The AI-Modernization Window: Why 2026 Is the Year Mid-Market Companies Must Break Free From Their Legacy Systems
You ran a pilot. Maybe two. The AI demos were impressive. Your team was energized. Then someone asked the question that ended the conversation: “Can our current systems actually support this?”
That pause, that moment of quiet before someone changes the subject, is where most mid-market AI strategies die. Not because the AI doesn’t work. Because the systems underneath it don’t.
This is the most common and least discussed bottleneck in mid-market technology today. And in 2026, ignoring it has a cost that compounds daily.
The 2026 Modernization Window: Why Mid-Market CEOs Are Running Out of Time
The window is real, it’s narrow, and it won’t reopen on a convenient schedule.
According to QBSS (2026), 2026 marks the inflection point where mid-market velocity surpasses enterprise scale in AI adoption. That’s not a marketing claim. It’s a structural shift in who moves fastest when the bottleneck is organizational agility, not capital.
The competitive divide is compounding daily
Enterprise companies are slow. Their AI initiatives require cross-functional steering committees, 18-month procurement cycles, and change management programs. That used to be an advantage; they had the capital to absorb those timelines.
Mid-market companies don’t have that luxury. But they also don’t have that drag. A 150-person company with an engineering team of 15 can make and execute a modernization decision in a quarter. The ones doing this now are building AI capabilities that their larger competitors won’t match for two years.
The ones that aren’t? They’re watching competitors ship things their own systems can’t support.
According to an Everest Group report commissioned by R Systems (March 2026), over 40% of mid-market enterprises are already bypassing traditional AI adoption stages to accelerate competitiveness. They didn’t wait for a perfect roadmap. They found an entry point and moved.
Why 2026 is different from previous “transformation” cycles
For the past decade, someone has declared it “the year of digital transformation.” This time, the market data backs the claim.
According to Mordor Intelligence, the global legacy software modernization market is valued at $29.39 billion in 2026, growing at a 17.64% CAGR. That growth rate doesn’t happen because of hype. It happens because the cost of not modernizing finally exceeded the perceived risk of doing it.
The companies winning in 2026 aren’t the ones with the best AI strategy on paper. They’re the ones who eliminated the infrastructure barrier that was blocking the strategy they already had.
The Hidden Tax: What Legacy Systems Are Really Costing Your Business
Legacy systems aren’t a technical problem. They’re a budget problem, and the bill arrives on your P&L every month.
Most CEOs view legacy maintenance as a fixed operating cost: unavoidable, predictable, and manageable. It’s not. It’s a growing tax on your capacity to compete.
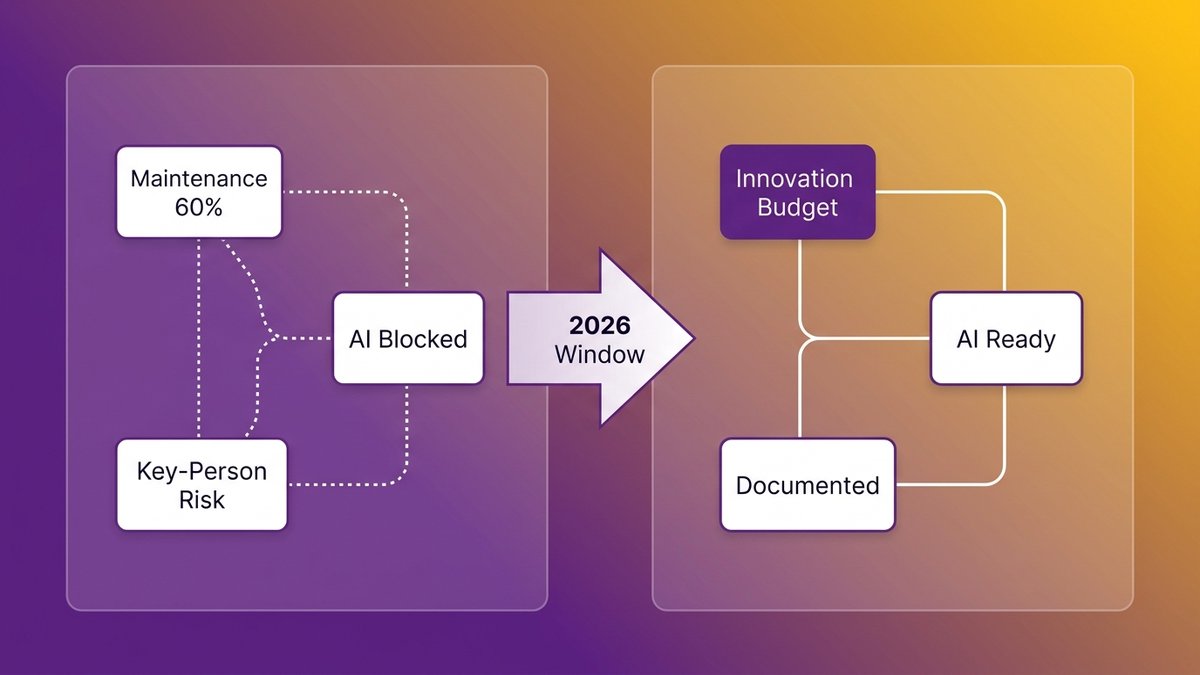
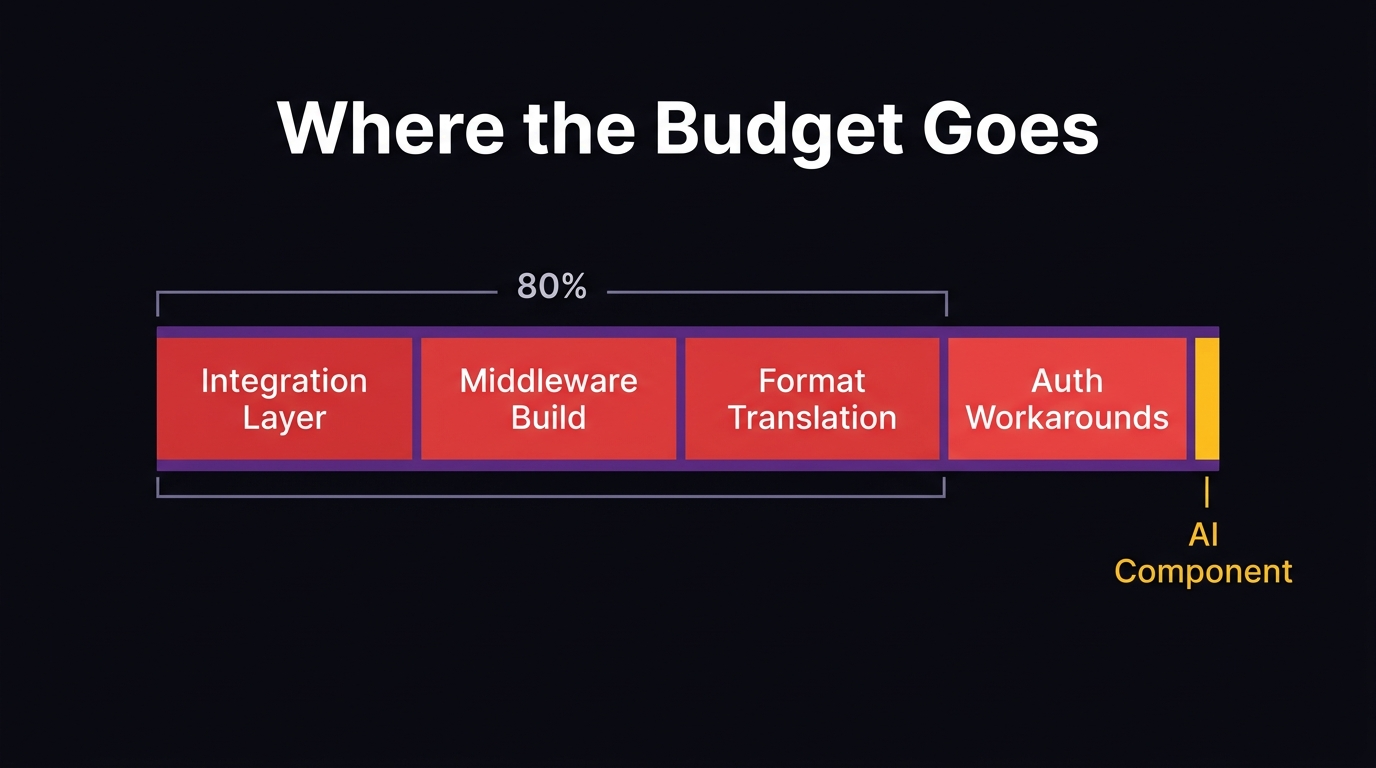
The 60–70% maintenance trap: how IT spend became a treadmill
According to ADEVS Tech Journal (February 2026), 60–70% of total software spend now goes to maintenance rather than innovation. Think about what that means at your scale.
If your annual technology budget is $2 million, you’re spending $1.2M to $1.4M keeping existing systems running. You have $600,000 left, maybe less, to build new capability, integrate AI, or modernize anything. That’s not a technology strategy. That’s a maintenance contract with a side budget for ambition.
