The Excel File Everyone Depends On: Why Spreadsheet-Run Operations Break at Scale
You know which file it is. There’s one spreadsheet in your operation that, if it disappeared tomorrow, would take two or three people a full week to reconstruct. Everyone knows it exists. Nobody has a plan for when it breaks.
That file is not a tool. It’s load-bearing infrastructure, and it was never designed to be.
The question isn’t whether you should replace spreadsheets with software. At a certain scale, you already know you should. The question is what kind of software actually solves the problem, and why every company your size has already tried one version of the answer and come back frustrated.
This post is the COO’s case for fixing this properly. Not an IT project. A business continuity decision.
The Spreadsheet That Runs Your Business Is Also Your Biggest Single Point of Failure
Spreadsheets run critical workflows in mid-market operations because they fill a gap that no packaged system closes. That’s the honest answer. It’s not a failure of discipline or a sign of technical immaturity. It’s a rational response to a real gap.
How spreadsheets became load-bearing infrastructure
A new workflow emerges. There’s no system for it. Someone builds a spreadsheet. It works well enough, so it stays. A year later, it has 14 tabs, 3 people contributing on alternating days, and 1 person who actually understands the formulas in column Q.
That’s how spreadsheets become load-bearing infrastructure. Not through negligence. Through incremental adoption of something that solved an immediate problem, without anyone stopping to ask what it would look like at 10x the volume.
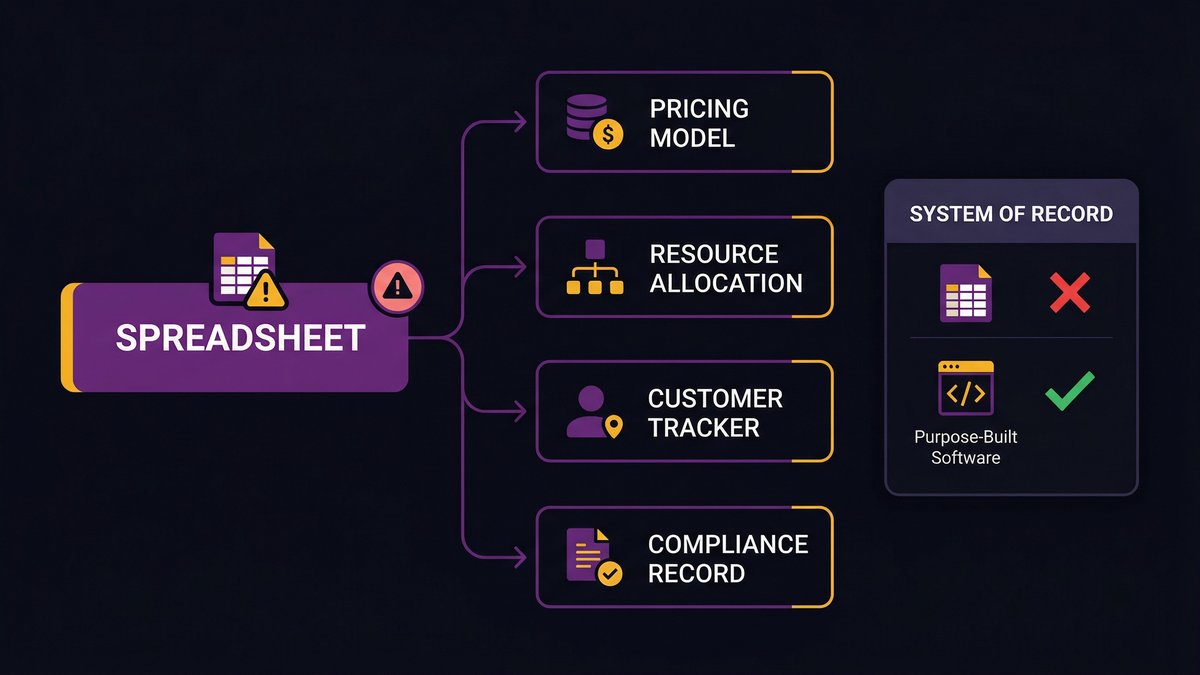
The spreadsheet was designed for analysis. When it becomes the system of record for an operational workflow, you’ve repurposed a hammer as a crane.
The moment a “temporary workaround” becomes the system of record
The tipping point is when the spreadsheet starts driving downstream decisions. A pricing model that finance trusts. A resource allocation sheet that three department heads reference every Monday. A customer status tracker that the sales team treats as the CRM, the CRM doesn’t actually handle.
Once a spreadsheet drives decisions, it’s a system of record. It just doesn’t behave like one. It has no access controls. No audit trail. No version history that means anything. No automated alerts when data is missing or out of range.
According to Forrester Consulting (commissioned by Thomson Reuters, October 2025), 48% of organizations cite legacy technology as their primary operational roadblock. The spreadsheet is almost always part of what they mean.
What “Breaking at Scale” Actually Looks Like in Operations
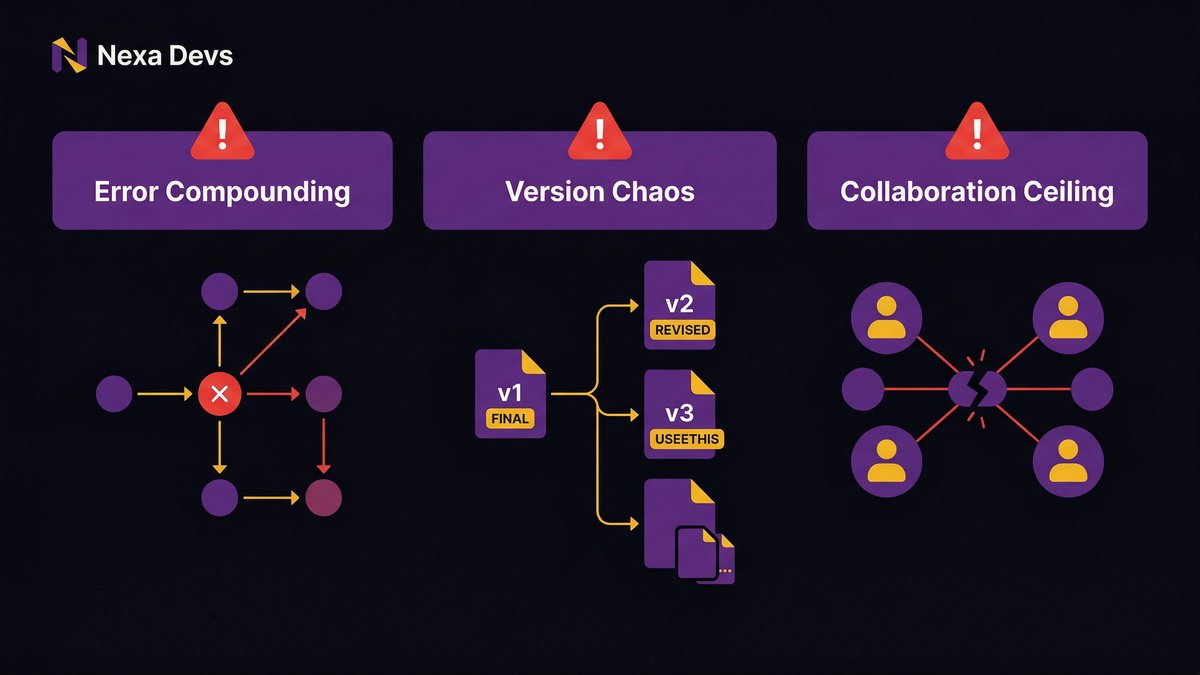
Scale pressure on a spreadsheet-dependent operation produces three failure modes. Not abstract risks. Concrete, operational breakdowns that COOs at growth-stage companies recognize immediately.
Error compounding: how one wrong cell multiplies across departments
A single transposed digit in a pricing spreadsheet is entered into a contract template, which is then fed into the billing system, which produces an invoice that the client disputes three months later. By the time the error surfaces, it’s touched six documents and two external relationships.
According to Oracle, an electricity transmission company lost $24 million due to a misaligned spreadsheet row in a single cut-and-paste error. That’s not an outlier. It’s a known failure mode with a known mechanism.
Research cited by Qashqade estimates that 9 out of 10 spreadsheets with more than 150 rows contain at least one error. Your most important operational spreadsheet almost certainly has more than 150 rows.
Version chaos: which file is correct when six people saved their own copy?
“Operations_tracker_v3_FINAL_JAN_revised_USEETHIS.xlsx” in someone’s local drive. A different version in the shared folder. A third copy was emailed to a VP last Tuesday. Which one has the correct numbers?
Version chaos isn’t a workflow problem. It’s a decision-making problem. When no one fully trusts the numbers, decision-making slows. Leadership asks for reconciliation before acting. Reconciliation takes time. Decisions that should happen Tuesday happen Thursday, or don’t happen at all.
According to Forrester Consulting, 55% of organizations report that disjointed workflows lead to excessive time spent on time-tracking across platforms. Version chaos is the spreadsheet expression of this exact problem.
The collaboration ceiling: why real-time coordination fails in Excel
Excel was designed for a single user working alone. The collaboration model in modern spreadsheet tools is better than it used to be, but it’s still built around a file, not a workflow. You can’t assign a task, set an approval gate, or trigger an automated notification from a cell value. You can’t enforce a business rule. You can’t give a new employee the right access without giving them the whole file.
When your operation needs real-time coordination across functions, a spreadsheet creates a collaboration ceiling. The team works around it, more meetings, more Slack messages, more manual handoffs. The workarounds accumulate until the system underneath them is invisible.
The Hidden Cost Most COOs Never Fully Add Up
The direct failure events get attention. A $24 million loss from a cut-and-paste error is a story someone tells. What doesn’t get added up is the daily cost that compounds silently.
Staff hours lost to manual reconciliation and report prep
According to Forrester Consulting (commissioned by Thomson Reuters, October 2025), 42% of workers spend excessive time searching for and requesting data they need to do their jobs. In a spreadsheet-dependent operation, most of that searching is the job. Someone has to pull the data from three sources, reconcile the mismatches, and build the report that leadership needs for Monday’s meeting. Every week.
One mid-market operations team documented 30 hours per month spent on manual report preparation. Not because they were inefficient. Because the system required it.
Multiply 30 hours per month by the fully-loaded cost of the people doing it. Then multiply by 12 months. Then ask how many months of custom software development that number would buy.
Decision latency: what delayed data costs in fast-moving operations
When your operational data lives in a spreadsheet that’s only updated on Fridays, you make Monday’s decisions on week-old information. In a stable business, that’s inconvenient. In a fast-moving one, it’s strategic exposure.
Decision latency is the gap between when something happens in your operation and when the decision-maker has accurate information about it. The spreadsheet maximizes that gap. Purpose-built software closes it.
The audit and compliance exposure nobody talks about
An auditor asks for the history of changes to a contract pricing model. You open the spreadsheet. There is no audit trail. The formula in column R has been modified eleven times by four people over two years, and there is no record of who changed what or when.
This is not a theoretical compliance risk. It’s a common outcome of using spreadsheets for processes that require auditability. Healthcare operations, financial services, legal workflows, procurement approvals, all of these carry audit requirements that spreadsheets structurally cannot meet.
A manufacturer incurred an $11 million error in employee severance packages due to a spreadsheet typo, according to Oracle. The financial exposure was the headline. The compliance exposure from the lack of an audit trail was the quieter risk sitting beneath it.
The Key-Person Risk Nobody Puts on the Risk Register
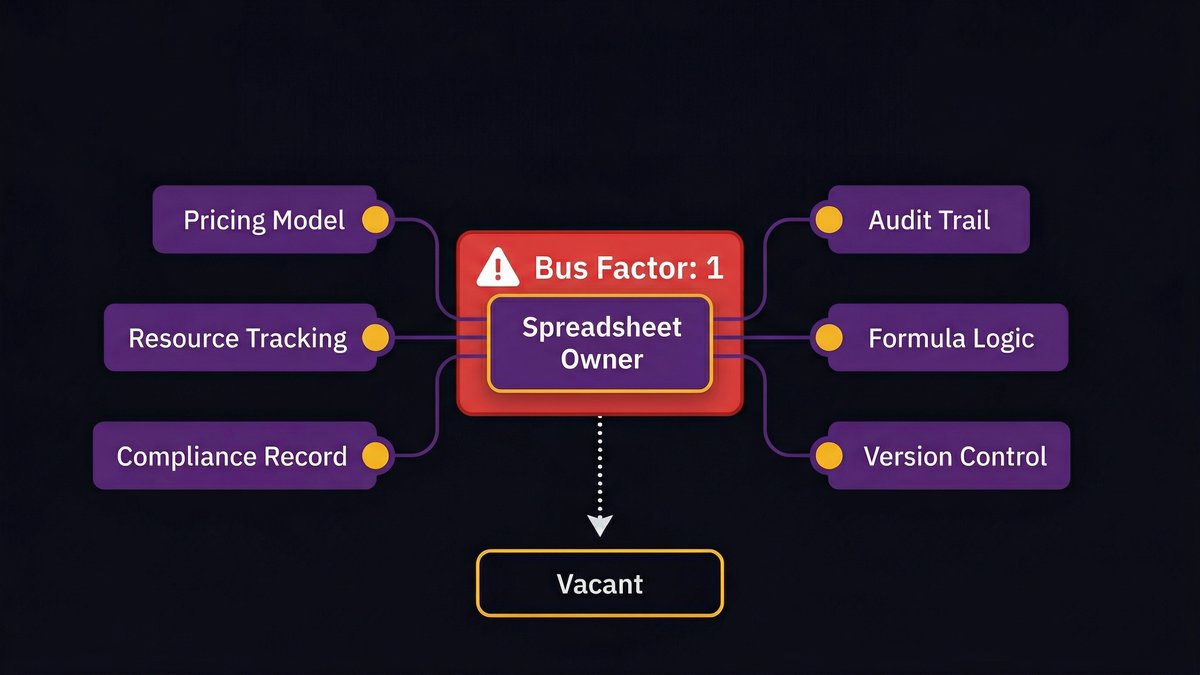
Here’s the failure mode no competitor’s content covers: the spreadsheet itself isn’t the single point of failure. The person who built it is.
When the spreadsheet owner leaves, the operation stalls
Every COO knows who this person is. The one who built the master tracker. The one who understands why row 47 has a manual override and what happens if you delete it. The one who gets called when the numbers don’t add up.
When that person leaves, for a better offer, for a life change, for any of the hundred reasons people leave, the operation doesn’t just lose a contributor. It loses institutional knowledge that was never written down anywhere.
Research from ClearlyAcquired found that replacing high-level operational talent costs 150 to 400% of an employee’s annual salary and delays projects by 6 to 12 months. That’s before accounting for the specific cost of reconstructing an undocumented spreadsheet system from scratch.
The same pattern shows up in software teams: MySQL and PostgreSQL, two of the world’s most-used databases, each have a bus factor of 2, according to analysis by JetBrains’ Bus Factor Explorer. That means those entire systems depend on two contributors. Your operations spreadsheet, realistically, has a bus factor of 1.
How institutional knowledge gets locked inside formulas
The formula in column Q isn’t just a formula. It encodes a business decision someone made in 2021 about how to calculate a margin adjustment for a specific product category. The person who made that decision understood why. The formula doesn’t explain it. The spreadsheet doesn’t document it. The next person to touch it either keeps it without understanding it, or breaks it trying to update it.
This is how institutional knowledge gets locked inside spreadsheets. Not maliciously. Incrementally. Each formula that encodes a business rule without documenting it adds another layer of dependency on the person who wrote it.
Custom internal software doesn’t automatically fix this. But software built with documentation as a standard deliverable, and designed around your actual workflow rather than someone’s mental model of it, closes the gap in a way no spreadsheet can.
Why “Just Switch to a SaaS Tool” Is the Wrong Prescription
Every COO who’s been in this situation has tried the SaaS migration. You know what happens. The tool doesn’t quite fit. The workaround in the spreadsheet gets rebuilt as a workaround in the new platform. Three months later, you have the old problem plus a new tool license.
Off-the-shelf tools are built for average workflows, not yours
SaaS tools are built for the average version of your use case. Your use case isn’t average. It’s the specific operational workflow your business has developed over years of dealing with your specific customers, your specific product mix, and your specific approval structure.
