access to data that currently lives in a batch-processing system? If the data your AI model needs is only available after a nightly job runs, you don’t have an AI use case; you have a reporting use case. Real-time AI inference requires real-time data access.
Question 2: If an AI agent needed to trigger an action in your core operational system, what would it call?
AI agents need callable endpoints. Think about your ERP, your CRM, your core data system. Does it expose a clean, documented API? Or would an AI agent need to interact with it the way a human does, through a user interface, a manual import, or a database query that bypasses the application layer entirely?
If the answer is “there’s no API,” you know where your first modernization investment needs to go.
Question 3: Who holds the knowledge of how your systems actually work?
According to Deloitte’s 2026 Global Technology Leadership Study, technical debt accounts for 21–40% of IT spending. A large fraction of that spending is the human cost of maintaining systems that only specific people understand. If two engineers left tomorrow and took their system knowledge with them, would your modernization path be blocked?
Undocumented systems can’t be modernized efficiently. They can’t be handed to an AI tool for analysis, they can’t be onboarded to a new team in a reasonable timeline, and they can’t be incrementally improved without the risk of breaking something nobody documented.
Prioritizing the highest-leverage modernization moves for your stack
Not everything needs to be modernized to unlock AI readiness. You need to identify the three or four systems that your highest-priority AI use cases actually depend on, and modernize those first.
The highest-leverage moves, in order:
- Build an API layer on your most data-rich legacy system. This creates the connection point AI tools need without requiring a full rearchitecture.
- Resolve the data silo that your AI use case depends on the most. One clean, consistent, real-time data domain is more valuable than five partially cleaned ones.
- Document the undocumented. Systems that no AI tool can analyze and no new engineer can safely touch are a modernization blocker regardless of architecture.
- Start with a readiness assessment, not a roadmap. A roadmap plans for where you want to go. An assessment tells you where you actually are. You need the second before the first is useful.
If you want a structured starting point, book an architecture assessment. We’ll map your current systems to AI agent requirements and provide a prioritized modernization path tailored to your specific stack, not a generic framework.
You’re Not Waiting for AI. AI Is Waiting for Your Foundation.
The companies pulling ahead on AI aren’t the ones with the best AI tools. They’re the ones whose infrastructure can actually run those tools at scale.
The bottleneck is real. The cost of delay is real, in maintenance spend, in engineering capacity, and in the compounding competitive gap that widens every month you wait. What’s also real is that you don’t have to choose between modernizing and shipping. The right delivery model does both simultaneously.
If you want to understand where your current systems stand against AI-agent requirements, specifically, start with an architecture assessment. We’ll map your stack, identify the highest-leverage modernization moves, and give you a concrete starting point.
Not a two-year roadmap. A first step.
FAQ
What is legacy AI integration?
Legacy AI integration is the process of connecting AI tools, models, or agents to enterprise systems that weren’t designed with AI in mind. It typically involves building API layers, resolving data silos, and modernizing the architectural patterns that prevent legacy systems from supporting real-time AI inference.
What is AI’s number one bottleneck?
Infrastructure is AI’s number one bottleneck, specifically legacy systems that can’t provide real-time data access, callable APIs, or consistent data quality. Over 70% of AI initiatives stall after pilot phases due to structural platform limitations, not model performance or talent gaps.
What is the difference between legacy systems and AI?
Legacy systems were built for batch processing, tight coupling, and human-driven workflows. AI systems require real-time data access, clean API endpoints, consistent data schemas, and a loosely coupled architecture. The mismatch between these two design paradigms is the core challenge of legacy AI integration.
Is replacing a legacy system worth it?
Replacing a legacy system is worth it when maintenance costs and AI incompatibility exceed replacement costs, which is often the case when technical debt consumes 40% of IT budgets (Deloitte, 2026). A full replacement isn’t always necessary; API layering and phased rearchitecture often deliver AI readiness faster and at lower risk.
What are the 5 R’s of modernization?
The 5 R’s are: Rehost (lift-and-shift), Refactor (optimize existing code), Rearchitect (restructure to a modern architecture), Rebuild (rewrite from scratch), and Replace (swap for commercial software). For AI readiness, Re-architect and Rebuild produce the most impact; Rehost alone produces none.
What is legacy integration?
Legacy integration connects older enterprise systems to modern tools or platforms through APIs, middleware, or data pipelines. In an AI context, it specifically addresses making existing systems accessible to AI models and agents without requiring a full system replacement.