According to Deloitte’s 2026 technology leadership research, nearly 60% of technology leaders believe 21–50% of their existing technology’s value remains trapped and inaccessible due to technical debt. The systems you’re paying to maintain aren’t even performing at full potential. You’re subsidizing underperformance.
What $3.6M/year in technical debt actually looks like on your P&L
According to Garnet Grid, a mid-market company with a 20-person engineering team loses an average of $3.6 million per year to accumulated technical debt, measured in lost velocity, delayed features, increased incident response, and developer attrition.
That number makes more sense when you break it down. It’s not a single line item. It shows up as:
Developers are spending 30–40% of their time on maintenance work instead of features
Incidents that pull the whole team off productive work for days at a time
Delayed product launches because the underlying system can’t support the change
Engineers are leaving because they don’t want to spend their careers fighting code that predates their careers
The $3.6M is real. It just doesn’t appear under one budget line, which is exactly why it keeps getting approved.
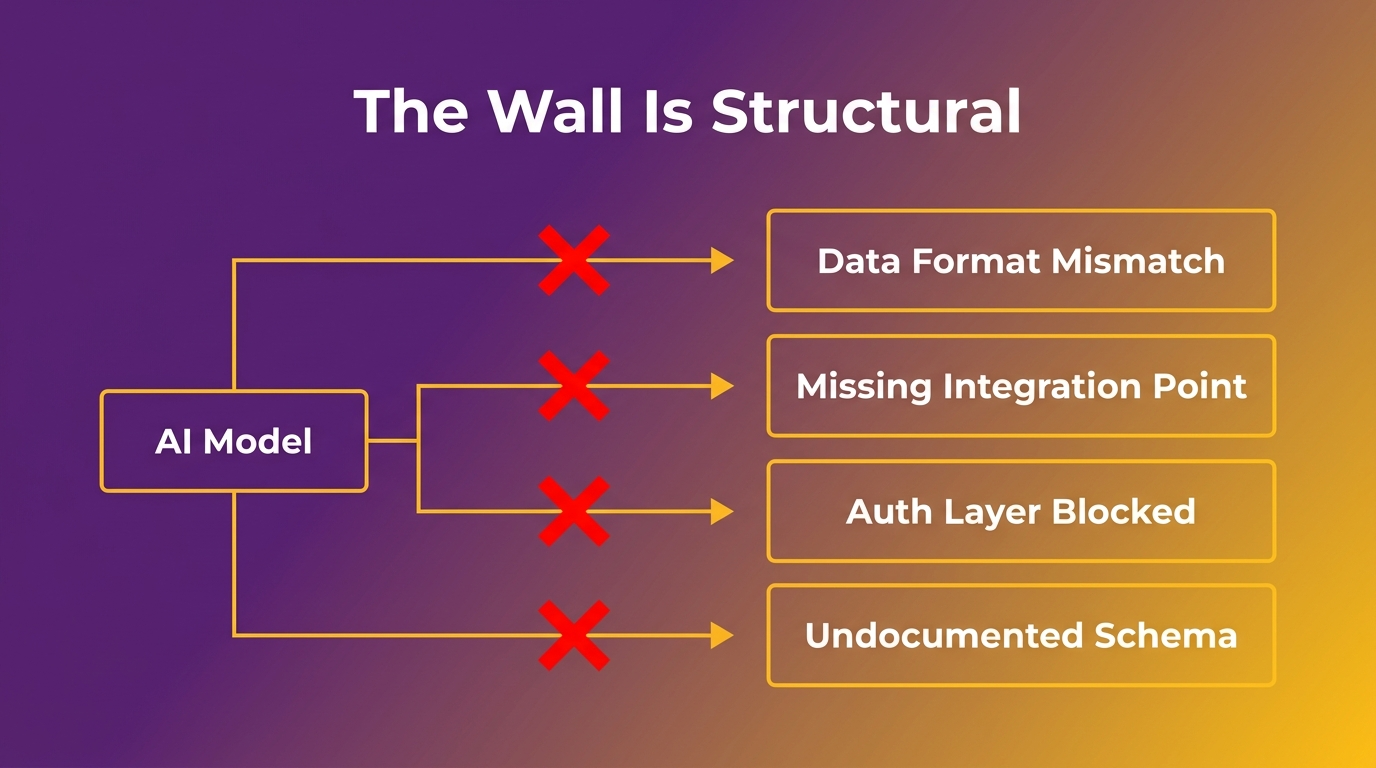
Why Your Legacy Systems Are Blocking Your AI Strategy
Your legacy systems aren’t just expensive to maintain. They’re actively preventing you from doing the thing your board is asking about.
If you’ve tried to implement any AI capability, automation, intelligent reporting, agentic workflows, and hit a wall, the wall has a name. It’s your legacy architecture.
The 60% barrier most CEOs don’t see until it’s too late
According to Deloitte Tech Trends 2026, 60% of AI leaders identify legacy system integration as their primary barrier to the implementation of agentic AI. Not talent. Not a strategy. Not budget. The systems they already own.
AI tools, whether you’re talking about automation platforms, LLM integrations, or purpose-built agents, need clean, accessible data. They need API endpoints that expose system functions reliably. They need an architecture that can accept new inputs and return structured outputs. Legacy systems, by design, have none of these. They were built in a world where software talked to humans through a screen, not to other software through an API.
This is why AI pilots succeed in demos and fail at scale. The demo environment is clean and controlled. Production is your actual legacy system, and it wasn’t built for this.
How competitors shedding legacy debt will compound their AI advantages
Here’s what doesn’t get discussed enough: this is a compounding dynamic.
A competitor that modernizes its core systems this year doesn’t just get one AI capability. It gets a platform that can absorb AI capabilities as they develop. Every quarter, it adds another automation, another integration, another agent that handles a process your team still does manually. Your competitor’s AI advantage next year isn’t the same size as today. It’s larger because each new capability built on a clean foundation costs less and ships faster than the one before.
Your legacy debt works the same way in reverse. Each year you don’t address it, the gap widens.
The Two Bad Options, And Why Both Fail Mid-Market Companies
Two options dominate the conversation about legacy modernization. Both are wrong for mid-market companies. Understanding why both fail is the only way to find the path that actually works.
The rip-and-replace trap: why full rewrites cost more than they return
The rip-and-replace approach is appealing in theory. You retire the old system entirely and build something clean from scratch. No legacy constraints. Fresh architecture. Modern stack.
In practice, it’s one of the highest-failure-rate projects in enterprise technology. Full rewrites routinely run over budget, over schedule, and under-deliver, because the team building the new system never fully understands what the old system actually does. Legacy systems accumulate business logic over the years. Edge cases, workflow accommodations, workarounds that became features. None of it is documented. Most of it isn’t even visible until the new system goes live and users discover what’s missing.
For a mid-market company, the operational risk is acute. You can’t take your core system offline for 18 months while a rewrite completes. The business runs on the old system. The new one has to be built while the old one keeps running, and eventually they have to switch over, which is where most rewrites fail.
The indefinite patching trap: why “we’ll deal with it later” is a strategy for falling behind
The alternative most mid-market companies choose is indefinite patching. Add a module here. Wrap an API there. Bolt on a new interface. Keep the core system intact, but extend it for each new requirement.
This works, until it doesn’t. And the moment it stops working is usually a critical business moment: a compliance deadline, a customer demand, a board-mandated AI initiative. The system that “mostly works” becomes the system that “can’t do this” at precisely the wrong time.
Patching also accelerates debt, not reduces it. Every workaround added to a legacy system makes the next workaround harder. The architecture gets more brittle, not less. You’re not buying time. You’re selling future options at a discount.
Mid-market companies don’t have the resources to survive a failed rip-and-replace. They also don’t have the margin to survive indefinite patching when AI competitors start pulling ahead. Both options are wrong. That’s not a pessimistic observation. It’s the starting point for finding the option that’s actually right.