A generic project management tool doesn’t know that your approval workflow has a carve-out for contracts over $50,000 that need a second sign-off. A generic CRM doesn’t know that your customer success team tracks a custom lifecycle stage that your sales cycle depends on. A generic inventory system doesn’t know that your SKU numbering convention maps to a legacy system you can’t replace yet.
So you customize. And you layer on the customization. And eighteen months after the SaaS migration, the tool is as complicated to maintain as the spreadsheet was, except now you’re paying a monthly license fee and dependent on a vendor’s roadmap for every change.
The SaaS migration that recreates the same problem in a new platform
The deeper problem is structural. Off-the-shelf tools are built to serve as many customers as possible. Your workflow is an edge case. The tool serves the middle of the distribution. Your operation lives at the edge.
This is why SaaS migrations so often recreate the original problem in a new container. The workflow doesn’t fit the tool. The team adapts to the tool instead of the tool adapting to the workflow. The adaptation creates friction. The friction creates workarounds. The workarounds accumulate. The spreadsheet comes back, now it’s a companion to the SaaS tool, not a replacement for it.
The right answer here is the one most mid-market companies haven’t seriously considered: purpose-built internal software designed from the start to match your actual workflow. Not a generic product reshaped to approximate it.
The Structural Fix: Software That Matches How Your Operation Actually Works
Purpose-built internal software isn’t a new concept. Large enterprises have been building it for decades. What’s changed is that the cost and timeline barriers that made it inaccessible to mid-market companies no longer apply the way they used to.
What purpose-built internal tools look like versus off-the-shelf alternatives
A purpose-built internal tool starts with your workflow, not with a product category. It’s designed around the specific data your team works with, the specific approval structures your organization uses, and the specific integrations your systems require.
It has the audit trail your compliance team needs. It has the access controls your security policy demands. It has the reporting views your operations leadership actually uses. Not approximations of these things. The actual things, built to your specification.
The result isn’t a polished consumer product with a generic feature set. It’s a working tool that fits your operation the way a custom solution fits its problem. The people who use it adopt it because it’s easier than the spreadsheet they used to use, not because they’re required to.
Where to start: mapping the spreadsheets that are doing the most damage
Not every spreadsheet needs to be replaced. The goal isn’t to eliminate Excel. The goal is to identify which spreadsheets are load-bearing, driving decisions, managing compliance-sensitive data, coordinating cross-functional workflows, and replace those with systems that can actually carry the load.
A practical starting point is a spreadsheet dependency audit. List your ten most-used spreadsheets. For each one, answer four questions: What decisions does it drive? Who owns it? What happens if that person is unavailable for two weeks? What would a compliance audit surface if it reviewed the change history?
The answers identify your highest-risk dependencies. Those are the workflows that should become purpose-built software first.
How nearshore AI-augmented development makes custom software viable at mid-market scale
The barrier that has historically blocked mid-market companies from custom internal software is cost and timeline. Enterprise-level custom development is expensive and slow. The ROI calculation didn’t work for a 200-person operations team.
That calculation has changed. Nearshore development teams, operating in U.S. time zone alignment at significantly lower cost than U.S.-based teams, have made the economics viable at mid-market scale. AI-augmented development processes compress timelines further: AI-assisted requirements analysis, sprint planning, and code generation mean that workflows that would have taken six months to build now take two or three.
The result is custom internal software that fits your operation, built at a cost that makes sense for your revenue tier, delivered in a timeline that doesn’t require a multi-year commitment before you see results.
At Nexa Devs, we build purpose-built internal tools for mid-market B2B operations teams using this exact model. AI across every phase of the development lifecycle. Complete documentation delivered and owned by you at close. A post-launch support partnership that doesn’t disappear when the project does.
If you’re running critical workflows on spreadsheets your operation can’t afford to lose, we should talk. Book a discovery call
What to Expect: Signs You’ve Outgrown Your Spreadsheets (and What Comes Next)
Not every operations team is at the same point in this progression. Some are at the early stage of spreadsheet dependency, where the risks are manageable. Others are already at the point where a single bad week could surface a failure they can’t recover from quickly.
The 5 signals that indicate your operation is spreadsheet-constrained
If three or more of these describe your operation, you’re spreadsheet-constrained:
You have a spreadsheet that only one person fully understands. Key-person dependency is the clearest signal. If that person left this month, how long would it take to reconstruct the system?
Reconciling reports before leadership meetings takes more than two hours per week. Manual reconciliation is a symptom of disconnected systems. The spreadsheet is almost always at the center of it.
You’ve had a significant error traced back to a spreadsheet in the past twelve months. One event is a warning. Two is a pattern.
Your team uses a spreadsheet to manage a workflow that touches compliance, contracts, or customer commitments. If it needs an audit trail and doesn’t have one, it’s a liability.
A new employee takes more than a week to understand how a critical spreadsheet works. Onboarding friction this high means the system’s institutional knowledge is already locked in the formulas.
A practical first step: the spreadsheet dependency audit
The audit takes about a half-day for an operations director who knows the business. The output is a ranked list of your highest-risk spreadsheet dependencies, scored by operational impact, key-person exposure, compliance risk, and replacement complexity.
That ranked list is your starting point for a software investment conversation. Not a full system map. Not a technology roadmap. Just a clear answer to: which spreadsheet, if it failed tomorrow, would hurt us the most? Start there.
The Bottom Line on Replacing Spreadsheets With Software
Nearshore beats offshore for most mid-market operations teams needing custom internal tools. Here’s why: U.S. timezone overlap means your operations team can actually work in real time with the developers building their system. That’s not a minor convenience. It’s the difference between a tool built around your actual workflow and one built around a specification written at the start of a project and never revisited.
The spreadsheet isn’t going away. It’s useful. It should stay useful for analysis, one-time calculations, and the things it was designed to do. What it shouldn’t be is your single source of truth for an operational workflow that your business depends on.
If you’ve identified a spreadsheet that fits that description, you already know what needs to happen. The question is whether you do it before something breaks, or after.
Ready to map your highest-risk spreadsheet dependencies? Talk to a Nexa Devs team member about a spreadsheet dependency audit for your operations workflow.
What are the risks of using spreadsheets for business operations?
The main risks are data errors that compound across departments, version chaos from multiple copies, key-person dependency when one employee owns a critical file, and compliance exposure when workflows require audit trails that spreadsheets can’t provide. Single errors have caused documented losses of $11 million and $24 million in real business cases.
What are the limitations of using a spreadsheet model for operational workflows?
Spreadsheets lack access controls, audit trails, automated validation, and real-time collaboration for large teams. They don’t enforce business rules, scale to high-volume cross-functional workflows, or protect against single-point-of-failure knowledge dependencies when one person understands the underlying logic.
What do people use instead of Excel for business operations?
Teams use purpose-built internal software for complex, compliance-sensitive, or operationally critical workflows. They use off-the-shelf SaaS tools for standard workflows that fit a known product category. Mid-market teams with highly specific workflows often find SaaS tools recreate the same problems in a new platform.
What is an example of an operational risk incident caused by a spreadsheet?
An electricity transmission company lost $24 million when misaligned spreadsheet rows from a cut-and-paste error went undetected. A manufacturer separately incurred an $11 million severance error from a spreadsheet typo. Both lacked automated validation, an audit trail, and safeguards against human input errors.
When should you invest in custom software instead of managing spreadsheet risk?
When a spreadsheet drives decisions, manages compliance-sensitive data, or coordinates cross-functional workflows, it’s a system of record without the controls it needs. At that point, purpose-built internal software designed around your specific workflow is almost always the right replacement over a generic SaaS tool.
Your IT team calls it technical debt. Your CFO doesn’t see it anywhere. That’s the problem.
The cost is real, it’s enormous, and it’s already inside your budget, hidden inside delivery estimates, recruiting premiums, and projects that were supposed to take two weeks but took twelve. The ROI of paying it down isn’t a theoretical IT calculation. It’s a P&L argument you can take to your board right now, built on four cost categories and a payback period your CFO will recognize.
This framework walks you through exactly that calculation.
The Silent Tax Your CFO Doesn’t See on Any Balance Sheet
Technical debt doesn’t show up in your financial reporting. That’s what makes it dangerous. It’s a cost your organization absorbs every single quarter without a line item to point at.
Why technical debt never appears in standard financial reporting
Standard financial reports capture what you spend, not what you’re prevented from earning. Technical debt operates entirely in the second category. Every sprint takes three weeks instead of one because the codebase is fragile — that’s a cost. Every senior engineer who declines your offer because they won’t work in a decade-old stack — that’s a cost. Every product feature you couldn’t ship while a competitor did — that’s revenue you didn’t book.
None of these appear as a debit on any standard balance sheet. They appear as a pattern of “slower than expected,” “harder than it should be,” and “we’ll get to that next quarter.”
As Ray Forte, an executive at Analog Devices, put it after auditing their own IT portfolio: “The first thing we did was calculate what percentage of our investment would be needed to keep the lights on. It was in the low 80s.”
He didn’t need a technical audit to find the problem. He found it in the budget.
Where the costs actually hide: delivery estimates, recruiting premiums, and deferred revenue
Three specific places absorb technical debt cost without labeling it:
Delivery estimates. Teams working in legacy codebases routinely quote 3–5x the time to deliver compared to teams working in clean architectures. That multiplier is technical debt expressed as opportunity cost.
Recruiting premiums. Senior engineers won’t join companies running end-of-life stacks without meaningful extra compensation — or they won’t join at all. The premium you pay to attract talent to a legacy environment is a hidden maintenance cost.
Deferred revenue. When a competitor ships a feature in two weeks, and your team needs twelve, the revenue gap between those timelines belongs on your technical debt ledger. It won’t be there, but it should be.
According to Deloitte’s 2026 Global Technology Leadership Study, technical debt accounts for 21% to 40% of an organization’s IT spending, with nearly 60% of surveyed leaders believing an additional 21–50% of enterprise value remains trapped due to technical debt’s effects.
That’s not an engineering estimate. That’s senior technology leaders describing the opportunity cost in financial terms.
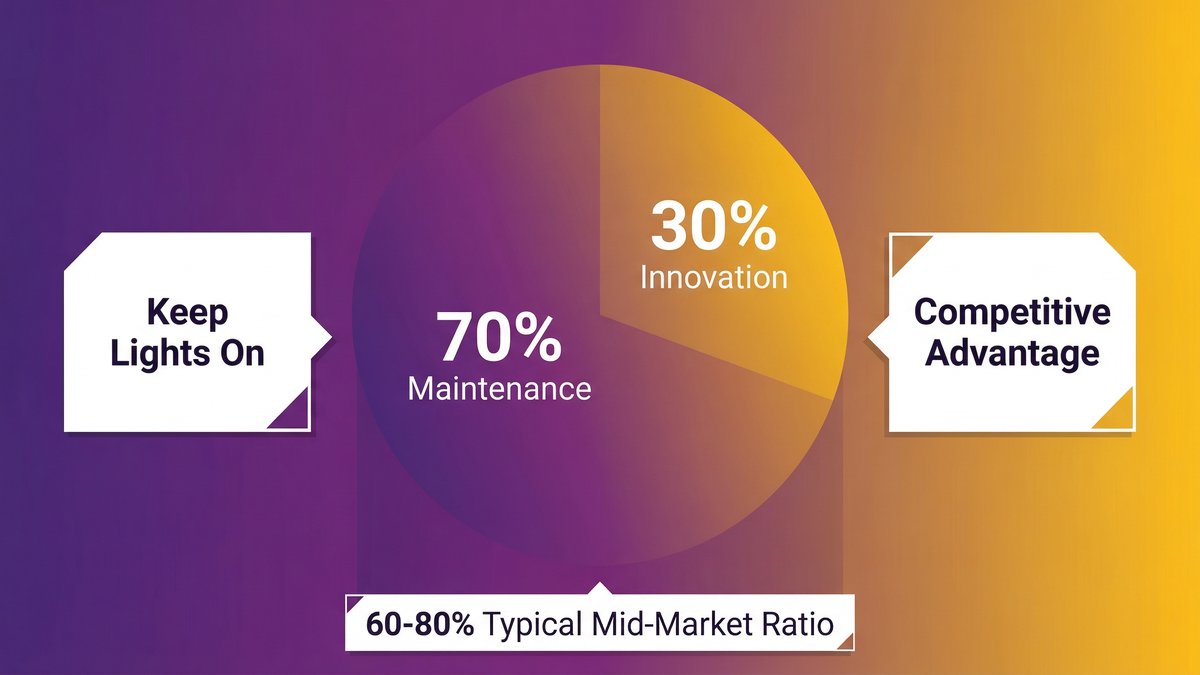
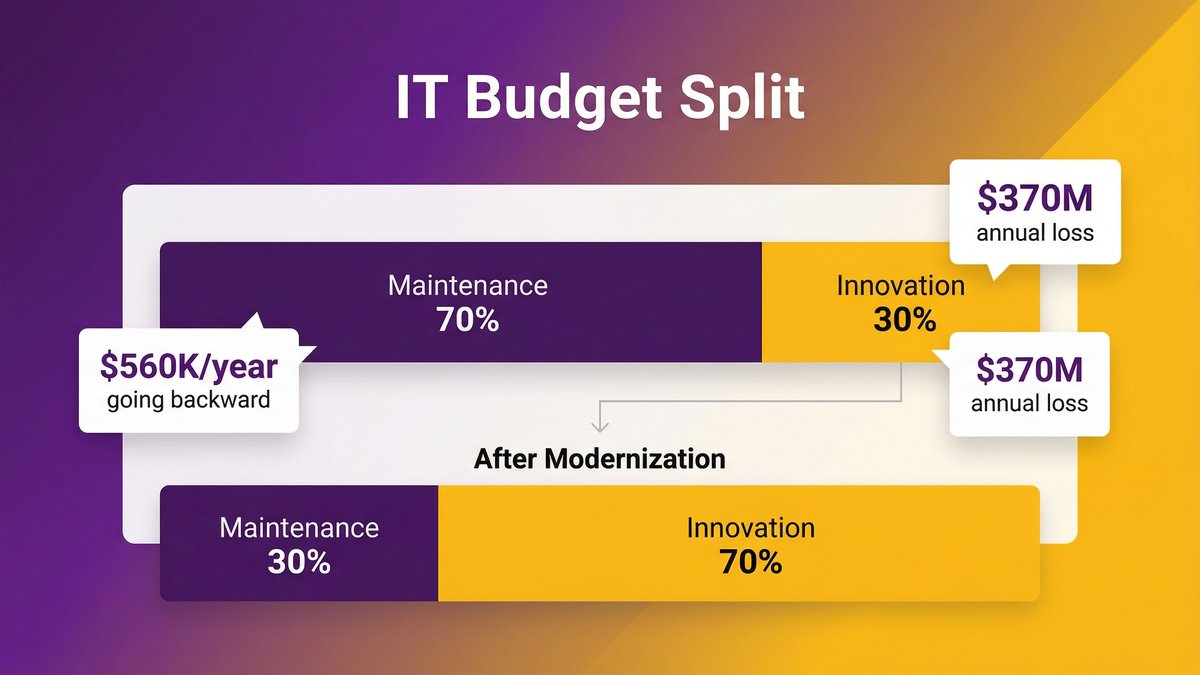
This is the number that reframes the whole conversation. According to Profound Logic (citing Mechanical Orchard research), organizations spend between 60–80% of their IT budgets on maintaining existing systems, leaving only 20–40% for innovation and growth initiatives.
Read that again. At 70% maintenance spend — the midpoint — roughly $0.70 of every dollar you invest in technology buys you zero competitive advantage. It keeps the current system from falling over.
The maintenance-to-innovation ratio: what the research shows
The 60–80% figure isn’t an outlier. It’s consistent across independent research. CIO Dive reports IT leaders spend an average 72% of their budgets on keep-the-lights-on functions. McKinsey finds that CIOs estimate that 10–20% of their technology budget dedicated to new products is diverted to resolving technical debt. William Flaiz, a digital transformation leader who ran technology at Novartis, described it this way: “60% of our IT budget was consumed by maintaining systems that supported less than 15% of business value. The math was undeniable: consolidation wasn’t just a smart strategy, it was financial survival.”
These aren’t edge cases. They describe the standard operating condition for a mid-market organization running systems built for an earlier version of the business.
Translating the ratio into a real dollar opportunity cost
Take your annual IT budget. Multiply it by 0.70. That number is what you’re spending on maintenance today.
Now imagine redirecting 20 percentage points of that — one dollar in seven — toward new capability instead. What’s the revenue value of the features you couldn’t ship last year? What’s the cost of the AI initiative that stalled because your data architecture couldn’t support it?
That’s not the cost of technical debt remediation. That’s the opportunity cost you’re currently absorbing. The argument to your CFO isn’t “we need to spend more on modernization.” It’s “we’re already spending the modernization budget — we’re just not getting the modernized system.”
How to Calculate What Technical Debt Is Costing Your Organization
The full cost of technical debt in a mid-market organization sits across four distinct categories. Most organizations only count the first. The CEOs who make the board case successfully count all four.
The four cost categories: direct maintenance, velocity tax, recruiting premium, and deferred revenue
1. Direct maintenance cost This is what your team reports directly: time spent on bug fixes, system patches, security updates, and infrastructure upkeep on legacy code. It’s the most visible category and consistently the most underestimated, because teams rarely track maintenance hours separately from product development hours.
2. Velocity tax Legacy codebases impose a multiplier on every development task. Features that take two days in a clean, modern system take ten days in a fragile legacy codebase with poor documentation and tight coupling across components. That difference — the “velocity tax” — accumulates over every sprint, every quarter, every year.
3. Recruiting premium Attracting senior engineers to work on outdated stacks costs a measurable premium in compensation. Some candidates decline entirely. The cost of extended recruiting cycles, higher compensation offers, and above-market contractor rates to compensate for the environment all belong in the technical debt ledger.
4. Deferred revenue This is the hardest category to quantify and the most strategically significant. Every product feature your team couldn’t ship on time because of legacy system constraints represents revenue you didn’t book. Every AI initiative that couldn’t move past pilot stage because your data architecture blocked it represents a future revenue stream you don’t yet have access to.
A simple CEO calculation framework: from IT spend to true annual cost
Run this calculation before your next board meeting:
Annual IT budget = $X
Maintenance ratio (use 65% as a conservative mid-market estimate if you don’t have your own number): $X × 0.65 = Direct maintenance proxy
Velocity tax (conservative estimate: add 30% to your delivery estimates as the time your team spends navigating legacy complexity rather than building): Development salary cost × 0.30
Recruiting premium (if you’ve had open engineering roles for more than 60 days, add $15,000–$25,000 per unfilled role per quarter)
Deferred revenue (identify one product initiative delayed by technical debt in the last 12 months; estimate the revenue it would have generated in its delayed period)
Add categories 1–4. That’s a real number. Not an engineering metric. A business cost.
As Cesar DOnofrio, CEO and co-founder of Making Sense, a digital transformation firm, describes it: “We see the ROI floor drop out when organizations spend 80% of their budget on bespoke middleware just to get fragmented systems to talk to each other. At that point, you aren’t investing in intelligence; you are paying a legacy tax to keep the lights on.”
The Business Evidence: What Happens When Organizations Let Debt Compound
Three cases. Each one shows a different dimension of what happens when technical debt isn’t treated as a business risk.
Knight Capital Group: $440M in 45 minutes
In August 2012, Knight Capital Group deployed a software update to its trading system. A piece of legacy code — dormant for years — got inadvertently reactivated during the deployment. In 45 minutes, the system executed $7 billion in unintended trades. The loss: $440 million. The company was sold within months.
The business failure wasn’t caused by bad strategy or market conditions. It was caused by undocumented legacy code that no one fully understood, in a system that had accumulated technical debt over a decade of patched deployments. One release, one forgotten flag, $440 million.
Southwest Airlines: $600M+ in operational debt made visible
In December 2022, Southwest Airlines canceled over 16,000 flights during a weather event that other airlines recovered from in days. Southwest’s crew scheduling system — built in the 1990s — couldn’t handle the rerouting at scale. The system’s logic for crew assignments couldn’t process the cascading changes fast enough to recover.
The result: $800 million in total costs, $140 million in compensation to passengers, a Department of Transportation investigation, and a CEO who spent months explaining the failure to Congress. None of the operational analyses pointed to bad weather as the root cause. It pointed to a system that hadn’t been modernized to handle the operational complexity the airline had grown into.
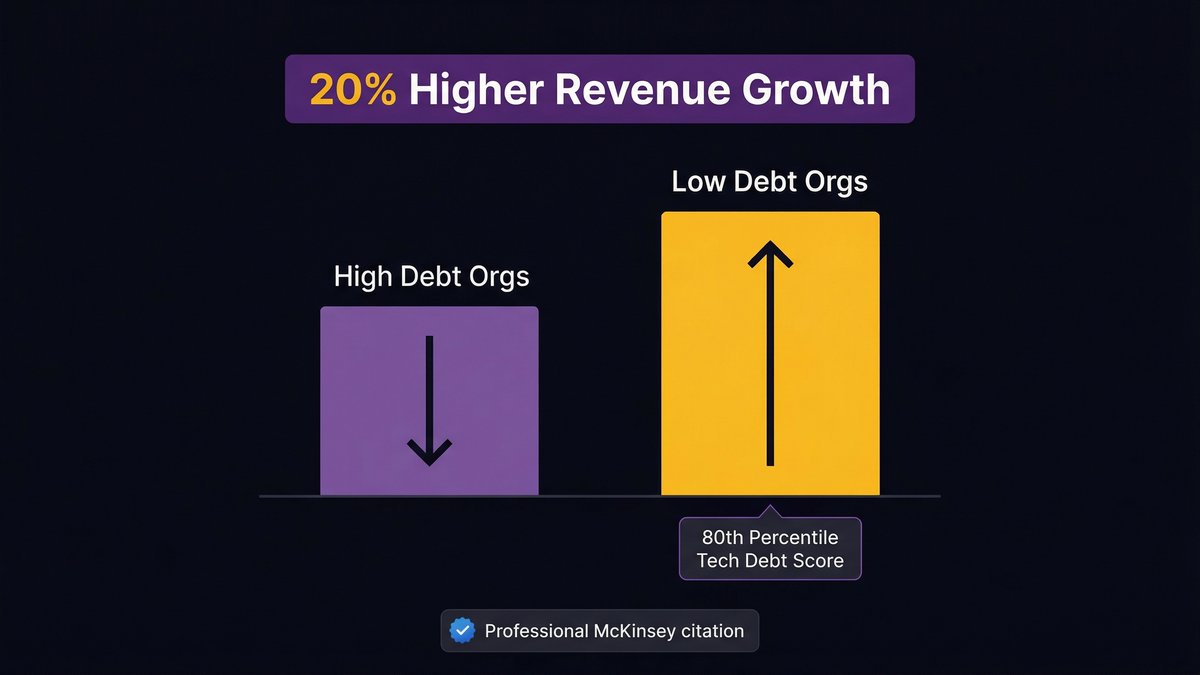
The McKinsey finding: 20% higher revenue growth for low-debt organizations
McKinsey’s analysis of 220 companies found that those in the 80th percentile for Tech Debt Score achieve 20% higher revenue growth than those in the bottom 20th percentile. This isn’t a correlation between “good companies manage debt better” — it’s a direct causal mechanism. Low-debt organizations ship features faster, integrate new capabilities more readily, and don’t have development capacity consumed by maintenance backlogs.
The revenue difference is the compounded velocity advantage over time. Every quarter a low-debt team ships two features while a high-debt team ships one is a quarter where the product gap widens.
Why Full Rewrites Fail — and What the ROI Data Says About the Alternative
Most CEOs who have tried to address technical debt have tried it the wrong way. They approved a full rewrite. It ran over budget, over time, and delivered a system that introduced new problems rather than solving the old ones. That failure is not random — it’s structural.
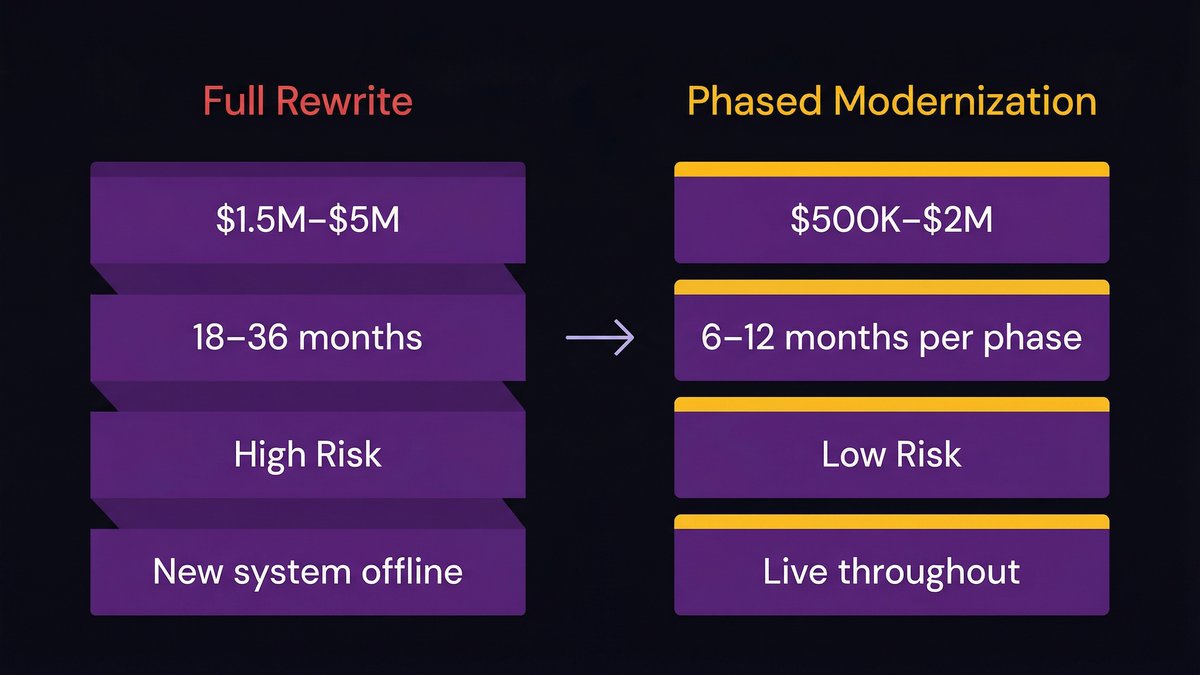
Rewrite risk: why “start over” projects run 36–48 months to positive ROI
Full rewrites fail for three predictable reasons:
First, they require two systems to run in parallel — the old system stays live while the new one is built, doubling operating cost and engineering complexity during the transition period.
Second, business requirements don’t freeze while the rewrite runs. By the time a 24-month rewrite completes, the requirements it was built against are 24 months out of date. Teams spend the last third of the project retrofitting a system they built against the wrong spec.
Third, the institutional knowledge embedded in the old system never fully transfers to the new one. Edge cases, undocumented business rules, and operational quirks that the old system handled correctly get missed. The new system breaks in production in ways the old system never did, because the old system had accumulated decades of patches specifically for those edge cases.
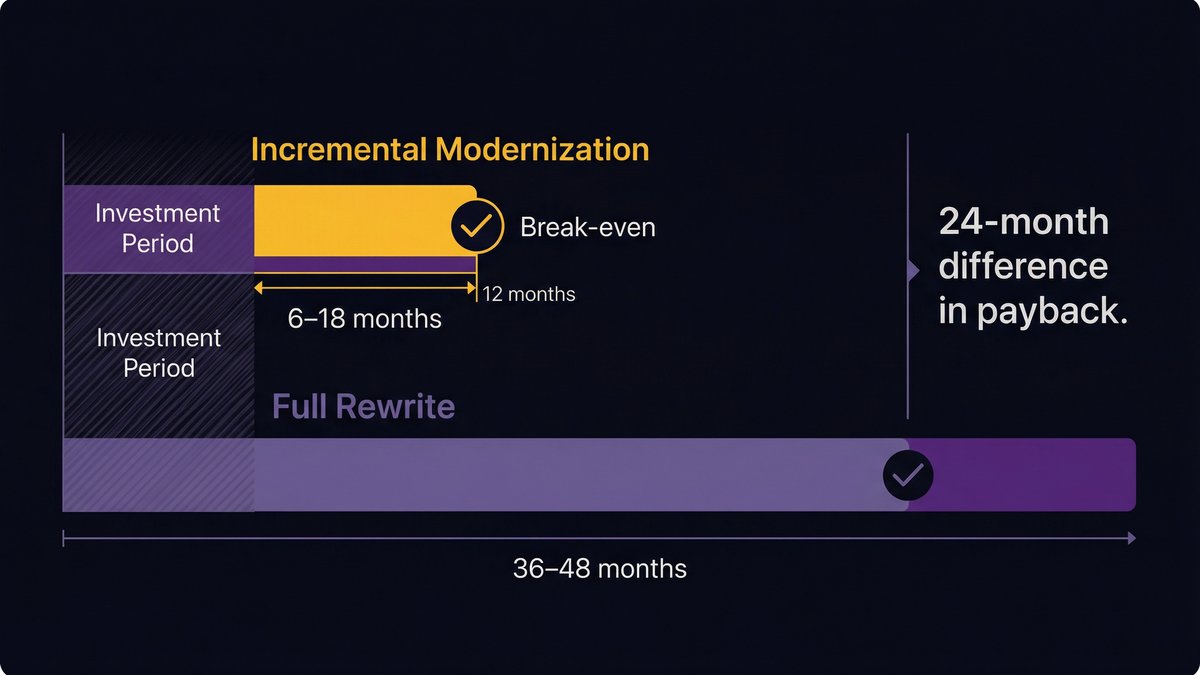
The result: a full rewrite with a 36–48 month path to positive ROI that frequently misses even that timeline.
“I have seen this approach fail at other companies,” one senior technology leader described in an engineering leadership forum, “where a 2-year project turns into a 4-year project, and they are stuck at 70% migrated for months while new requirements roll in.”
That’s not an edge case. It’s the standard failure mode.
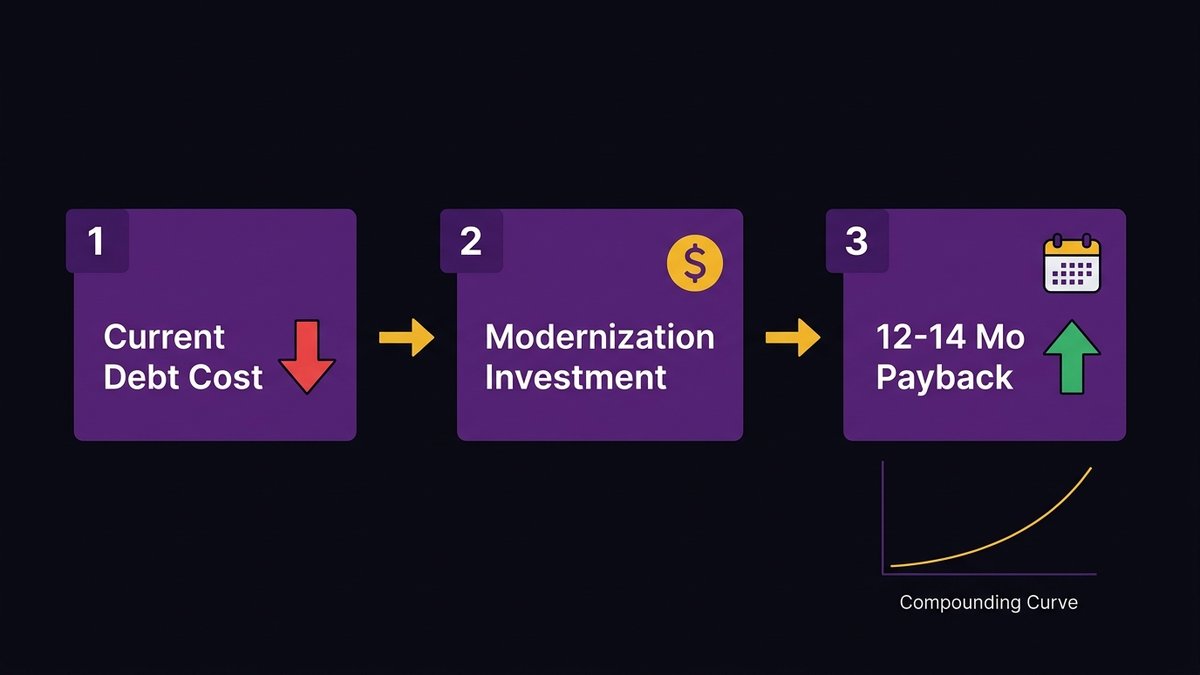
Incremental AI-augmented modernization: how the payback period drops to 12–14 months
The alternative isn’t “do nothing” versus “start over.” It’s incremental modernization — replacing the highest-cost, highest-risk components first, in production, without stopping the business.