The Risk Your Org Chart Doesn’t Show: Key-Person Dependency
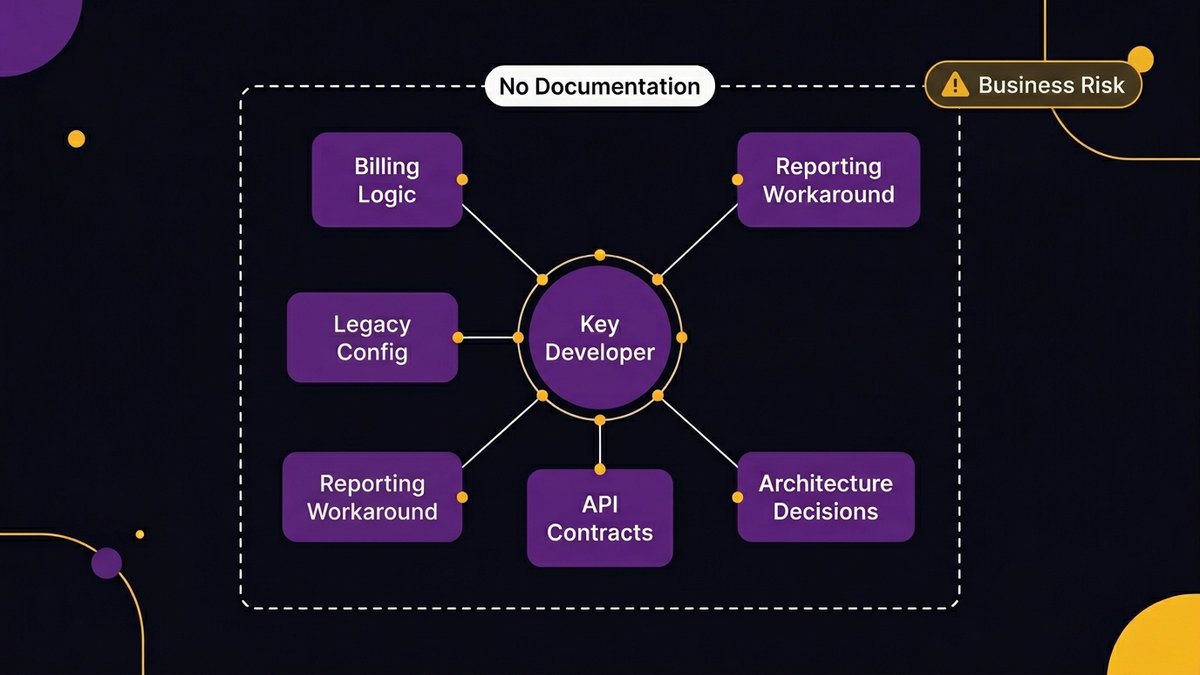
Your legacy systems have a risk that doesn’t appear in any board presentation. It’s a person. Usually one person.
What happens to your business when the one person who knows your systems leaves
Most mid-market companies have at least one person, sometimes one person, who truly understands how a critical legacy system works. They know why a specific field has a specific value. They know what breaks if you change the billing logic. They know where the workaround lives that keeps the reporting module from crashing every Monday morning.
That person is your key-person dependency. And they will leave, retire, or become unavailable. Not as a hypothetical, as a certainty.
When they do, the institutional knowledge leaves with them. The code stays. The documentation doesn’t exist. The next person to touch that system will spend months reverse-engineering what the previous developer understood intuitively.
This isn’t a technical risk. It’s a business continuity risk. It belongs in the same conversation as your disaster recovery plan and your succession planning.
As Ashwin Ballal, CIO at Freshworks, has observed, adding vendors or building on unmaintainable systems compounds complexity rather than resolving it. The root problem is never the system itself; it’s that the system is a black box that only one or two people can operate.
Why documentation debt is a business continuity risk, not just a technical one
Documentation debt is the gap between how your system actually works and how much of that is written down anywhere. For most legacy systems, that gap is enormous.
A system with strong documentation can be handed to a new developer in weeks. A system with no documentation takes months to six months to become productive, and even then, the new developer learns by breaking things, not by reading the map.
The CEO rarely thinks about documentation until something breaks. The right time to think about it is before something breaks, when the cost of creating it is a structured project rather than an emergency archaeology exercise.
Complete documentation transfer, where every architecture decision, every API contract, every business logic rule is documented and owned by your organization, is not a nice-to-have. It’s the deliverable that transforms a modernization project from a vendor dependency into an organizational asset.
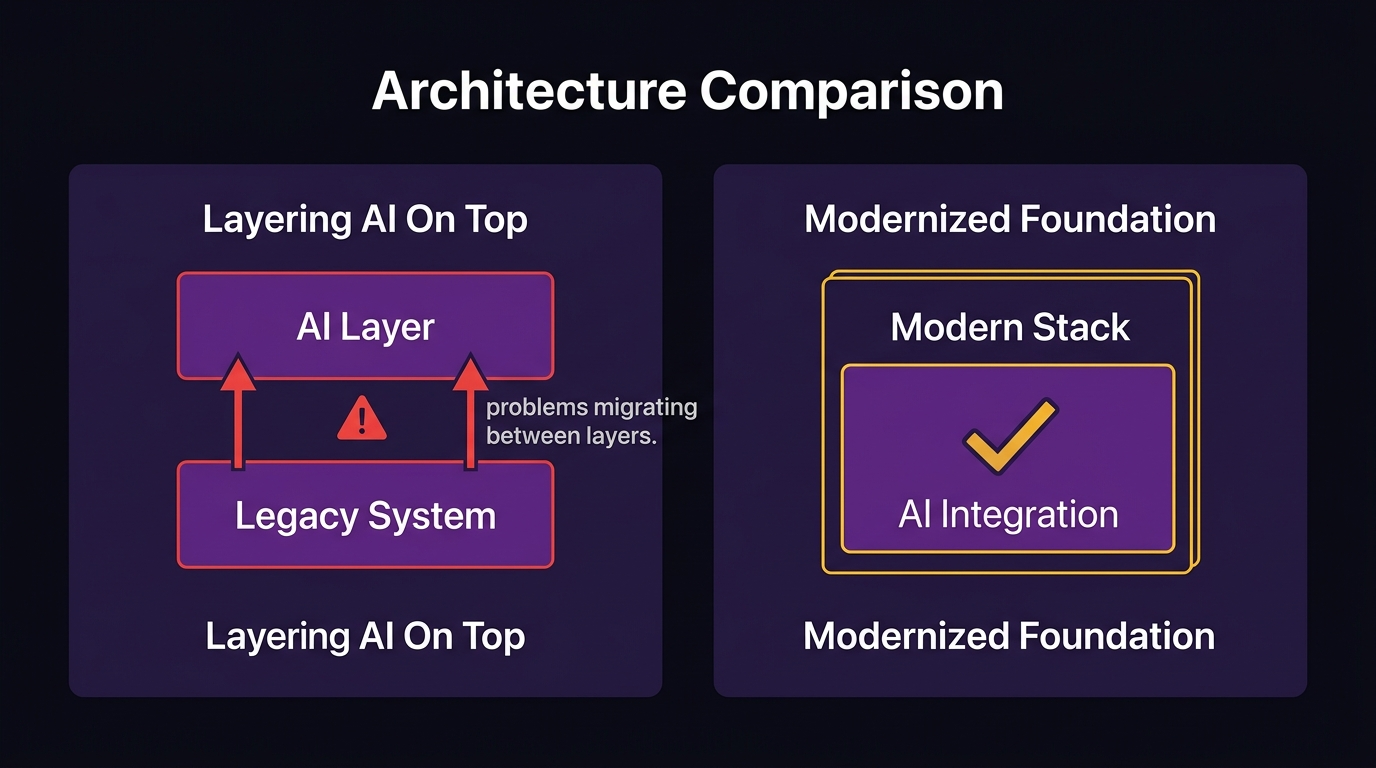
The Third Path: AI-Augmented Incremental Modernization
There is a path between rip-and-replace and indefinite patching. It’s incremental, it’s documented, and it doesn’t require betting the business on a single outcome.
What “incremental” actually means, and what it doesn’t
Incremental modernization isn’t a slower version of a full rewrite. It’s a fundamentally different strategy.
Instead of replacing the system, you identify the highest-friction components, the parts of the legacy system that cost the most to maintain, create the most operational risk, or most directly block your AI strategy. You modernize those first, while the rest of the system keeps running.
Each phase delivers a working, improved system. Not a promise of a better system when the project is done. A better system, now, with the next improvement already scoped.
This is how mid-market companies modernize without operational disruption. And it’s the only approach that fits mid-market risk tolerance and budget cycles. You’re not committing to a 3-year transformation program. You’re committing to a 90-day starting point.
How AI tools compress modernization timelines by 40–50%
The reason incremental modernization has historically been slow, and therefore unattractive, is that understanding and documenting legacy code takes enormous time. Before you can modernize a component, someone has to read, understand, and map exactly what that component does.
AI changes this calculus significantly. Fujitsu reported that AI-assisted modernization reduced project timelines by approximately 20%; agentic AI cut timelines by up to 50% (SphereInc, 2026, citing Fujitsu case data). According to HFS Research (2026), organizations deploying agentic modernization platforms report 40–60% productivity improvement and 30–50% faster modernization timelines.
AI tools can read legacy codebases, including COBOL, Oracle Forms, aging Java monoliths, and produce architecture maps, dependency diagrams, and business logic documentation in days rather than months. That documentation becomes the foundation for the modernization work itself, and the documentation transfer deliverable that the client organization owns at the end.
This is the mechanism behind AI-augmented modernization. Not magic. A faster, more systematic way to do the hardest part of modernization, understanding what already exists.