According to UpdateCode.ai (2026), citing IBM and AWS research, legacy software modernization results in a 74% reduction in IT costs (IBM), a 66% reduction in infrastructure costs (AWS), and 43% faster time-to-market. Incremental AI-powered modernization delivers positive ROI in 12–14 months, compared with 36–48 months for traditional rewrite approaches.
The mechanism is different from a full rewrite. Incremental modernization: – Reduces maintenance costs in the modernized components immediately, without waiting for a full system replacement – Keeps the existing system live and revenue-generating throughout the process – Uses AI-augmented development tooling to accelerate the work — analyzing the legacy codebase, generating migration plans, writing and testing replacement components with significantly less manual effort – Produces documented, owned components at each phase rather than waiting for a three-year completion to transfer any knowledge
The payback math changes because the cost reduction starts in month one, not month 36.
The Compounding Return: How Modernization Unlocks AI Readiness
Here’s the dimension most financial models miss. The ROI of technical debt remediation isn’t just cost reduction. It’s the unlocking of revenue layers that your current architecture makes completely inaccessible.
Why legacy systems block AI integration at the architectural level
AI systems — whether predictive models, intelligent automation, or agentic workflows — have specific infrastructure requirements. They need real-time or near-real-time data access. They need API-first interfaces that can receive and return structured requests. They need modular, loosely coupled architectures so that an AI component can integrate without requiring a full system rebuild around it.
Legacy systems fail all three requirements by design. They were built for a different integration model — batch processing, file transfers, tightly coupled modules that assume the only thing interacting with the system is a human sitting at a screen.
According to IBM’s Institute for Business Value (November 2025), technical debt can cut AI ROI by 18% to 29% if ignored — even in high-potential projects. Organizations that factor in remediation costs when building AI use cases project ROI that is 29% higher than those that don’t.
So the choice isn’t just “pay for modernization or don’t.” It’s “pay for modernization and access AI revenue, or skip modernization and watch 18–29% of your AI investment evaporate.”
The additional revenue layers that only modernized systems can access
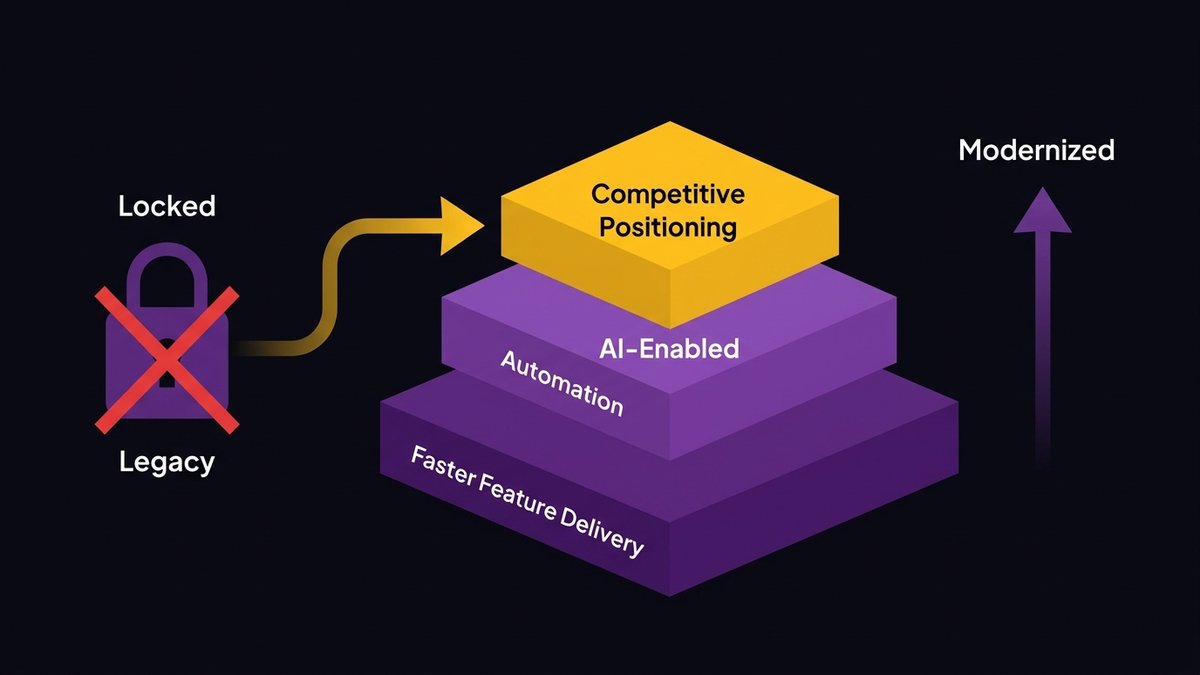
Three specific revenue categories open up when a legacy system gets modernized:
Faster feature delivery. Clean, documented, modular codebases ship features in days that legacy systems ship in weeks. That velocity difference compounds quarterly. A team that ships 40 features per year versus 15 builds a meaningfully different product.
AI-enabled automation. Workflow automation, intelligent data processing, and natural language interfaces all become available as implementation options once the architecture can support them. These aren’t speculative future benefits — they’re active capabilities competitors are deploying right now against customers who still share an operations stack with a system built in 2008.
Competitive positioning. As Skylar Roebuck, CTO of Solvd, an AI-first advisory firm, states: “Traditional modernization tends to over-index on protecting how things work today rather than building for what’s next. AI capability is compounding rapidly, and the real risk for mid-market companies is delay.”
That compounding dynamic means the gap between modernized and non-modernized organizations doesn’t hold steady. It widens.
What a Technical Debt Remediation Engagement Actually Looks Like
Before a CEO approves a modernization budget, they need to understand what they’re buying. Transparency about process is a precondition for trust — and most firms skip this part.
The diagnostic phase: quantifying debt before committing to a roadmap
The first step in any credible modernization engagement is a systems assessment. Not an engineering audit that produces a 200-page technical report. A CEO-readable diagnosis of:
Which components carry the highest maintenance cost and represent the greatest delivery drag
Where the architecture fails against AI-readiness requirements
Which legacy components can be incrementally replaced, versus which need architectural rethinking
What a phased roadmap looks like — in months to first ROI, not years to theoretical completion
A well-run diagnostic takes 2–4 weeks and produces a business case, not a code review. The output is a cost-versus-return model your CFO can evaluate, with a phased roadmap your CTO can defend.
The diagnostic phase exists for one reason: so that both parties understand what they’re committing to before the commitment is made.
Documentation transfer: why this is the risk control mechanism most firms skip
Every CEO who has worked with a development vendor has a version of the same story. The vendor delivered working software. The vendor left. Three months later, nobody can explain how a critical piece of the system works, and making a change requires calling the vendor back at consultant rates.
Documentation transfer isn’t a nice-to-have. It’s the mechanism that determines whether you own your system or whether you’re renting access to it.
A properly structured modernization engagement transfers the following to the client at project completion, unconditionally: UML architecture diagrams, system design documents, API references, test coverage reports, and architecture decision records explaining why key choices were made — not just what was built.
That documentation doesn’t just protect you from vendor dependency. It reduces onboarding time for new engineers, makes future iterations faster and less expensive, and serves as the foundation for AI integration when the architecture is ready to support it.
This is what makes the modernization ROI calculation permanent rather than one-time: you own the output. The cost savings compound forward because the system you own is documented, clean, and yours.
Building the ROI Case for Your Board
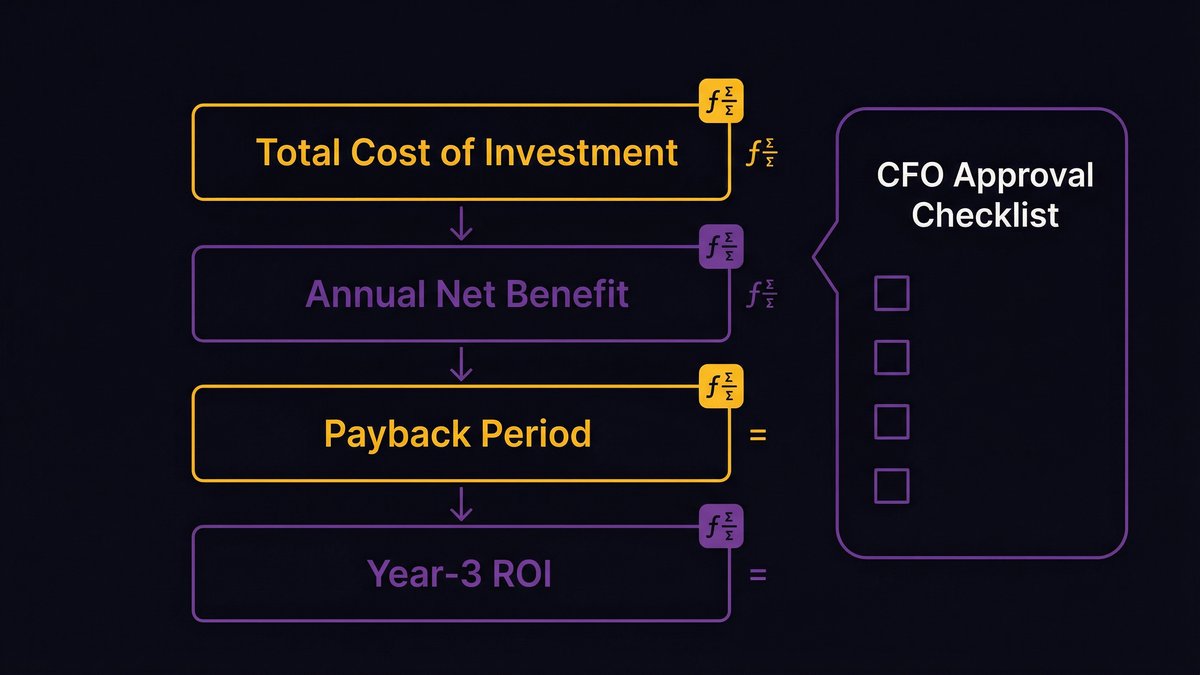
You’ve done the diagnosis. You understand the cost. Now you need to get the budget approved. The board presentation has three numbers, and they need to be stated in the right sequence.
The three numbers every board presentation needs
Number 1: Current annual cost of technical debt Use the four-category framework from the calculation section above. Add direct maintenance proxy, velocity tax, recruiting premium, and deferred revenue estimate. This is the status quo cost — what continuing to do nothing costs per year in hard and soft terms.
Number 2: Modernization investment This is the engagement cost for the recommended approach — specifically, the incremental AI-augmented path, not a full rewrite. Scoped as a phased roadmap with clear deliverables per phase.
Number 3: Payback period and compounding return Based on the UpdateCode.ai research: 12–14 months to positive ROI for incremental AI-augmented modernization. After the payback period, the cost reduction compounds. The AI-readiness unlock adds a revenue layer with its own return calculation.
The board argument writes itself: “We are currently spending $X per year on the cost of maintaining a system we no longer control. The alternative is a $Y investment that returns positive ROI in 12–14 months and eliminates the maintenance drag permanently. We are not being asked to spend more on technology. We are being asked to redirect an existing cost into an investment that pays for itself.”
How to frame the modernization investment against the current maintenance spend
The single most effective reframe for a board audience: don’t present modernization as an additional expenditure. Present it as a reallocation of the maintenance budget you’re already spending.
If your IT budget is $5 million and 65% goes to maintenance, you’re already spending $3.25 million per year to maintain a system that’s limiting your growth. A modernization engagement that costs $1.5 million over 18 months and redirects that maintenance spend toward new capability isn’t an expense increase. It’s a budget reallocation with a 12–14-month payback and a permanent reduction in the annual maintenance cost line.
The argument isn’t “invest in technology.” It’s “stop getting charged for a system you’ll never get.”
If you want to run the diagnostic before building your board case, start with atechnical debt assessment.
Ready to build your board case? Nexa Devs runs a technical debt diagnostic that produces a CEO-readable cost model and phased modernization roadmap, before you commit to anything. Book a diagnostic conversation
FAQ
What is the KPI for technical debt, and how do I present it to a CFO?
The most effective KPI for a CFO is maintenance spend as a percentage of total IT budget. If that number exceeds 60%, you have a quantifiable problem. Pair it with delivery velocity data and a deferred revenue estimate for one initiative blocked by technical debt to frame it as a business cost, not a development problem.
How do I calculate the ROI of paying down technical debt?
Use four cost categories: direct maintenance spend, velocity tax on engineering capacity, recruiting premium for legacy stack talent, and deferred revenue from delayed features. Add those figures to get your annual debt cost. Compare against modernization investment and a 12–14 month payback period benchmark for incremental AI-augmented approaches.
Why does technical debt block AI adoption?
AI systems need real-time data access, API-first interfaces, and modular architecture — three properties legacy systems lack. According to IBM’s Institute for Business Value, technical debt can reduce AI ROI by 18–29% even in high-priority projects. Legacy architecture built for batch processing can’t support AI integration without significant rearchitecting.
What is the difference between incremental modernization and a full rewrite?
A full rewrite replaces the entire system from scratch over 24–48 months. Incremental modernization replaces the highest-cost components first without stopping the existing system. Full rewrites take 36–48 months to positive ROI; incremental AI-augmented modernization reaches it in 12–14 months, with lower business risk throughout.
How much of our IT budget should go to new development versus maintenance?
Leading firms allocate approximately 15% of IT budgets to proactive debt remediation. A healthy allocation runs roughly 40–60% maintenance, 40–60% innovation. Mid-market organizations with legacy systems often run at 65–80% maintenance,
well outside that range. The goal is to reduce maintenance cost per IT dollar over time, not to hit a fixed ratio.
The Tacit Knowledge Time Bomb: Why Your Most Important Software Knowledge Can’t Be Written Down
You’ve probably run the documentation initiative. Maybe twice. You told the team to write everything down: the architecture, the decisions, the edge cases. Six months later, you had a wiki that was already out of date and a codebase that was just as opaque as before.
That’s not a discipline problem. It’s a structural one. And the consequences, for your systems, your vendor relationships, and your business continuity, are more serious than most CEOs and COOs recognize until something breaks.
Institutional knowledge loss in software development happens when the people who understand how a system works leave before that understanding transfers. It’s the senior engineer who “just knows” why the billing module can’t run before 2 AM. It’s the vendor team that built your platform over four years and never wrote down a single architectural decision. It’s the system that works until someone leaves, and then it doesn’t.
The tacit knowledge time bomb is already ticking in most mid-market organizations. This guide explains why, and what the structural fix actually looks like.
The 90/10 Problem: Why Most of What Your Software Team Knows Is Invisible
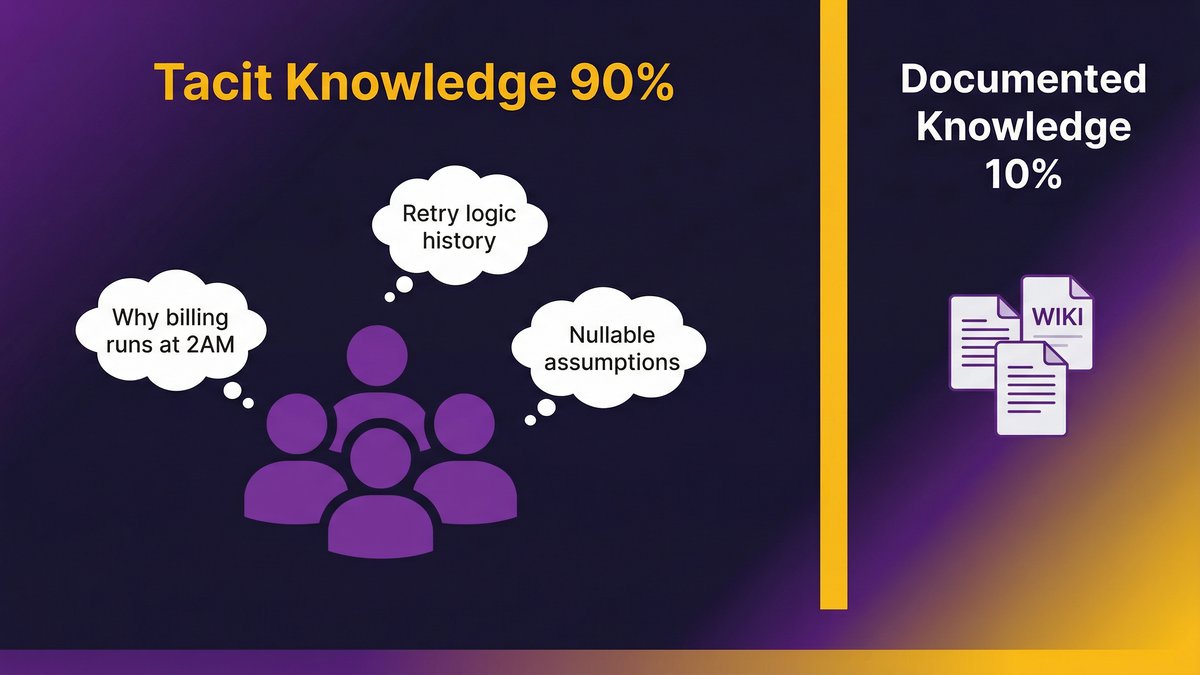
Most of what your engineering team knows about your software cannot be written down. Full stop.