What complete documentation transfer looks like in practice
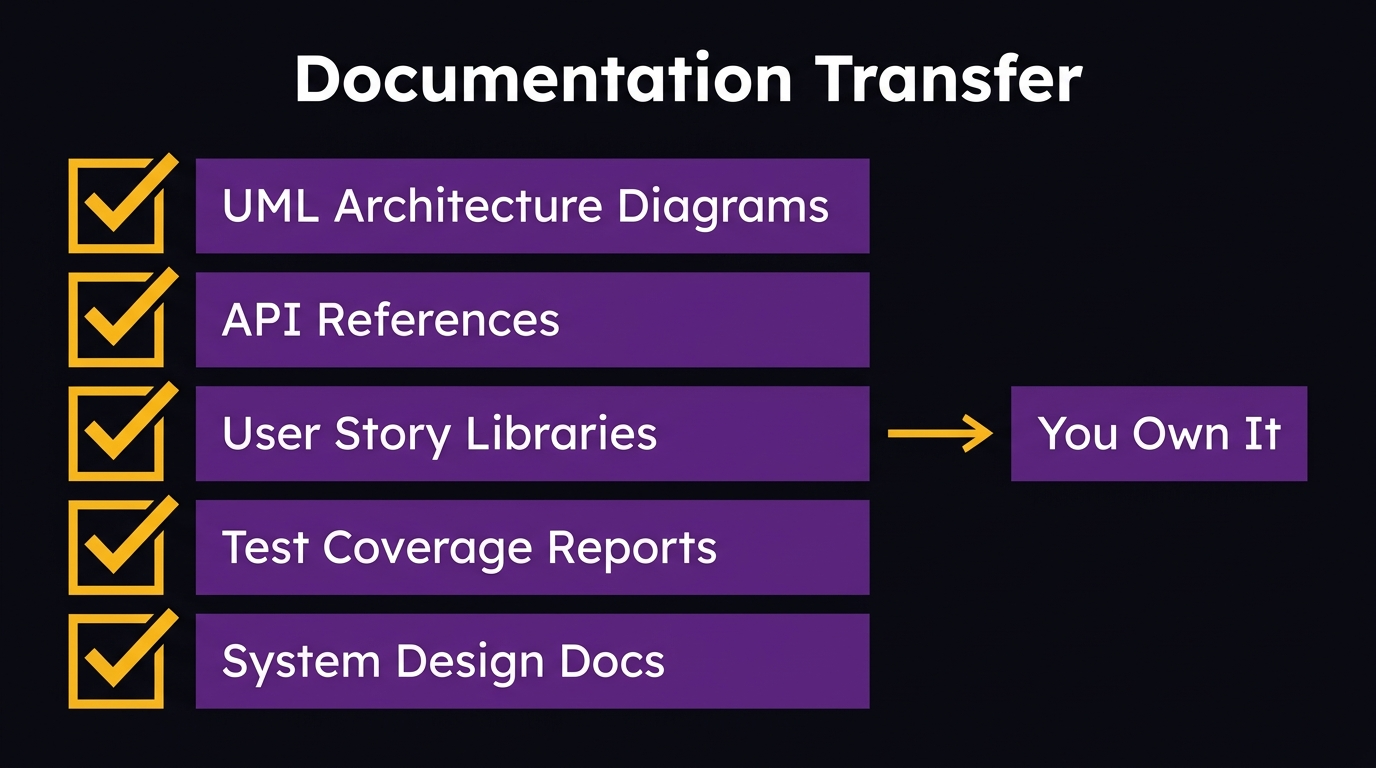
At the end of an AI-augmented modernization engagement, the documentation package you receive should include:
Architecture diagrams, UML system design showing how all components relate
API reference documentation, every endpoint, every integration, every data contract
Business logic records, the rules embedded in the code, are now written in plain language
Test coverage reports, what was tested, what the expected behavior is, and where edge cases live
Decision records, why the architecture was designed the way it was, not just what it does
This documentation is yours. Unconditionally. It doesn’t expire when the engagement ends. You don’t need the development partner to interpret it for you. If you bring in a different partner tomorrow, they can read the documentation and get productive in weeks, not months.
That’s the opposite of the black-box vendor dependency. It’s the antidote to key-person risk. And it’s the deliverable that transforms modernization from a cost into an asset.
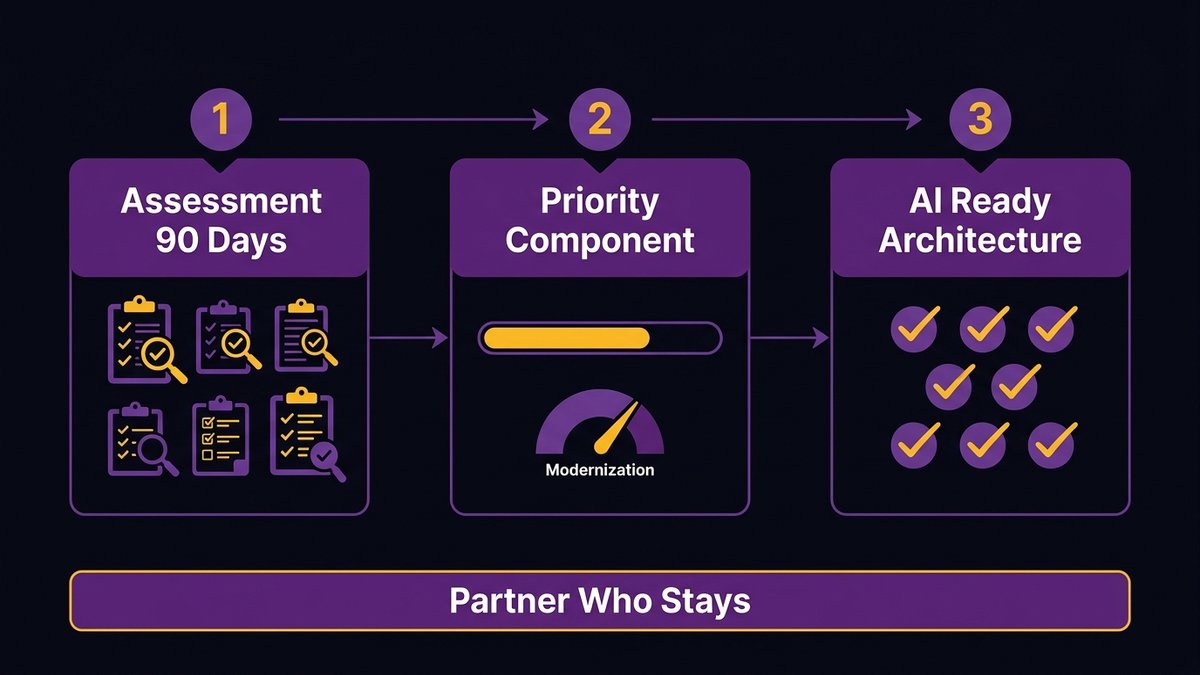
What a 90-Day Starting Point Actually Looks Like
You don’t need a 3-year transformation program. You need a 90-day starting point with a partner who stays.
The most common reason mid-market companies delay modernization isn’t budget. It’s scope anxiety. The project feels enormous, the timeline feels open-ended, and the last time they engaged a vendor on something like this it took longer and cost more than quoted.
A 90-day starting point reframes the engagement entirely.
What a modernization discovery phase delivers, and what you should expect to own at the end
The first 90 days of a well-run modernization engagement produce three things you can use immediately, regardless of what happens next:
A complete system assessment. Every component of your legacy system is mapped, including dependencies, risk areas, AI-readiness gaps, technical debt concentration, and business logic documentation. You own this. If you decide not to continue the engagement, you still have the map.
A prioritized modernization roadmap. The components sorted by business impact and risk. Not what’s technically interesting, but what costs you the most and blocks you the most. With effort estimates and phase sequencing that fit your budget cycle.
A 90-day proof-of-concept delivery. One component of your system has been modernized. Not promised. Delivered. Running in your environment. So you know what the work actually looks like before you commit to a longer engagement.
This is what de-risked modernization looks like for a mid-market company. You’re not betting on a 3-year roadmap. You’re evaluating a 90-day starting point, getting tangible deliverables, and deciding what comes next based on evidence.
How to evaluate whether a partner actually stays
The “partner who stays” part of this framing isn’t marketing language. It describes a specific structural requirement.
Most development vendors are project-oriented. They scope a project, deliver it, and move on. The handoff is their exit. If something breaks after the project closes, you’re starting a new conversation or a new vendor selection.
A partner built for ongoing engagement works differently. SLA-based support covers the systems they build, but also systems they didn’t build. The relationship adapts as your needs change. The institutional knowledge they accumulate about your systems over time is the same kind of knowledge your key-person dependency currently holds, except it’s documented, it’s in your possession, and it doesn’t leave when someone gets a better job offer.
According to Mismo Team’s 2026 outsourcing statistics guide, 58% of IT firms now prefer nearshore partners specifically for time zone alignment. Timezone compatibility isn’t a convenience feature. It’s a collaboration requirement. Real-time communication during sprints, incident response during business hours, and architecture conversations that don’t require scheduling across 10 time zones are the practical conditions that determine whether a development partner actually stays engaged or gradually becomes a stranger who checks in async.