According to docs.bswen.com (2026), tacit knowledge comprises approximately 90% of organizational knowledge. Documented knowledge, the wikis, runbooks, architecture diagrams, and code comments, represent only 10%. And that 10% is rarely up to date.
That asymmetry is the core problem. Every documentation initiative your organization has run has tried to close a 90/10 gap with a strategy designed for 10% of the knowledge. It was never going to work.
Explicit vs. tacit knowledge in software systems
Explicit knowledge is what you can write down: API contracts, database schemas, deployment scripts, and user story libraries. It transfers cleanly. A new engineer can read it and act on it.
Tacit knowledge is everything else. It’s the reasoning behind architectural decisions that were never recorded. It’s knowing which database columns are technically nullable but functionally never null because three integrations depend on that assumption. It’s the production incident from two years ago that shaped how the team now thinks about retry logic, an incident that probably isn’t in your Jira backlog anymore.
No wiki captures that. No AI summarizer can reconstruct it from the codebase alone. It lives with specific people.
Why documentation initiatives consistently fail to close the gap
The failure pattern is predictable. Engineers are busy. Writing documentation isn’t shipping features. The initiative runs for a quarter, the wiki gets seeded, and then it slowly drifts from reality as the system evolves, and no one has time to maintain it.
There’s also a deeper problem: most tacit knowledge can’t be articulated even by the person who holds it. Ask a senior engineer why they built something a certain way, and they’ll say “it just felt right” or “I tried the other approach, and it broke something.” The reasoning is real. It’s just not in a form that can be extracted and stored.
Developers spend approximately 60% of their time understanding legacy code and only 5% writing new code. That number isn’t a productivity failure. It’s the cost of tacit knowledge concentration, knowledge that was never transferred and now has to be reverse-engineered every time someone new touches the system.
The Bus Factor Is a Business Continuity Problem, Not an Engineering Problem
The bus factor measures how many people in your organization would need to be hit by a bus, quit, get poached, or burn out before a critical project collapses. A bus factor of one means a single person’s departure would leave you with a system nobody understands.
Most mid-market teams have a bus factor of one or two. This is not a theoretical concern.
What your bus factor actually measures, and how to assess yours
Your bus factor is effectively your concentration of tacit knowledge risk. It answers: “How few people currently hold the understanding this system needs to keep functioning?”
A bus factor of one means you have a single point of failure in a system that your business depends on. A bus factor of two is better, but not by much. According to LinuxSecurity.com (2026), citing JetBrains Bus Factor Explorer March 2026 data, MySQL, PostgreSQL, and SQLite all have a bus factor of two, meaning only two contributors understand the full codebase. For critical infrastructure, a bus factor below five is considered high risk.
To assess your own: list your three most critical software systems. For each one, ask how many people could explain its full operational behavior, not just the API surface but the deployment dependencies, the historical quirks, the undocumented assumptions. If the answer for any system is two or fewer, you have a live continuity risk.
Real business impact: project delays, cost of replacement, and system fragility
When a high bus-factor person leaves, the cost isn’t just the salary. According to ClearlyAcquired (2026), replacing high-level technical talent can cost 150–400% of their salary and delay projects by 6–12 months when knowledge hasn’t been transferred, with new hires requiring 16–20 weeks to reach full productivity.
For a senior engineer earning $130,000, the replacement cost ranges from $195,000 to $520,000. Before they’ve shipped a line of code.
The disruption isn’t linear either. Knowledge loss compounds. A key person exits. Their replacement spends months reverse-engineering what was obvious to their predecessor. They make conservative choices, touching as little as possible, which means features slow down and technical debt accumulates. The system gets more fragile because the person maintaining it is operating partially blind.
When Your Vendor Holds the Knowledge: The Hidden Risk in Software Outsourcing
Here’s what most CEOs and COOs don’t account for: the bus factor problem isn’t limited to your internal team. It applies to every vendor relationship you have.
If a software vendor has been building and maintaining your platform for three years, they hold most of the tacit knowledge about how that system actually works. Your internal team has been involved, but they probably can’t explain the data flow across modules, the rationale behind the infrastructure choices, or what would break if you needed to migrate to a different hosting provider.
You may legally own the code. You don’t practically control the system.
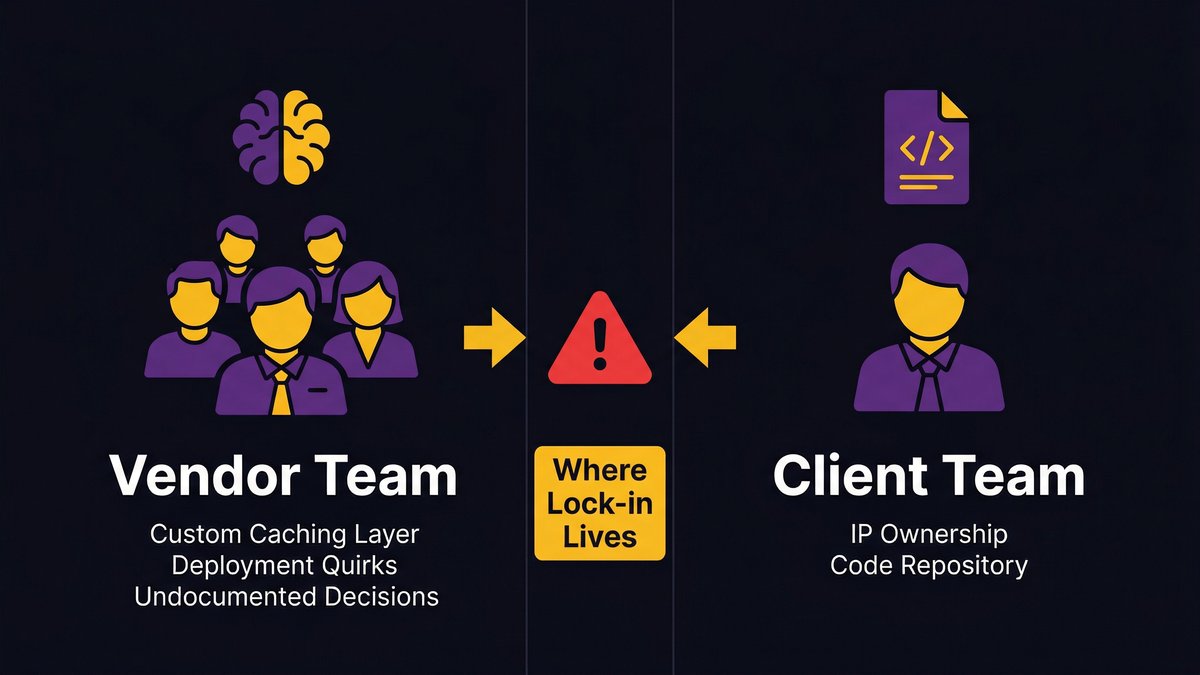
The difference between owning code and controlling a system
Legal code ownership and operational control are not the same thing. According to Pragmatic Coders, “You can own the code’s copyright and still be locked in. Formal ownership isn’t the same as practical control over the product. Many companies formally own the IP but lack real, operational control over their product. The gap between formal ownership and practical control is where lock-in lives.”
That gap is the tacit knowledge gap. It’s not in your IP agreement. It’s a fact that only three people at your vendor understand the custom caching layer they built, and none of them are on your payroll.
How knowledge concentration at the vendor level creates dependency, even with IP ownership clauses
This form of lock-in is more durable than technical lock-in. You can migrate off a proprietary database. You can’t easily reconstruct four years of undocumented architectural decisions.
Consider what happens when you need to switch vendors or bring development in-house. Your new team inherits a codebase with no Architecture Decision Records, no documented deployment runbook, and a handful of modules that nobody outside the original vendor team has ever touched. The onboarding takes months. The first sprint is mostly archaeology. The first production incident exposes something nobody knew was there.
Fortune 500 companies lose $31.5 billion annually due to the failure to share information. A significant portion of that loss lives in the vendor handover gap, the institutional knowledge that is transferred contractually but not practically.
What Vendor Transition Failure Actually Looks Like
Vendor transitions don’t usually fail at the handover. They fail six months later.
The handover meeting went fine. Code is transferred. Documentation is delivered, typically including a README, some API specs, and any architecture diagrams the vendor can produce in the final sprint. Everyone shakes hands. Then the new team starts working.
Documentation gaps, undocumented dependencies, and lost configuration details
According to Dreamix, inadequate knowledge transfer is one of the most common causes of transition failure: “Documentation gaps, undocumented dependencies, and lost configuration details create expensive problems months after transition completion.”
The new team doesn’t know what they don’t know. They discover the undocumented dependency when a scheduled job fails on the first of the month. They find the missing configuration detail when they deploy to staging, and everything breaks in a way that looks random. The lost architectural decision surfaces when they try to add a feature, and the code structure actively resists the change.
Each discovery costs time. The compounding effect is that the new team loses confidence in the system and starts making changes conservatively, which slows velocity further and accumulates more technical debt.
Why do transition failures emerge months after the handover, not at the handover?
There’s a delay built into the failure pattern. Most systems have seasonal or periodic behavior, month-end batch jobs, quarterly reports, and annual audit exports. The new team won’t encounter those pathways until the calendar triggers them. When they do, they’re operating without the tacit knowledge that the original team used to handle them.
This is why the immediate post-handover period looks fine. The system runs. The obvious features work. The new team reports no critical issues. Three months later, the first month-end cycle runs, and suddenly there’s a production incident nobody can explain.
The Structural Solution: Building Systems That Outlive the People Who Built Them
Documentation initiatives fail because they’re retrofitted onto a delivery process that doesn’t naturally produce documentation. The fix isn’t discipline, it’s structure.
A delivery process that systematically captures tacit knowledge doesn’t ask engineers to write documentation after the fact. It builds documentation into every decision as it’s made. The output is a system that any competent engineer can understand, maintain, and evolve, regardless of whether the original builders are still involved.
Three mechanisms make this work in practice.
Architecture Decision Records (ADRs): documenting the ‘why’, not just the ‘what.’
An Architecture Decision Record is a short document that captures one architectural decision: what was chosen, what alternatives were considered, and why the chosen approach was taken. Not the code, the reasoning.
ADRs are the closest thing to capturing tacit knowledge that exists in practical software engineering. They don’t capture everything. But they capture the most important decisions, the ones that shaped the system’s structure, the tradeoffs that were deliberately accepted, the paths that were explored and rejected.
A system with complete ADRs is fundamentally more transferable than one without them. A new team can read the ADR for why the caching layer works the way it does and understand the constraints the original team was operating under. Without that record, they’re guessing.
ADRs should be written at decision time, not retroactively. Retroactive ADRs are reconstructions; they capture what was decided, but not the actual reasoning, which is already partially lost.
AI-assisted documentation: how modern tooling closes the tacit knowledge gap at scale
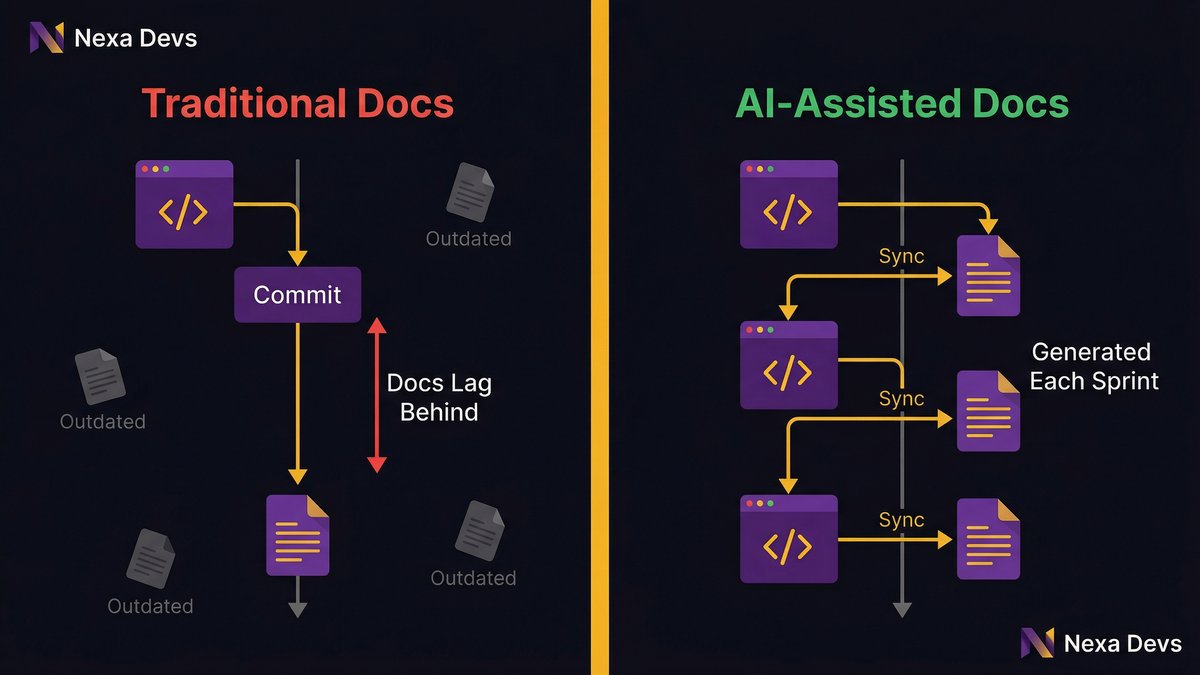
AI tooling has changed what’s possible in documentation. Modern AI-assisted development workflows can generate documentation artifacts continuously, user stories, API references, deployment runbooks, and test coverage summaries as part of the delivery process rather than as a separate phase.
This matters because the traditional documentation problem was a time-and-incentive problem: engineers needed time they didn’t have and had no strong incentive to spend it on documentation. AI-assisted tooling eliminates the time cost. Documentation that previously took a senior engineer half a day to produce can be generated, reviewed, and committed in minutes.
The result is documentation that stays current because it’s generated alongside the code rather than written separately.
Unconditional documentation transfer: what it means in practice
Unconditional documentation transfer means every documentation artifact produced during the engagement is transferred to the client at project close, regardless of whether the engagement continues. Not licensed. Not accessible via the vendor’s portal. Owned by the client.
This is different from standard practice. Most vendors deliver code and a README. The internal project knowledge, the sprint history, the architectural decisions, the test coverage reports, and the system design documents typically stay with the vendor or get lost in the transition.
Unconditional transfer means you end the engagement with the documentation you’d want if you were hiring a new engineering team tomorrow. Because you might be.
Knowledge Sovereignty: What You Should Own Beyond the Code
Knowledge sovereignty is the condition where you, not your vendor, hold practical control over your system. You own the code legally. You also understand it operationally. Your team can maintain it, evolve it, and explain it to a new vendor without the original builders in the room.
Most organizations that believe they have knowledge sovereignty don’t. They have code ownership. It’s not the same thing.
Practical control vs. legal ownership, the gap where lock-in lives
The legal contract says you own the IP. But do your internal team members understand the system’s deployment architecture? Do they know what would break if you changed your hosting provider? Can they explain the data flow between the modules your vendor built?
If the answer is no, your knowledge sovereignty is nominal. Your practical dependency on the vendor is real, and that dependency doesn’t expire when the contract does.
The gap between legal ownership and practical control is exactly where vendor lock-in lives. It’s invisible in the contract. It’s very visible when you need to switch vendors.
A checklist: what a knowledge-sovereign software engagement looks like
Before you sign or renew a software development engagement, verify:
Architecture Decision Records: Does the vendor produce ADRs as a standard deliverable? Are they committed to the codebase, or are they stored somewhere the client owns?
Unconditional documentation transfer: Is every documentation artifact transferred at project close, regardless of engagement continuity?
System design documents, UML architecture diagrams, data flow diagrams, and integration maps- are these client-owned deliverables or internal vendor artifacts?
Onboarding independence, could a competent external engineer onboard to this system using the documentation alone, without calling the vendor?
Deployment runbook: Is there a documented, tested process for deploying, rolling back, and diagnosing production issues?
No undocumented dependencies. Are all external integrations, credentials, and configuration dependencies documented in a format the client controls?
A vendor that can’t answer yes to all six items is concentrating on knowledge they should be transferring. That concentration is a risk you’re carrying.
What 10+ Years of Embedded Partnership Actually Produces
There’s a structural difference between a project-based vendor relationship and a long-term embedded partnership. The difference isn’t just tenure. It’s a knowledge direction.
In a project-based engagement, the vendor accumulates knowledge about your system and takes it with them when the project ends. Your organization ends the engagement with the code and a documentation gap. The vendor ends it with an institutional understanding that they can apply elsewhere.
In a long-term embedded partnership, knowledge flows in both directions.
How long-term embedded relationships structurally prevent knowledge concentration
A vendor team that has worked with your organization for eight or ten years understands your system the way an internal team would, but with the documentation discipline that internal teams rarely maintain. They know the history. They’ve built the ADRs. They’ve seen the system evolve through four major initiatives and know why the architecture looks the way it does.
Critically, they have a structural incentive to keep that knowledge transferable. If the engagement is ongoing and the client can credibly switch vendors, the embedded team knows the documentation needs to be good enough that a replacement team could take over. That incentive doesn’t exist in a project-based relationship where the vendor exists at launch.
Nexa’s longest client relationships, UCLA David Geffen School of Medicine (10+ years), TSB (8+ years), Townsend (5+ years), are not retained because of price or proximity. They’re retained because the accumulated system knowledge, maintained in transferable form, creates genuine value that compounds over time.
The compounding knowledge advantage: clients accumulate, not depend
Every year of an embedded partnership where documentation is maintained as a deliverable, the client’s knowledge position improves. The ADR library grows. The system design documents stay current. The onboarding materials reflect the current state of the system.
A client who could not have replaced their vendor three years ago can now. Not because the vendor got easier to replace, but because the knowledge was deliberately kept in client-owned form throughout the relationship.
That’s the structural opposite of knowledge lock-in. It’s also the condition that makes a long-term embedded partnership genuinely different from a recurring project-based dependency.
If you’re evaluating your current vendor relationship and want to understand where your knowledge position actually sits, start with an architecture assessment. That conversation will surface what your team actually controls versus what it only legally owns.
The Knowledge You Don’t Own Is a Risk You’re Carrying
Your software systems are assets. The knowledge required to maintain them is also an asset. The question is who holds it.
If the answer is “a few specific people”, internal or vendor, you’re exposed. That exposure compounds every quarter. The knowledge gets more concentrated, the system gets less documented, and your practical dependency on those few people grows.
The structural fix starts with demanding transferable knowledge as a deliverable, not a byproduct. ADRs as standard output. Documentation that’s generated alongside code, not retrofitted after. Unconditional transfer at project close.
That’s not a new vendor category. It’s a different standard, one you can write into your next engagement.
Want to understand where your current knowledge position actually sits? Reach out to Nexa Devs for a no-cost architecture assessment. We’ll tell you what your team actually controls.
FAQ
What does loss of institutional knowledge mean?
Loss of institutional knowledge means that when key people leave, they take understanding that was never documented or transferred. In software development, this makes systems that work become systems nobody fully understands, raising maintenance costs and increasing vendor dependency.
What is the impact when institutional knowledge of IT processes is not captured and recorded?
When IT process knowledge isn’t captured, organizations face longer onboarding times, higher error rates during changes, and growing vendor dependency. Developers spend roughly 60% of their time understanding legacy code rather than building new capabilities (CAST Software).
What are key person dependencies?
A key person dependency exists when one individual holds critical knowledge that no one else has. In software teams, this is typically a senior engineer whose departure would stall the project until knowledge is reconstructed, at significant time and cost.
What is the bus factor in business?
The bus factor is the number of people who would need to leave before a critical project collapses. A bus factor of one means one departure causes a crisis. Even major databases like MySQL and PostgreSQL have a bus factor of two, meaning only two contributors hold a full system understanding (LinuxSecurity.com, 2026).
How can we reduce the bus factor?
Reduce bus factor through pair programming, code reviews, Architecture Decision Records, and cross-training. For vendor relationships, require unconditional documentation transfer as a contract term. The goal is to ensure no single person’s departure leaves any system unmanageable.
What are the 4 C’s of knowledge management?
The 4 C’s are Capture, Curate, Connect, and Communicate. In software: Capture means producing ADRs and system design documents during delivery. Curate keeps them current. Connect the links’ knowledge to the systems it describes. Communicating makes it accessible to any engineer who needs it.
Your CTO bought the AI tools. Your team ran the pilot. It didn’t work, or it worked in a sandbox and collapsed the moment you tried to connect it to anything real. So you hired a consultant, who told you to “modernize your data layer” before going further. Two months later, you’re no closer to AI capability, and the budget is gone.
This isn’t a procurement problem. It’s not a talent problem. It’s an architecture problem. And most organizations don’t find out until they’ve already spent the money.
Legacy system AI integration fails for a specific, diagnosable reason: legacy systems weren’t built to support AI workloads, and bolting AI onto them doesn’t change their underlying structure. Before you spend another dollar on AI tooling, you need to understand exactly what’s blocking you, and what it actually takes to remove that block.
Why Your Legacy System Isn’t Just Slow, It’s AI-Proof
A legacy system isn’t hard to integrate with AI; it’s structurally incompatible with AI. That’s a different problem, and it requires a different solution.
Most organizations discover this distinction the hard way. They assume legacy integration is a plumbing problem: connect system A to system B, configure an API, ship it. What they find instead is that the system can’t be connected to anything without significant structural work, because it was never designed to be.
The structural difference between ‘hard to integrate’ and ‘architecturally incompatible.’
A system that’s hard to integrate has APIs, but they’re poorly documented or inconsistently implemented. A system that’s architecturally incompatible with AI has no meaningful API surface at all. Business logic is embedded in the database layer, in stored procedures, in ETL jobs that run overnight and can’t be queried in real time. The system’s data model reflects a decade-old understanding of the business, and no one fully knows how it works anymore.
AI systems need clean, accessible, real-time data. They need APIs that can receive requests and return structured responses. They need infrastructure that can scale to support inference workloads. Legacy systems were built to do none of these things.
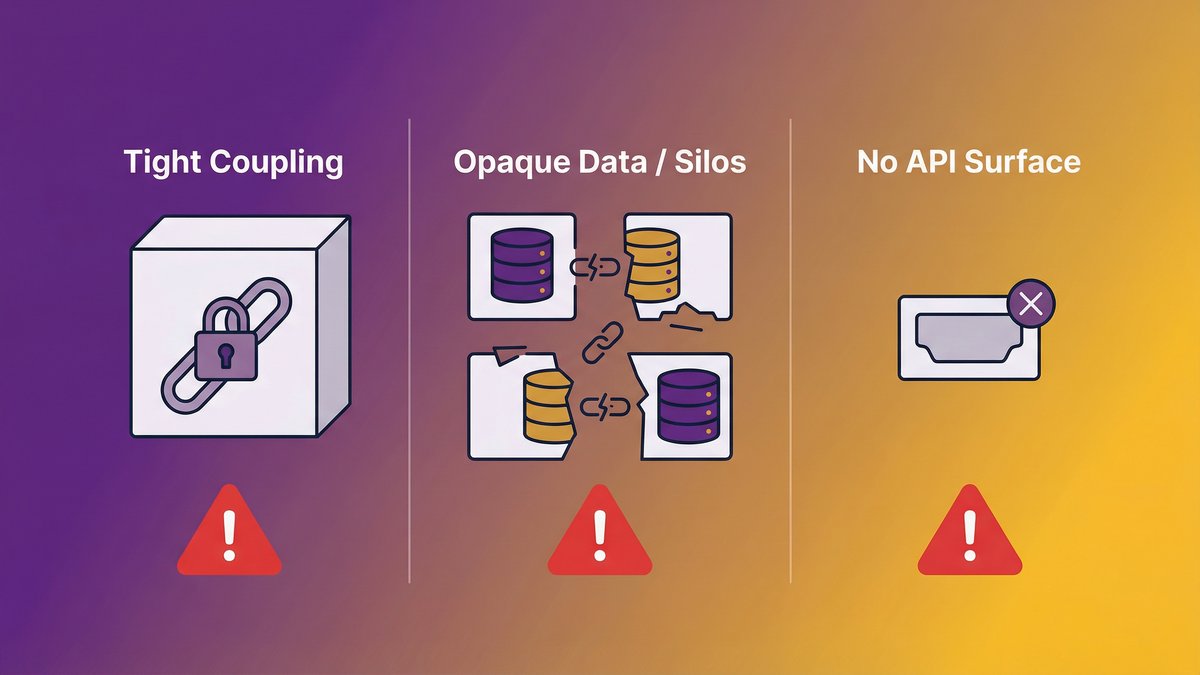
What makes a system AI-proof: monolithic coupling, opaque data, and absent APIs
Three structural properties make a system AI-proof:
Tight coupling. Monolithic architectures bind business logic, presentation, and data into a single unit. You can’t change one part without affecting the others. Adding AI requires inserting new logic at specific points in the system, but when everything is coupled together, there are no clean insertion points.
Opaque data. Legacy systems often store data in formats that made sense in the 1990s: denormalized tables, proprietary binary formats, and undocumented field encodings. The data exists, but it can’t be extracted, cleaned, or used without significant transformation work. AI models need consistent, well-structured data to produce reliable outputs. Legacy data is rarely consistent or well-structured.
Absent APIs. If your system has no API layer, external services, including AI, can’t interact with it. You can’t send a request, you can’t receive a response, and you can’t integrate without building an API layer from scratch. That’s not an integration task. That’s a modernization task.
The Business Cost of Running AI on a Broken Foundation
Forcing AI onto a legacy infrastructure doesn’t deliver AI capability. It delivers failed pilots, wasted licenses, and a team that stops believing AI is worth trying.
This is where the CEO’s perspective matters most. You’re not evaluating architecture diagrams; you’re evaluating whether this investment is going to produce results. And right now, for most mid-market organizations, it isn’t. Not because AI doesn’t work, but because the foundation it’s running on was never designed to support it.
What happens when you force AI onto legacy infrastructure
The pattern is consistent. An organization buys an AI tool or builds a pilot. It works in isolation, in a clean dataset, in a sandbox environment, disconnected from production systems. The moment the team tries to connect it to the real system, the integration breaks. Data is missing or wrong. The system can’t handle the additional query load. Business logic that was assumed to be captured in the data turns out to be scattered across five different tables and three stored procedures.
The pilot gets shelved. The vendor relationship sours. The engineering team spends three months debugging the integration instead of building a new capability. You’re back where you started, but now you’ve spent the budget.
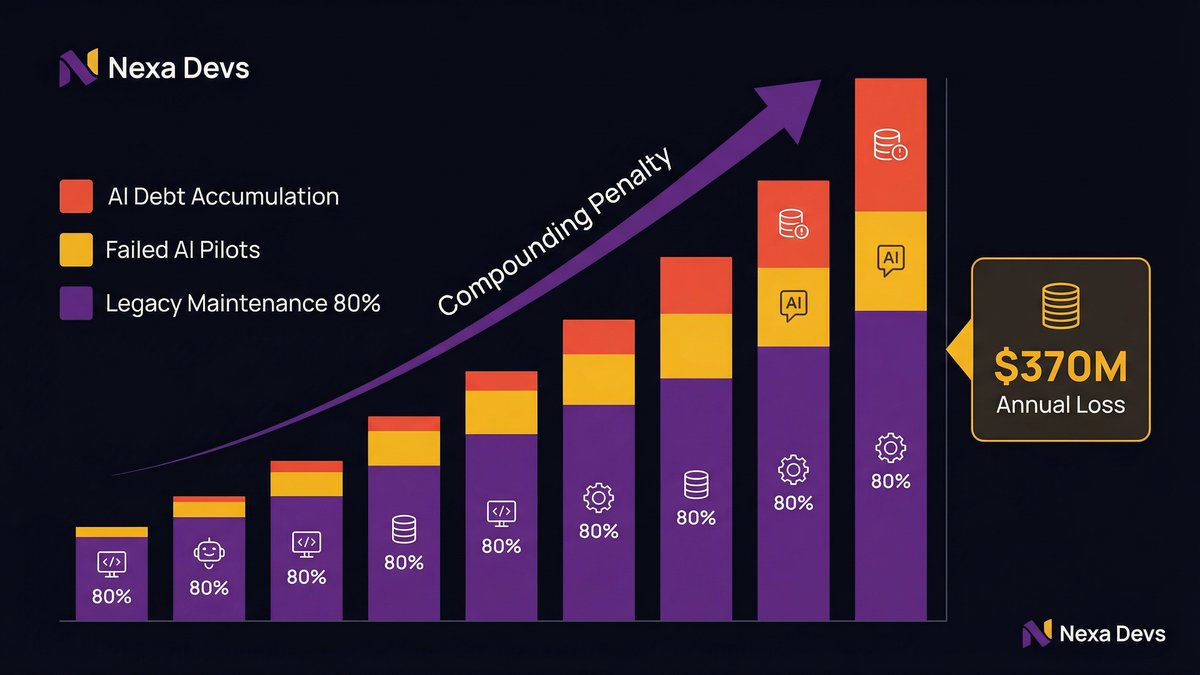
According to ncube.com, citing 2025–2026 data from Deloitte, Gartner, and McKinsey, legacy-heavy organizations spend up to 80% of their IT budgets on maintenance and support, leaving just 20% for innovation. When 80% of your budget is keeping the lights on, there’s very little left to fund the transformation work AI actually requires.
The compounding penalty: technical debt plus AI debt
There’s a second-order effect that most AI strategy discussions miss. Every failed AI initiative adds to your organization’s technical debt. You end up with half-implemented AI layers, abandoned middleware, prototype integrations that nobody maintains, and a codebase that’s now more complex than it was before you started.
According to makingsense.com, citing recent research from ITpro, enterprises report losing around $370 million annually due to outdated technology and the burdens of technical debt. That figure is pre-AI. Add the cost of failed AI initiatives on top of existing debt, and the compounding penalty becomes significant fast.
As Cesar DOnofrio, CEO and co-founder of Making Sense, put it: “When legacy systems limit access to reliable data, slow down integration across workflows, or make change deployment complex and time-consuming, AI initiatives stop being strategic levers and become isolated experiments. Organizations may be able to run pilots, but they cannot operationalize or scale them.”
The Five Structural Barriers That Block AI Adoption
Five specific structural problems make legacy system AI integration fail. They’re not configuration issues. They’re architecture issues.
Understanding which of these is blocking you determines the right path forward.
Incompatible architecture: monoliths, tight coupling, and missing APIs
Monolithic architectures can’t support AI integration without significant structural changes. AI systems need to interact with specific functions, not the entire application. When everything is coupled together, you can’t reach one part without going through all the others. Decomposing a monolith into AI-accessible services is a months-long modernization project, not an integration task.
Data silos and quality: AI cannot learn from data it cannot access or trust
According to tredence.com, citing McKinsey, 70% of software in Fortune 500 companies is over two decades old. Systems that old were built before data integration was an architectural priority. Data lives in separate systems that don’t talk to each other, in formats that aren’t machine-readable, with quality problems that have accumulated over decades.
AI models produce outputs proportional to the quality and completeness of their inputs. Garbage in, garbage out. If your data is siloed, inconsistent, or inaccessible, no AI model will overcome that. Clean, consolidated data isn’t a nice-to-have; it’s the prerequisite.