That’s why Nexa Devs operates with Latin America-based engineers in U.S. timezone alignment. Not to tick a nearshore box. Because synchronous collaboration is the operational foundation for a partnership that outlasts the project.
How to Know If Modernization Is the Right Move Right Now
Self-assessment isn’t about checking boxes. It’s about naming what you already know.
Most mid-market CEOs who read this far already know the answer. The question isn’t whether their legacy systems are costing them. It’s whether the cost has crossed the threshold where acting is less risky than not acting.
Seven signs your legacy system has become a growth constraint
Check how many of these are true for your organization right now:
Your AI strategy has stalled at the proof-of-concept stage. The demos worked. Production integration failed or was never attempted. No one wants to say why.
Your engineering team spends more time on maintenance than on new features. Ask them. If the answer is “we spend about half our time keeping things running,” you already know the number; it’s likely higher.
A single developer holds irreplaceable knowledge of a critical system. If that person resigned tomorrow, how long before you’d feel the impact? How long before it became a crisis?
Your reporting team exports data to spreadsheets to get answers. If your systems can’t answer basic operational questions without manual extraction and manipulation, your data architecture is blocking your decision-making.
You’ve been told that an AI feature “can’t be integrated” with your current system. This is the diagnosis the system itself gives you. It’s accurate.
You’ve had an incident in the last 12 months that required emergency vendor involvement to resolve. One incident is a warning. Two is a pattern.
You’ve delayed a product, feature, or strategic initiative because the underlying system couldn’t support it. This is the clearest signal. The system is now your strategic constraint.
A self-assessment for mid-market executives
If three or more of those are true, you’re past the point of evaluating whether to modernize. You’re at the point of evaluating how, and with whom.
The “how” question has already been answered in this article: incremental, AI-augmented, documentation-first. Not a rip-and-replace gamble. Not indefinite patching.
The “with whom” question is what a 90-day starting point is designed to answer. Not through a sales process. Through delivered work.
If you’re seeing yourself in this list, the conversation worth having isn’t about transformation. It’s about which component to address first, what you should own at the end of the first 90 days, and what a partner who stays actually commits to.
The market data points in one direction. Legacy debt compounds. AI advantages compound. The gap between companies that modernize in 2026 and those that wait will be measurably larger by 2027, and will keep growing.
The 2026 window is real. The question is whether you use it.
Ready to Find Your 90-Day Starting Point?
Most of our clients don’t start with a 3-year roadmap. They start with a question: “Which part of our system is costing us the most right now?”
That’s the right question. We can help you answer it, with a concrete assessment of your current systems, a prioritized modernization roadmap, and a clear picture of what the first 90 days look like before you commit to anything longer.
What are the benefits of updating legacy systems with AI?
AI-assisted modernization compresses timelines by 40–50% by automating legacy code analysis, documentation, and test generation. Beyond speed, it produces cleaner architecture, full documentation, and systems that can accept AI integrations, converting your legacy infrastructure from an AI blocker into an AI foundation.
Is replacing a legacy system worth it?
For most mid-market companies, a full replacement is too risky. The ROI of incremental, AI-augmented modernization is stronger: lower upfront cost, no operational disruption, and each phase delivers working improvements. According to Garnet Grid, technical debt costs a 20-person engineering team $3.6M annually. That’s the baseline cost of doing nothing.
Are legacy systems expensive?
Yes. According to ADEVS Tech Journal (February 2026), 60–70% of total software spend goes to maintenance on existing systems, not innovation. The direct costs compound with the opportunity cost of AI initiatives that can’t run on legacy infrastructure.
What are the disadvantages of legacy systems?
Legacy systems create four compounding problems: they consume 60–70% of software budgets in maintenance; they block AI integration because they lack the API architecture AI requires; they create key-person dependency when institutional knowledge lives with one or two developers; and they fall further behind each quarter.
Is it worth modernizing your legacy codebase?
Yes, if done incrementally and with complete documentation transfer as a deliverable. The cost of staying on legacy systems is high and growing. The question isn’t whether to modernize, it’s whether to do it in a way that doesn’t risk the business you’re currently running.
The demo looked great. Your team wired up an AI agent in a staging environment, it called the right endpoints, processed the right data, and did exactly what the vendor promised. Then someone said, “Let’s run this in production.” And everything stopped.
That’s not an AI problem. It’s an infrastructure problem. AI agents require three things your legacy stack almost certainly doesn’t have: clean data contracts, observable system state, and an integration-ready architecture. When those three ingredients are missing, no model, however capable, can operate reliably in your environment. The agent doesn’t fail because it’s bad at reasoning. It fails because it’s driving blind through undocumented systems with inconsistent data and no way to recover from errors it can’t see.
This guide explains exactly what AI agents need, where legacy stacks fall short, and the incremental path forward that doesn’t require halting your current roadmap.
Quick answer: Why AI agents fail on legacy stacks
AI agents require clean data contracts, observable systems, and integration-ready architecture; most legacy stacks have none of these.
The failure point lies in the infrastructure, not the AI model itself.
According to IDC, only 4 of every 33 AI pilots ever reach production, an 88% failure rate.
The fix is incremental: establish data contracts, add observability, and rationalize documentation, in that order.
Mid-market teams cannot halt their roadmap for a complete rewrite. A phased approach with a dedicated partner is the way to achieve it.
Your AI Agent Demo Worked. Your Production Environment Will Not.
The production failure isn’t a surprise; it’s predictable. Here’s why it keeps happening, and what the controlled POC environment is hiding from you.
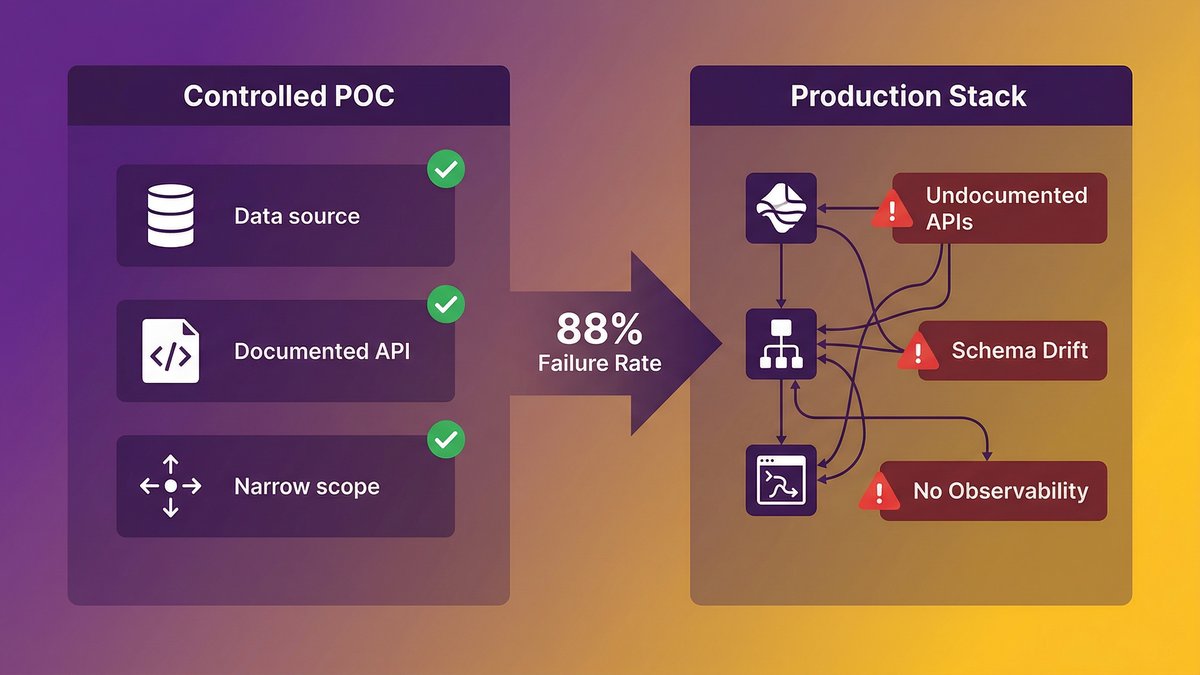
The gap between a controlled POC and your actual stack
A proof-of-concept (POC) environment is engineered to succeed. You pick a data source that’s reasonably clean, point the agent at a well-documented internal API, and keep the scope narrow enough that nothing breaks. That environment has almost nothing in common with your actual production stack.
Production environments carry 10–15 years of accumulated decisions, three generations of engineers, two ERP upgrades that never fully retired the old system, and a dozen internal APIs documented only in the heads of whoever built them. An AI agent navigating that environment isn’t doing the same job as an agent operating in a controlled sandbox. It’s operating inside a system that was never designed for autonomous traversal, with data that means different things in different places, and with no reliable way to signal when something has gone wrong.
The POC succeeded because you created the conditions for it to succeed. That’s not a failure of the demo; it’s a failure of the evaluation design.
According to Deloitte (2025), nearly 60% of AI leaders identify legacy-system integration as the primary barrier to agentic AI adoption. The problem isn’t a knowledge gap about what AI can do. It’s a structural gap between what AI agents need and what most enterprise stacks provide.