Scalability deficits: legacy infrastructure cannot sustain AI workloads
Running inference on a language model or processing real-time predictions requires compute resources that legacy infrastructure wasn’t sized to support. On-premise servers from ten years ago, or cloud configurations optimized for batch processing, can’t handle the concurrent request volumes AI generates at production scale. Scaling the infrastructure isn’t optional; it’s required before AI can move past pilot.
Security and compliance gaps: AI surfaces attack vectors; legacy systems weren’t built to handle
Legacy systems weren’t designed with modern threat models in mind. AI integration creates new attack surfaces, model poisoning, prompt injection, and data exfiltration through inference outputs, which require governance frameworks legacy systems don’t have. In regulated industries (healthcare, financial services, education), this is a hard stop. You can’t deploy AI without the audit trails and access controls it requires, and most legacy systems don’t have them.
Model deployment complexity: nowhere to run inference at production scale
Even if you’ve built a capable AI model, deploying it to production requires infrastructure for serving predictions, monitoring outputs, retraining on new data, and rolling back bad versions. Legacy environments typically have none of this. MLOps is a discipline built for modern infrastructure. Legacy infrastructure can’t support it without significant re-engineering.
Why “Add an AI Layer” Doesn’t Work (And What Does)
The most common attempted shortcut, adding an AI middleware layer on top of the existing system, creates a new maintenance liability without solving the underlying problem. We’re going to say this plainly: it doesn’t work, and you should know why before you try it.
The non-invasive AI layer fallacy
The pitch sounds reasonable: don’t touch the legacy system. Build an AI layer on top that reads data from it, processes it, and sends outputs back. This way, you preserve existing functionality while adding AI capability.
Here’s what actually happens. The AI layer depends on data from the legacy system. The legacy system’s data quality is inconsistent. So the AI layer inherits the data quality problems. The AI layer also depends on the legacy system’s availability and performance. When the legacy system slows down, which it does, the AI layer degrades too. You’ve now doubled your maintenance surface without improving the underlying architecture.
The “non-invasive AI layer” approach works in narrow, well-scoped cases, reading from a clean, well-maintained data source to power a specific output. It doesn’t work as a general strategy for organizations whose core systems are architecturally broken.
What readiness actually requires: the structural prerequisites for viable AI integration
AI integration becomes viable when four structural conditions are met:
The system has an API surface that can receive requests and return structured responses
The data layer produces clean, consistent, trustworthy outputs that AI can use
The infrastructure can scale to support inference workloads without degrading core system performance
The governance and security posture meet the requirements of AI deployment introduce
These aren’t features you add on. They’re architectural conditions. Building them requires structural changes to the system, which is modernization, regardless of what you call it.
The Two Viable Paths: Sequential vs. Dual-Track Modernization
Two approaches to this problem actually work. Everything else is a workaround that defers the problem. Here’s how to choose between them.
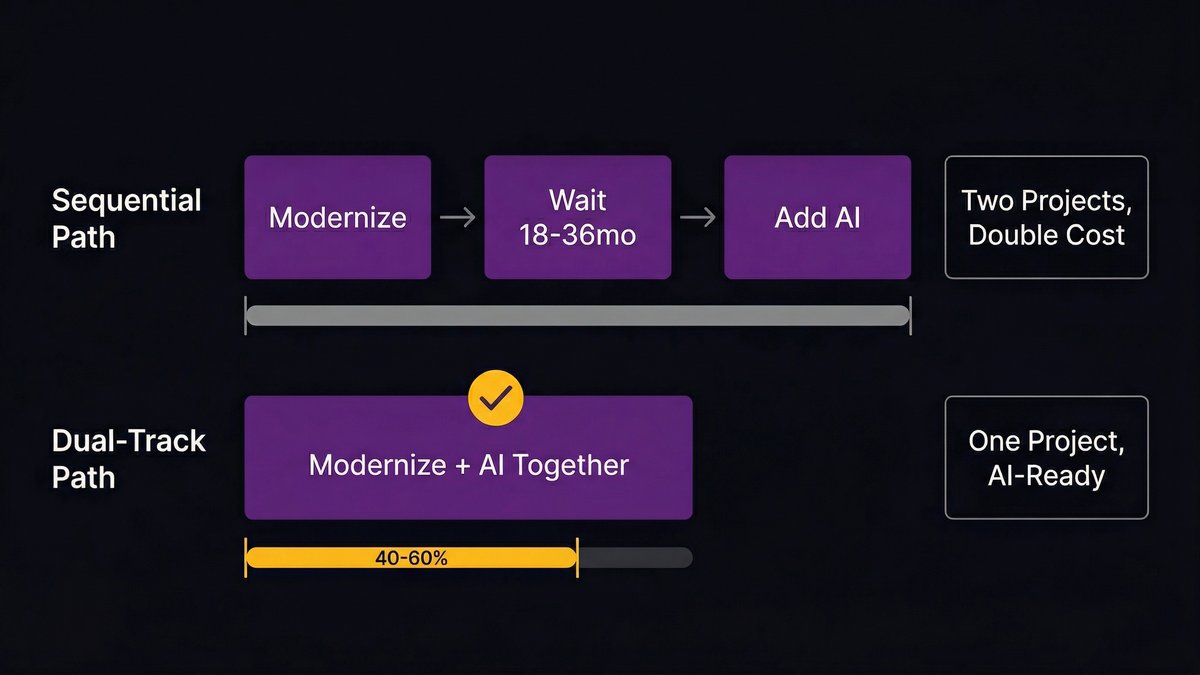
Path 1: Modernize first, then add AI
Sequential modernization means treating legacy modernization and AI integration as two separate projects executed in order. You modernize the system first, decompose the monolith, clean the data, build the API layer, migrate to scalable infrastructure, and then integrate AI into the modernized platform.
This is the lower-risk path for organizations with significant regulatory exposure or where system downtime is unacceptable. It’s also the slower path. A full sequential modernization before any AI capability is realistic, takes 18–36 months for complex legacy environments. That’s a long time to wait in a market where competitors aren’t waiting.
Path 2: AI-augmented modernization, embedding AI capability as the foundation is rebuilt
The dual-track approach runs modernization and AI integration in parallel. Instead of modernizing the system and then building AI capability, you use AI tooling to accelerate the modernization itself, automated code analysis, AI-assisted migration, and smart testing, while simultaneously designing the modernized architecture to be AI-ready from the start.
The output isn’t a modernized legacy system that AI will eventually be added to. It’s a system whose architecture was designed with AI integration as a first-class requirement. AI features emerge from the same project that produced the modernized foundation.
Why the dual-track approach compresses the timeline and eliminates the ‘two separate projects’ trap
The most expensive mistake organizations make is treating modernization and AI integration as sequential projects with separate budgets, teams, and timelines. This doubles the disruption and unnecessarily extends the timeline.
The dual-track approach produces the same outcome in roughly 40–60% of the time, because the modernization work is informed by AI integration requirements from day one. You don’t build a foundation and then retrofit it. You build a foundation that’s already designed for what you need it to do.
Legacy modernization delivers a 74% reduction in IT costs across hardware, software licensing, and staffing. When that modernization is paired with AI capability development in a single project, the ROI timeline compresses significantly, because you’re not paying for two separate transformations.
This is what Nexa Devs’ AI-augmented SDLC is designed to do. Rather than sequencing a modernization engagement followed by an AI integration engagement, the AI-augmented delivery process treats AI readiness as an architectural requirement that shapes the modernization work itself. The foundation and the capability come out of the same project.
How to Assess Your AI Readiness: A Structural Checklist for CTOs
Your AI readiness comes down to four questions. If you can’t answer yes to all four, AI integration will fail or stall. Here’s how to evaluate each one honestly.
API surface area: Can your systems be decoupled?
Can you interact with specific business functions, read a customer record, trigger a transaction, query an inventory position, through a defined API? Or does accessing that function require going through the entire application?
If your answer is “we’d have to build an API layer first,” that’s the scope of your modernization project, not a pre-existing foundation. Document which functions need API exposure for your highest-priority AI use cases, and that list becomes your modernization roadmap.
Data accessibility: Is your data structured, accessible, and clean enough for training or inference?
Can you extract a clean dataset for any entity your business cares about, customers, products, orders, transactions, in a structured format without weeks of ETL work? Or is that data scattered across tables, partially duplicated, inconsistently formatted, or locked in a system with no export capability?
Data quality problems don’t get fixed by AI. They get inherited. The data your model trains on determines the quality of its outputs. If you can’t characterize your data quality today, your AI integration will produce results you can’t trust.
Infrastructure elasticity: Can your compute layer scale for AI workloads?
Production AI inference generates request volumes and compute demands that are qualitatively different from traditional transactional workloads. A server sized for 500 concurrent users running your ERP system may not have the headroom to run real-time inference alongside it.
Test this before you integrate. Run a load simulation that approximates your target AI use case alongside your normal production workload. If performance degrades, you need infrastructure changes before integration, not after.
Governance posture: Do you have the audit trails AI requires?
AI in production requires logging of model inputs and outputs, version control for models in deployment, rollback capability when model behavior degrades, and access controls that limit who can query the model and with what data. These aren’t optional in regulated industries; they’re required.
If your current system lacks audit logging, model governance, and an access control framework that can scope AI queries, that’s the infrastructure you need to build before deploying AI to production.
The Incremental Path: Modernizing Without a Big-Bang Rewrite
You don’t have to rewrite everything to get AI-ready. The strangler fig pattern gives you a path that keeps production running while the modernized architecture grows around it.
The strangler fig pattern applied to AI readiness
The strangler fig pattern replaces a legacy system incrementally. Rather than shutting down the old system and launching the new one on a fixed date, you build new services alongside the old system. Traffic is gradually routed to the new services as they’re validated. Over time, the old system is “strangled”, its functionality replaced piece by piece, until it can be decommissioned safely.
Applied to AI readiness, this means you don’t have to achieve full architectural modernization before getting any AI benefit. You identify the specific services that need to be API-enabled and data-clean to support your highest-priority AI use cases. You modernize those services first. You get a limited but functional AI integration while the broader modernization continues in the background.
This matters for mid-market organizations because it produces demonstrable progress without the all-or-nothing risk of a complete system replacement.
What the 5 R’s of modernization mean for AI integration sequencing
The five standard modernization strategies, Rehost, Refactor, Rearchitect, Rebuild, and Replace, have different implications for AI readiness:
Rehost (lift-and-shift to the cloud): improves infrastructure scalability and enables cloud-native AI services. Doesn’t fix data quality or API surface area problems. Good first step for infrastructure elasticity.
Refactor (optimize existing code without architectural change): reduces technical debt and improves maintainability. Minimal direct impact on AI readiness unless the data model or API surface is explicitly addressed.
Rearchitect (change the structure significantly): highest AI-readiness impact. Decomposing a monolith and building an API layer directly enables AI integration. The right choice for systems where architecture is the blocker.
Rebuild (rewrite from scratch on a modern stack): maximum AI readiness, maximum risk, and timeline. Justified only when the existing system is so degraded that incremental improvement isn’t viable.
Replace (commercial off-the-shelf replacement): fast but rarely full AI readiness, COTS systems have their own AI integration constraints. Evaluate AI capability as a selection criterion, not an afterthought.
Most mid-market modernization paths involve a combination: Rehost to improve infrastructure, Rearchitect to decompose the core, and targeted Rebuild for components too broken to salvage.
What Mid-Market Companies Get Wrong That Enterprise Guides Won’t Tell You
Most AI integration content is written for organizations with 5,000 employees, a dedicated AI team, and an 18-month runway. If that doesn’t describe you, the playbook doesn’t apply.
This is the conversation that rarely happens in vendor content, conference keynotes, or analyst reports: the advice being given to mid-market companies was designed for enterprises with fundamentally different constraints. Following it produces initiatives that stall, fail to achieve ROI, or require resources the organization doesn’t have.
Why enterprise modernization playbooks don’t scale down to $50M–$500M organizations
Enterprise AI integration programs have dedicated transformation teams, multi-year budgets, and the organizational tolerance for projects that take three years to show results. They can afford to run parallel tracks, absorb failed experiments, and maintain the legacy system indefinitely while the new architecture is built.
Mid-market companies can’t. They have one engineering team. They can’t afford to keep the old system running while building a new one if the new one is going to take 24 months. They don’t have the governance infrastructure that enterprise frameworks assume. And they don’t have the internal AI expertise to implement the recommended technical patterns.
Technical debt and outdated architectures directly affect how investors assess operational risk and future performance, particularly in M&A scenarios. For a mid-market company, this isn’t abstract: it’s what happens when a potential acquirer does technical due diligence and finds a system that can’t support modern integration. The deal structure changes, or the deal dies.
Mid-market-specific constraints: budget, team size, and risk tolerance
Three constraints define the mid-market AI integration problem:
Budget constraint. There’s no separate “AI transformation” budget. The money for AI integration comes from the same envelope as everything else. This means the approach has to produce value fast enough to justify continued investment, not in year three, but in year one.
Team size constraint. A five-person engineering team can’t run a modernization program, maintain production systems, and build AI features simultaneously. The math doesn’t work. Any strategy that requires expanding internal headcount by 50% to execute isn’t a strategy; it’s a prerequisite.
Risk tolerance constraint. A mid-market company can’t survive a six-month production outage during a system migration. The big-bang rewrite that failed to deliver for three years in a row isn’t just a cost problem; it’s an existential risk that the board will never approve again.
The right approach for mid-market organizations is narrow, staged, and designed to produce demonstrable results within the first 90 days. Start with the highest-value AI use case. Identify the minimum modernization work required to support that use case. Execute that first. Use the outcome to fund the next stage.
This is where an experienced nearshore partner with AI-augmented delivery capability outperforms both in-house teams and traditional project vendors. The nearshore model gives you senior engineering capacity without the headcount burden. The AI-augmented SDLC compresses timelines. And the dual-track approach means you’re not running two separate projects, you’re running one.
What are the 5 R’s of modernization?
The 5 R’s are Rehost, Refactor, Rearchitect, Rebuild, and Replace. For AI readiness, Re-architect has the highest impact; it decomposes monolithic systems and creates the API surfaces AI needs. Most mid-market paths combine Rehost (for infrastructure) with Rearchitect (for structure).
Why does legacy system AI integration fail so often?
It fails because legacy systems weren’t built to support AI workloads. They lack APIs, their data is siloed and inconsistent, and their infrastructure can’t scale for inference. Bolting an AI layer on top inherits these problems. Successful integration requires structural modernization, not just new tooling.
Can you add AI to a legacy system without a full rewrite?
Yes, for specific well-scoped use cases where the target data is already clean. The strangler fig pattern allows incremental modernization, replacing specific services one at a time while keeping the rest running. It produces AI capability without the all-or-nothing risk of a full rewrite.
How long does it take to make a legacy system AI-ready?
A focused use case via the strangler fig approach: 3–6 months. Enterprise-wide transformation: 12–24 months. The dual-track approach, modernizing and embedding AI simultaneously, compresses the overall timeline by 40–60% compared to sequential projects.
What’s the difference between a pilot and production AI integration?
A pilot run is performed against a clean, controlled dataset in isolation. Production integration runs against live data at full volume with real business consequences for errors. According to Gartner, 42% of AI pilots never reach production, usually because the underlying system can’t support production integration without structural changes.
Legacy Modernization ROI: Real Numbers to Get Budget Approved
You already know the pitch. Legacy systems cost too much to maintain, slow your team down, and block you from doing anything interesting with AI. The problem isn’t the premise. The problem is that when you try to build a business case, the numbers you find online are all from $50M enterprise transformation programs with 18-month timelines and an army of consultants.
That’s not your situation. You’re running a company with 50 to 500 people. Your IT engagement is going to be $500K to $2M, not $10M. You need numbers that actually fit your context, and a framework your CFO will accept.
This post gives you both.
The Maintenance Tax: What Legacy Systems Are Actually Costing You Right Now
Before you can justify a modernization investment, you need to price the status quo. Most CEOs underestimate this number because the costs are distributed across budget lines rather than sitting in a single “legacy system” line item.
The 60-80% IT Budget Trap and What It Means in Dollar Terms
According to Quinnox (citing Gartner), 60-80% of IT budgets go to maintaining aging systems rather than building anything new. That number sounds abstract until you do the arithmetic for your own business.