Why 88% of AI pilots never reach production
According to IDC research, for every 33 AI pilots launched, only 4 reach production, an 88% failure rate. That number is striking. But it’s not surprising once you understand what’s happening at the infrastructure layer.
POC environments abstract away the exact problems that kill production deployments: messy data, undocumented systems, brittle integrations, and missing observability. You’ve proven the model can do the job. You haven’t proven your infrastructure can support it doing the job at scale, under load, in an environment it can’t fully see.
The agent isn’t the variable. Your stack is.
What AI Agents Actually Require to Function at Scale
AI agents need three specific infrastructure capabilities before they can operate reliably in any environment. Here’s what each one means technically and why its absence causes production failure.
Clean data contracts: structured interfaces, not just any API endpoint
A data contract is a formal, versioned agreement about what data looks like at a system boundary, field names, data types, expected ranges, null handling, and update frequency. An AI agent issuing a tool call to retrieve customer order history needs to know the format it’ll receive back. If the response schema changes, even slightly, the agent’s reasoning can break in ways that are hard to detect and harder to debug.
Most legacy stacks don’t have data contracts. They have APIs that work, most of the time, for the people who built them. That’s a different thing. “Works for the team that built it” is not a contract. It’s institutional knowledge encoded into production behavior.
Clean data contracts mean the agent can call a tool, receive a predictable response, and take reliable action based on what it receives. Without them, you’re asking the agent to reason against an interface that shifts under its feet.
Observable systems: agents fail silently without a traceable state
Observability means you can answer three questions about any system component at any time: what is it doing, what state is it in, and when did that state last change. In a traditional user-facing application, a failure produces a visible error or an alert. An AI agent failing silently in a poorly observable system produces something worse: confident wrong answers.
If an agent calls an internal service and receives a stale cache response, it doesn’t know the data is three hours old. If an integration layer drops a message during high load, the agent doesn’t know the downstream action never completed. The agent continues reasoning as if its information is accurate, and the damage compounds.
Observable systems give agents the ground truth they need to detect anomalies, surface errors upstream, and stop rather than act on bad data.
Integration-ready architecture: what ‘agentic-ready’ means technically
An integration-ready architecture is one where services expose stable, callable tool endpoints; data flows through a layer that enforces consistency rather than around it; and access control is granular enough to let an agent take specific actions without requiring blanket system access.
Most legacy architectures weren’t designed with this model in mind. Integrations were built point-to-point, one-off, for specific use cases. The result is a web of dependencies that’s fragile, hard to extend, and nearly impossible for an autonomous agent to navigate without breaking something.
“Agentic-ready” isn’t a vendor marketing term. It’s a technical description of an architecture that supports autonomous system traversal without causing cascading failures.
The Legacy Stack Anatomy: Where AI Agents Break Down
Most legacy stacks fail AI agents in three specific places. Knowing which applies to your environment tells you where to start.
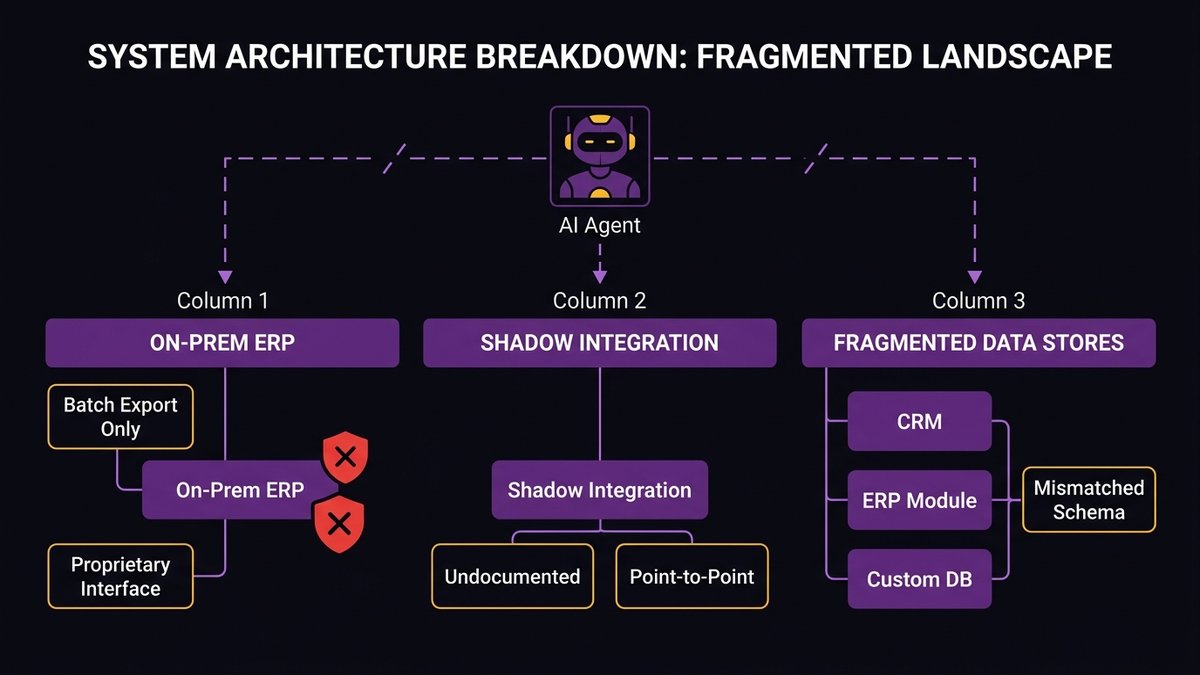
On-prem ERPs without modern APIs
On-premise ERP systems, especially those 10+ years old, were designed for deterministic, sequential workflows executed by human users. They expose data through batch exports, proprietary interfaces, or fragile middleware that was duct-taped together during a previous integration project.
An AI agent trying to query an on-prem ERP for live inventory data, update a purchase order, or retrieve customer history is working against a system that was never designed to be called programmatically at scale. The integration points exist, but they’re brittle, poorly documented, and not built to handle the query patterns that agentic workflows produce.
According to Forrester (2025), 70% of digital transformations are slowed by legacy infrastructure. On-prem ERPs are a primary reason.
Undocumented internal services and shadow integrations
Every mid-market company has them: internal APIs or services that were built by one engineer, used by one team, and never formally documented. They work. But “they work” means “the engineer who built them knows how to use them.” Anyone else, including an AI agent, is operating from guesswork.
Shadow integrations are worse. These are point-to-point data flows that exist outside the main integration layer, usually built by a team that needed something the official system didn’t provide. They’re often stateful, often undocumented, and often load-bearing. An AI agent encountering a shadow integration it can’t traverse will either fail silently or produce actions based on incomplete information.
Fragmented data stores with inconsistent schemas
A mid-market company running for 10+ years typically has customer data in at least three places: the original CRM, the ERP’s customer module, and a database built for a specific product or reporting workflow. The “customer ID” field in each system may refer to different things. Addresses may be formatted differently. Status fields may use different value sets.
For a human, this is annoying but manageable. For an AI agent, it’s a semantic landmine. The agent’s reasoning depends on consistent meaning across the data it processes. When the same concept carries different representations in different systems, the agent’s conclusions can be confidently, systematically wrong.
Why Most Agentic AI Initiatives Stall, And It’s Not the Model
The root cause of agentic AI stalls is architectural mismatch, not model quality. The evidence is consistent across industries and company sizes.
Integration complexity: 42% of enterprises need 8+ data sources for agents to function
According to Arion Research (2026), 42% of enterprises need access to 8 or more data sources to deploy AI agents successfully. That’s not 8 APIs in a clean microservices architecture, that’s 8 data stores that may have different schemas, different access patterns, and different consistency guarantees. Building the integration layer to support that data access cleanly is foundational work. Without it, agents either operate on partial information or require extensive manual preprocessing that defeats the purpose of automation.
According to ITBrief (2026), 57% of enterprises remain in a pilot stage for agentic AI, while only 15% have operationalized agents at scale. The pattern is consistent: pilots work in contained environments; production deployments stall at the integration layer.
The non-determinism mismatch: legacy systems are deterministic; agents are not
Legacy systems were designed for deterministic execution: input A always produces output B. Workflows are sequential, state is managed explicitly, and failures produce clear error codes. An AI agent operating in this environment introduces non-determinism; the agent decides dynamically what action to take based on reasoning, not a fixed flowchart.
Legacy systems weren’t built to handle this. They have no mechanism for an external actor to issue arbitrary tool calls in arbitrary sequences. They have no way to validate that the agent’s intended action is safe before executing it. They have no rollback path if the agent reasons incorrectly.
This isn’t a model problem. It’s an architecture problem. Non-deterministic agents require architectures designed for non-determinism: idempotent operations, reversible actions, and explicit state management.