Say your total IT spend — software licenses, internal IT staff, external contractors, cloud infrastructure — is $800K per year. At 70%, that’s $560K going backward. Not improving the system, not adding capability. Keeping it running. That $560K produces zero growth, zero competitive advantage, and zero AI readiness.
According to Deloitte’s 2026 Global Technology Leadership Study, technical debt accounts for 21% to 40% of an organization’s IT spending. Even at the low end, that’s real money that never converts into business outcomes.
The Hidden Costs That Don’t Show Up in Your IT Line Item
The direct maintenance number is only part of the picture. The rest shows up in places you’re not tracking:
Delayed features. When your team spends 25-33% of developer time on technical debt, every new capability takes longer to ship than it should.
Security exposure. According to Quinnox (citing the IBM 2023 Cost of a Data Breach Report), the average cost of a data breach is $4.45 million. Unmaintained legacy systems are the primary attack surface.
Talent drag. Developers with current skills don’t want to work on COBOL or 15-year-old monoliths. You pay a premium to recruit engineers willing to take that work, and you lose the ones you have faster.
Opportunity cost. Every sprint your team spends patching old code is a sprint not spent building the product capabilities that would grow your revenue.
According to Making Sense (2025), enterprises report losing approximately $370 million annually due to outdated technology and the burdens of technical debt. That figure skews large because it reflects enterprise-scale losses. At mid-market scale, the principle holds even if the number doesn’t: the cost of standing still is not zero.
What Modernization Actually Costs at Mid-Market Scale
Here’s where most ROI content fails the mid-market CEO. The case studies are all enterprise. IBM’s 74% cost reduction story comes from a Fortune 500 modernization with hundreds of systems and years of runway. That context doesn’t translate.
Let’s work with realistic numbers.
Phased vs. Full Rewrite: The Cost and Risk Difference
There are two fundamentally different approaches to modernization. Most conversations conflate them, which is why so many business cases fall apart.
Full rewrite means rebuilding the system from scratch on a new stack while running the old one in parallel until the new system is ready to take over. At mid-market scale, this typically runs 18-36 months and costs $1.5M-$5M depending on system complexity. The risk is high. The payback window is long. And the business still depends on the old system the entire time.
Incremental (phased) modernization means decomposing the system into components and modernizing them one module at a time — the strangler fig pattern. You ship value faster, test in production, and the old system keeps running until each component is replaced. At mid-market scale, initial phases typically run $500K-$2M over 6-12 months with continued phases as budget and roadmap allow.
For most mid-market companies, the incremental path produces better ROI and lower risk. Full rewrites are appropriate for specific situations — systems that are completely unmaintainable, critical security failures, or architecture so degraded that phased improvement isn’t viable.
What a $500K-$2M Modernization Engagement Covers
At this scope, a well-structured modernization engagement typically includes:
Architecture assessment of the existing system
Migration of the highest-priority components (usually the ones generating the most maintenance cost or blocking the most growth)
API layer development to connect the modernized components to the remaining legacy modules
Cloud migration for modernized components
Full documentation transfer: architecture diagrams, API references, system design docs
One month of post-launch support with an ongoing SLA option
That’s not a complete system rebuild. It’s targeted, structured modernization designed to deliver measurable ROI within a 12-18 month window.
The Cost Variables That Determine Your Number
Four variables move your number the most:
System complexity. How many integrations, how much undocumented logic, how many languages and frameworks?
Scope of modernization. What percentage of the system are you migrating in this engagement?
Target architecture. Cloud-native, containerized, or cloud-hosted — each has different cost and complexity profiles.
Team model. Nearshore teams running in U.S. timezone alignment typically cost 40-60% less than equivalent onshore capacity, which directly extends what $1M of budget can deliver.
The ROI case for modernization is strong. The numbers below come from real modernization programs — mostly enterprise, some mid-market. Translate them to your context using the discount logic below.
Infrastructure and Maintenance Cost Reduction
According to UpdateCode (2026), IBM research shows legacy modernization delivers a 74% reduction in IT costs. AWS reports 66% infrastructure cost reduction post-modernization.
At mid-market scale, the infrastructure savings are real, but the percentage may be lower. A realistic expectation for a $1M scoped engagement is a 30-50% reduction in maintenance costs for the systems modernized. On $560K in annual maintenance spend, that’s $170K-$280K in annual savings.
That’s your payback math starting point.
Productivity and Time-to-Market Gains
According to Quinnox (citing McKinsey), organizations see 40% faster time-to-market, 30% reduction in operational costs, and double-digit revenue growth from modernization programs.
The time-to-market number tends to be the most powerful for mid-market CEOs, because it answers a question your board and investors care about: how fast can you ship? Legacy systems don’t just cost money to maintain. They create friction in every new development cycle. When a sprint that should take two weeks takes six because engineers are working around technical debt, every feature ships late.
According to Devox Software’s 2026 Legacy Modernization Report, AI applied to legacy modernization programs produces a 39% EBIT impact for high performers. That figure combines infrastructure savings, productivity gains, and new revenue from capabilities that were previously impossible to build.
Revenue Impact: The Cases Where Modernization Drove Growth
The revenue impact of modernization is the hardest to quantify in advance. But consider what becomes possible post-modernization that isn’t possible now:
AI-powered features require clean, accessible data and modern APIs. Both are byproducts of modernization.
Faster deployment cycles mean you can ship product improvements monthly rather than quarterly.
System reliability improvements reduce customer churn in businesses where downtime has direct revenue consequences.
The businesses that see double-digit revenue growth from modernization aren’t the ones that treated it as a cost-reduction exercise. They’re the ones who modernized to build capabilities that weren’t previously available to them.
Payback Period: How Long Before Modernization Pays for Itself
Payback period is the CEO’s risk proxy. The shorter the window, the lower the exposure. This is the number that turns a theoretical ROI into a decision.
Incremental Modernization: 6-18 Month Payback Windows
According to Bayone (2025), incremental modernization payback periods run 6-18 months, compared to 36-48 months for full rewrites.
That difference is significant. An 18-month payback on a $1M engagement means you’re break-even before the end of the second year. A 48-month payback on a $3M full rewrite means you’re four years out before the investment returns. Most mid-market companies can’t afford to wait that long, and most boards won’t approve it.
The 6-18 month window assumes you’re modernizing the highest-ROI components first, the ones generating the most maintenance cost or blocking the most revenue. That’s the sequencing decision that makes the payback window real rather than theoretical.
Full Rewrite Timelines: Why the Math Rarely Works for Mid-Market
Full rewrites at mid-market scale almost never produce the ROI they promise. The reasons are predictable:
Scope creep extends timelines and costs
The business doesn’t stop changing while the rewrite is underway
Engineers spend more time learning the old system to replicate its behavior than building anything new
The old system continues accumulating maintenance costs during the entire rewrite period
The exceptions are narrow: systems that are completely broken, security vulnerabilities so severe that continued operation is not viable, or architecture so degraded that incremental modernization would cost more than starting over. Outside those cases, phased modernization wins on both cost and risk.
How AI-Augmented Delivery Compresses the Payback Window
This is where delivery methodology becomes a strategic variable, not just a vendor selection detail.
AI-augmented development — using AI across the full software development lifecycle, from requirements analysis through implementation and testing — directly compresses the payback window in two ways.
First, faster delivery means less time before the modernized system starts generating savings. If an AI-augmented team delivers the first phase in four months instead of seven, you start recovering maintenance costs three months earlier.
Second, cleaner architecture on delivery means lower post-launch maintenance costs. Systems built with AI assistance tend to have more consistent code quality, higher test coverage, and better documentation than traditionally built systems, which reduces the ongoing cost basis from day one.
The combination doesn’t change the ROI math. It tightens the timeline on which you realize it.
The Cost of Waiting: What One More Year on Legacy Infrastructure Really Costs
Delay feels safe. It’s not. It’s an active choice with a compounding cost.
Compounding Maintenance Costs Year-Over-Year
Legacy systems don’t age gracefully. Every year of deferred modernization adds to the maintenance backlog, reduces the pool of engineers who can work on the system, and increases the cost of the eventual modernization. According to technical debt cost models, businesses lose 10-20% of their IT budget to technical debt every year without it appearing as a budget line item.
If you have $560K in annual maintenance spend today, waiting three years doesn’t save you $1.5M. It costs you that much, plus the maintenance costs keep accelerating as the system gets older and harder to work with.
Opportunity Costs: What You Can’t Build While Maintaining Legacy
The more consequential cost of waiting isn’t measured in IT budgets. It’s measured in what you can’t do.
As Ray Forte of Analog Devices described the problem: “low 80s” of the budget going to keep-the-lights-on operations means less than 20% available for anything new. That ratio doesn’t improve on its own.
More specifically: AI capabilities — the ones your competitors are building right now — require modern infrastructure. Clean data, accessible APIs, modular architecture. Every year you wait for modernization is another year your competitors are building AI-powered capabilities on top of their modernized systems while you’re still patching the old ones.
According to technical debt cost research (McKinsey, via Quinnox), technical debt will cost organizations $5 trillion in lost productivity by 2030. The individual company’s share of that number is the revenue they don’t generate because their engineering capacity is consumed by maintenance rather than growth.
How to Build the Business Case Your CFO Will Actually Approve
The business case for modernization fails most often not because the numbers are wrong, but because they’re presented in terms a CFO doesn’t recognize.
CFOs don’t think in “modernization ROI.” They think in NPV, payback period, IRR, and risk-adjusted return. Give them those, and the conversation changes.
The Four Numbers Every CFO Wants to See
1. Total cost of investment (TCI). The full cost of the modernization engagement: vendor fees, internal staff time, downtime risk provisions, and change management. Not just the vendor quote.
2. Annual net benefit. What the modernized system saves annually compared to the current baseline: maintenance cost reduction, productivity gains (translated into labor costs), and any revenue upside. Be conservative. CFOs discount optimistic projections.
3. Payback period. TCI is divided by the annual net benefit. For a $1M engagement delivering $500K in annual savings, that’s a 24-month payback. For a $1M engagement delivering $700K in annual savings (factoring in productivity), that’s 17 months.
4. Year-3 ROI. Total net benefit over 36 months minus TCI, divided by TCI, expressed as a percentage. This is the number that makes the investment case obvious when it exceeds 100%.
Framing Modernization as Risk Reduction, Not Just Cost Savings
The strongest business cases for modernization combine cost savings with risk reduction. CFOs respond to risk reduction because it’s easier to model and harder to dispute.
The risk framing has two components:
Security risk. Unpatched legacy systems are breach vectors. A single breach at $4.45M average cost (IBM, 2023) wipes out three to five years of the IT budget. Modernization is partial insurance against that exposure.
Business continuity risk. If the one engineer who understands your legacy system leaves, how long before you can’t operate it? Key-person risk on legacy infrastructure is a material business continuity threat that most boards haven’t formally evaluated.
A Simple ROI Model You Can Run Before Vendor Conversations
Before you talk to any vendor, run this four-step model:
Establish your current annual maintenance cost. Pull your IT budget. Estimate the percentage going to maintenance and keep-the-lights-on (60-80% is the typical range per Gartner). That’s your baseline waste.
Project annual benefit conservatively. Assume 30% maintenance cost reduction on the modernized scope (conservative vs. IBM’s 74%), plus 20% productivity gain on the engineering team time freed up. Translate that productivity gain into dollar value.
Get two vendor quotes for the incremental scope. Structure the RFP around the highest-ROI components first, not the entire system. You’re looking for a phase-one engagement, not a full rewrite.
Run the payback math. Quote divided by annual benefit. If it’s under 24 months, the investment case is strong. If it’s 36+ months, review whether the scope is right.
This takes an afternoon to run. It gives you a defensible number for the CFO conversation before you’ve spent a dollar on vendor evaluation.
Choosing a Modernization Partner Without Creating a New Dependency
The most common CEO objection to modernization isn’t cost. It’s this: “We’ll just end up dependent on whoever does it.”
That fear is legitimate. Most legacy systems got that way because the vendor who built them left no documentation and no knowledge transfer. You replaced one black box with another. The prospect of doing it again — this time with a newer technology stack — is a rational deterrent.
The answer isn’t to avoid vendors. It’s to evaluate them on the variables that determine whether you end up owning the system or renting it.
What Documented Handoff Actually Means (and Why Most Vendors Don’t Offer It)
“Documented handoff” is not the same as “we’ll write some notes at the end.” A genuine documented handoff includes, at a minimum:
UML architecture diagrams covering the system as-built
API documentation (Swagger or Postman format) covering all internal and external interfaces
System design documents explaining key architectural decisions and why they were made
User story libraries covering the full scope of implemented features
Test coverage reports showing what’s tested and what isn’t
Onboarding documentation sufficient for a new engineer to work productively on the system within two weeks
That set of deliverables transfers the system knowledge from the vendor to your organization unconditionally. It means the next engineer — whether from Nexa, another vendor, or your own team — can pick up the system without starting from scratch.
Most vendors don’t offer this because it requires investment in documentation throughout the engagement, not just at the end. It’s easier to skip it and rely on ongoing support relationships to maintain their position. That reliance is the dependency you’re trying to avoid.
Questions to Ask Any Vendor Before You Sign
Use these before you sign anything:
What documentation will you transfer at project close, and can you show me examples from a prior engagement?
Who owns the IP, and is that ownership unconditional or tied to ongoing payment?
If we end the engagement at delivery, how long would it take a competent engineer unfamiliar with this system to become productive?
Do you offer phased delivery with working software at each phase checkpoint — or does the first deliverable come at the end?
Can we see code and documentation at any point during the engagement, not just at handoff?
Vendors who can’t answer questions 1 and 3 confidently are telling you something about what you’ll actually receive.
As Juris Bergmanis, Corporate Strategy & IT Project Manager, LTECH(2026) said, “A vendor can only be considered easy to replace if it can be done without rebuilding systems, transforming data, or interrupting business operations. If even one of these conditions is not met, the replacement cannot realistically be considered easy, regardless of what the contract states. This is not a legal question but a practical capability of the organization.”
The core risk isn’t the initial engagement — it’s what happens after the vendor leaves.
Get a Modernization ROI Estimate Before You Commit to Scope
Before you run the CFO conversation, you need numbers tied to your specific system — not industry averages. Nexa’s architecture assessment identifies which components of your system are generating the most maintenance cost, which are blocking AI capability, and what phased modernization would actually cost at your scale.
The assessment takes two to three weeks. You get a documented report covering current maintenance cost drivers, recommended modernization sequence and scope, and a phased ROI model you can take to your CFO.
FAQ
What is the ROI of legacy modernization?
Legacy modernization ROI varies by scope and approach. IBM data shows a 74% IT cost reduction; AWS reports 66% infrastructure cost savings. Forrester found 228% ROI over three years for Azure PaaS modernization. At mid-market scale, expect 30-50% maintenance cost reduction with full payback in 12-24 months on a phased engagement.
What is the cost of technical debt to a business?
According to Deloitte’s 2026 Global Technology Leadership Study, technical debt accounts for 21% to 40% of an organization’s IT spending. Enterprises lose approximately $370 million annually due to outdated technology (Making Sense, 2025). For mid-market companies, this means hundreds of thousands in annual maintenance spend that produces no growth or innovation.
What is a good payback period for an IT modernization investment?
According to Bayone (2025), incremental modernization delivers payback in 6-18 months, versus 36-48 months for full rewrites. For mid-market companies, any phased modernization engagement with a sub-24-month payback is a strong investment. A 36-month payback usually signals a wrong scope or a wrong approach.
What is technical debt in business terms?
Technical debt is the accumulated cost of past software shortcuts. Teams pay interest continuously through slower feature development, higher maintenance costs, and lower system reliability. According to Deloitte, this interest payment consumes 21-40% of a typical organization’s entire IT budget.
How much does a digital transformation or modernization project cost?
At mid-market scale (50-500 employees), a phased modernization engagement typically runs $500K-$2M for the first phase. Enterprise programs run $10M+, which is why most published ROI figures don’t apply to mid-market situations. Nearshore teams can reduce costs by 40-60% versus equivalent onshore capacity.
What percentage of IT budgets goes to maintaining legacy systems?
According to Gartner (via Quinnox), 60-80% of IT budgets go to maintaining aging systems. CIO Dive (2025) found 43% goes specifically to legacy maintenance, with only 29% allocated to transformative technology.