Compliance and access control gaps that block autonomous execution
Most enterprise access control systems were designed for human users operating through a defined UI. Agent access is fundamentally different: programmatic, potentially high-frequency, and potentially cross-system. The access control model that works for a finance analyst using a dashboard doesn’t work for an agent that needs to read from five systems, write to two, and chain those operations into a single workflow.
This is a compliance risk, not just a technical inconvenience. An agent operating with overly broad access is an audit liability. An agent operating with overly narrow access can’t complete its task. The right answer, granular, task-scoped permissions per agent operation, requires an access control architecture that most legacy systems don’t have.
The Documentation Debt Problem: Agents Can’t Navigate What Isn’t Written Down
This is the gap no competitor covers. Documentation debt directly blocks AI agent deployment, and it’s the most invisible problem on most legacy stacks.
How undocumented systems block autonomous agent traversal
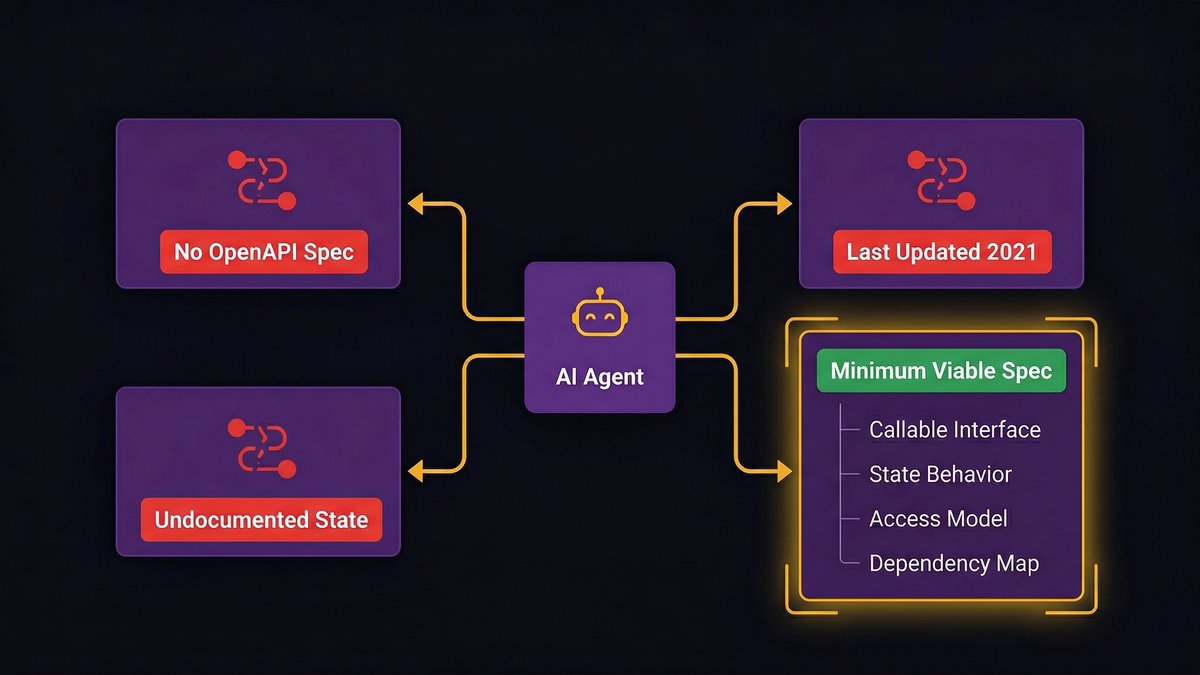
An AI agent navigating your internal systems needs to know what those systems do, what they accept as input, what they return, and what side effects their operations produce. That knowledge has to exist somewhere the agent can access it, in API documentation, OpenAPI specs, system descriptions, or structured tool definitions.
Most mid-market legacy stacks have critical services that exist only in production, documented only in the muscle memory of the engineers who built them. There are no OpenAPI specs. There’s a Confluence page last updated in 2021. There’s a Slack thread from 2019 where someone asked a question that was never fully answered.
An agent trying to traverse an undocumented service faces one of two outcomes: it hallucinates behavior based on partial information, or it fails. Neither is acceptable in a production workflow. The documentation isn’t the nice-to-have that gets done after the real work. It’s a prerequisite.
What system documentation an agentic environment actually needs
For an AI agent to operate reliably on a system, that system needs four things documented:
Callable interface specification, what endpoints or functions the agent can invoke, with input/output schemas
State behavior, what the system’s state looks like before and after each operation, including error states
Access and authorization model, what credentials are required, what scope is granted, and what actions each scope permits
Dependency map, what other systems this service calls, what it depends on, and what happens when those dependencies are unavailable
This isn’t enterprise documentation theater. It’s the minimum viable surface area for an agent to reason about a system without guessing.
How to Assess Your Stack’s Agentic Readiness Before Spending on AI Tooling
Before you buy agent orchestration platforms, evaluate this. The assessment takes less time than a vendor demo and tells you whether you’re ready to deploy agents at all.
A four-factor readiness checklist: APIs, data quality, observability, documentation
Run your stack against these four dimensions:
1. API coverage and stability – Do your core business systems expose stable, versioned APIs? – Are those APIs documented in a machine-readable format (OpenAPI/Swagger)? – Have the APIs changed in the past 12 months without a versioning strategy?
If your answer to the third question is “yes, and we didn’t version it,” your APIs aren’t stable enough for agent use.
2. Data quality and schema consistency – Do the same data concepts, customer, product, order, mean the same thing across systems? – Are there canonical data definitions that all systems adhere to, or are schemas defined per-system? – Is there a data dictionary, even an informal one?
If your engineering team can’t agree on what a “customer ID” refers to across systems, agents will compound that disagreement at scale.
3. Observability and traceability – Can you trace the execution path of any system call end-to-end? – Do your services emit structured logs that capture state changes? – Do you have alerting on service degradation, not just outright failure?
An agent operating in an unobservable system is a black box inside a black box. Production incidents become impossible to diagnose.
4. Documentation coverage – What percentage of your internal services have current, accurate API documentation? – What percentage of your internal services are documented only in someone’s head? – When was your system architecture documentation last updated?
Be honest with the last question. “Last updated when the system was built” means it’s out of date.
Red flags that indicate your stack will block agent deployment
Some patterns are unambiguous blockers. If your stack shows any of these, agents will fail, and the failure will be expensive to diagnose:
Point-to-point integrations with no abstraction layer, the integration breaks if either endpoint changes, and agents can’t navigate point-to-point webs reliably
Batch-only data access, agents need near-real-time data; batch exports introduce staleness that breaks agent reasoning
No structured error responses, if your services return HTML error pages or unstructured text on failure, agents can’t handle errors gracefully
Overly permissive service accounts, if the only way to access a service is with an account that has full admin rights, deploying an agent means deploying a full admin into production
According to McKinsey (2025), 62% of organizations experiment with AI agents, yet only 23% successfully scale them. The gap between 62% and 23% lives in exactly these infrastructure gaps.
The Modernization Path: Building an Agentic-Ready Foundation
The path to agentic readiness is incremental, not a rewrite. Three steps, in this order.
As Cesar DOnofrio, CEO and co-founder of Making Sense, states: “When legacy systems limit access to reliable data, slow down integration across workflows, or make change deployment complex and time-consuming, AI initiatives stop being strategic levers and become isolated experiments.”
That’s the problem. Here’s the sequence to fix it.
Step 1: Establish data contracts and API standards
Start with the systems your intended AI agents will actually touch, not your entire stack. Identify the three to five services that represent the highest-value automation opportunity and define data contracts for each:
Formalize the input/output schema for every endpoint agents will call
Build a thin API gateway or abstraction layer over legacy services that lack stable interfaces, the abstraction layer is what the agent calls; the legacy system sits behind it
This is not a 12-month initiative. For three targeted services, a small team can produce usable data contracts in six to eight weeks. You’re not rewriting the system, you’re defining its interface.
Step 2: Add observability and system traceability
Before you deploy agents, instrument the systems they’ll operate on:
Add structured logging to every service in the agent’s execution path, capture inputs, outputs, state changes, and error conditions
Set up distributed tracing so you can follow a single agent-initiated workflow across multiple service calls
Observability isn’t optional. It’s the difference between a production incident that takes four hours to diagnose and one that takes 20 minutes. Deploy agents without it and you’ll spend more time firefighting than the agents save.
Step 3: Incrementally document and rationalize legacy services
Documentation debt compounds. Each undocumented service is a blocker for every future AI agent that might need to interact with it. The solution isn’t a documentation sprint, it’s a documentation discipline built into ongoing engineering work:
Every service that enters an agent’s scope gets a minimum viable spec: callable interface, state behavior, access model, dependency map
Engineers working on legacy services document as they go, not at the end of the project
Shadow integrations get inventoried, documented, and either formalized or eliminated
This is where an AI-augmented development process produces a compounding advantage. Nexa’s engineering workflow produces system documentation as a standard deliverable on every engagement, not as an after-the-fact artifact, but as part of the development cycle itself. That means systems built or modernized under Nexa’s model arrive with the documentation agentic deployments need. Find out more on the AI-augmented SDLC blog post
Why Mid-Market CTOs Need a Different Modernization Model Than Enterprise
Enterprise companies fix this problem by hiring. Mid-market companies can’t. That’s a different constraint, and it demands a different solution.
The talent and capacity constraint: you can’t halt your roadmap for a 2-year rewrite
A Series B SaaS company with 8 engineers carrying a legacy ERP, a live product roadmap, and a growing list of integration requests has a specific problem: there’s no bandwidth to simultaneously maintain current operations and build the agentic-ready foundation. The engineers who know the legacy systems are the same engineers the product roadmap depends on. You can’t pull them off to do modernization work without the product stalling.
A large enterprise can staff a parallel modernization team. It can absorb an 18-month runway on infrastructure investment. It can tolerate the velocity hit while the foundation gets rebuilt. Most mid-market companies can’t do any of those things.
This is not a weakness, it’s a constraint that defines the right approach. The right model for mid-market isn’t a full rewrite. It’s incremental modernization scoped to the highest-value AI use cases, executed in parallel with the ongoing roadmap, producing usable outputs at each phase rather than a single big-bang delivery at the end.
AI-augmented nearshore teams as a force multiplier for legacy modernization
The nearshore model exists precisely to solve the capacity constraint. A dedicated team of senior engineers, operating in your timezone, integrated into your Scrum workflow, can absorb the legacy modernization work that your internal team can’t pick up without stalling the product.
AI-augmented delivery accelerates this further. The same AI-native process that produces clean documentation as a standard output also reduces the time required to understand, assess, and modernize legacy systems. What would take a traditional team 12 months can take an AI-augmented team significantly less. Not because the underlying complexity is different, but because the tooling surfaces that complexity faster, generates the specifications and tests that legacy systems lack, and produces documentation continuously rather than at project close.
Nearshore is not outsourcing. It’s not a vendor that disappears after delivery. Done correctly, it’s an embedded engineering partnership that accumulates institutional knowledge about your systems, the antidote to the key-person dependency that makes legacy modernization so risky in the first place.
If you want to know where your stack stands against the four agentic readiness factors, it starts with exactly that diagnostic. Most CTOs who’ve run one come out with a shorter list of actual blockers than they expected, and a clearer roadmap for removing them.
The Bottom Line
Most CTOs I talk to already know their stack isn’t ready for AI agents. What they’re looking for isn’t a diagnosis, it’s a path forward that doesn’t require pausing everything else to build it.
The path exists. It’s incremental, it’s scoped to the highest-value use cases first, and it produces agentic-ready infrastructure in phases rather than as a single 18-month delivery. The companies that figure this out in 2026 will have a durable advantage over the ones still running pilots in 2027.
Your infrastructure is the variable. Fix that, and the agents work.
Ready to find out exactly where your stack stands?Book a software architecture assessment with Nexa Devs, and we’ll map your environment against the four agentic readiness factors and tell you what needs to change before you spend another dollar on AI tooling.
FAQ
Can AI agents work with legacy systems without a full rewrite?
Yes, but only if specific infrastructure prerequisites are in place first. AI agents need stable API interfaces, observable system state, and documented data contracts. You can build an abstraction layer over legacy systems without rewriting the underlying system. A full rewrite is rarely necessary.
What infrastructure do you need before deploying AI agents in the enterprise?
Three things: clean data contracts (formal, versioned schemas at system boundaries), observable systems (structured logging, distributed tracing, error alerting), and an integration-ready architecture with stable, callable endpoints and granular access control. Missing any one of these causes production failures that are difficult to diagnose.
Why do AI agents fail in production when the demos worked fine?
POC environments are controlled, clean data, documented APIs, narrow scope. Production carries years of complexity: undocumented services, inconsistent schemas, brittle integrations. According to IDC, only 4 of every 33 AI pilots reach production. The demo succeeded because conditions were engineered for success, not because the stack was ready.
How do you assess whether your tech stack is ready for agentic AI?
Evaluate four factors: API coverage and stability, data schema consistency across systems, observability and traceability, and documentation coverage. Red flags include point-to-point integrations, batch-only data access, unstructured error responses, and overly permissive service accounts.
What is the biggest barrier to scaling AI agents in mid-market companies?
Infrastructure, not model capability. According to Deloitte (2025), nearly 60% of AI leaders identify legacy-system integration as the primary barrier to agentic AI adoption. For mid-market companies, the compounding constraint is bandwidth: engineers who know legacy systems are the same ones carrying the product roadmap.
How do undocumented APIs and legacy codebases block AI agent deployment?
An AI agent navigating an undocumented system has no reliable interface specification, no state behavior to reason against, and no dependency map to avoid breaking. It either hallucinates behavior from partial information or fails. Documentation is a deployment prerequisite, not a post-project deliverable.
AI-Augmented SDLC: How the Dev Lifecycle Is Collapsing Into Continuous Flow
The traditional software development lifecycle was designed around human speed. Requirements take weeks because people need time to debate, draft, and revise. Code review takes days because engineers are context-switching between five other things. Testing is a phase at the end because running a full suite used to take hours and required dedicated QA time to interpret results.
AI doesn’t work at human speed. It drafts requirements in minutes. It reviews pull requests as they’re opened. It continuously generates and runs test suites. When you embed AI at that level, something structural changes: the phases that were separated by time start to overlap. The AI-augmented SDLC isn’t just a faster version of the old process. It’s a different shape.
The SDLC Was Never Designed for AI: And It Shows
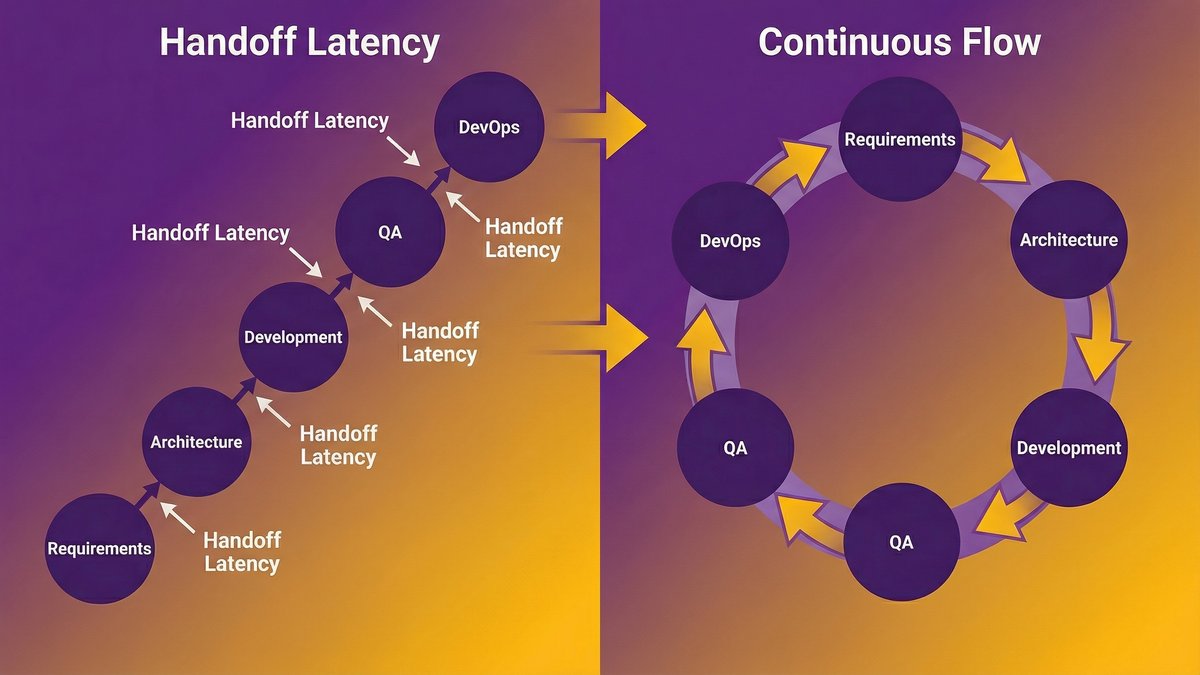
Phase handoffs in the traditional SDLC weren’t a design philosophy. They were a concession to human limitations.
A requirements document gets written, then handed to architects, then handed to developers, then handed to QA, then handed to DevOps. Each handoff exists because each group needs time: to read, to process, to schedule, to act. The latency between phases isn’t inherent to building software. It’s inherent to coordinating humans across a sequential process.
AI removes most of that latency. An AI agent can read a spec file and scaffold a code structure in the time it takes a developer to brew coffee. A code review agent can flag issues as soon as a commit is pushed. A test generation tool can write unit tests alongside the code that triggers them. The “handoff” between requirements and development doesn’t need to be a gate anymore. It can be continuous.
That’s where most SDLC frameworks are breaking. They weren’t built for a world where the work between phases takes minutes. The process assumes days, sometimes weeks, between each stage. When you compress the work that justified those gaps, the gaps themselves become the bottleneck.
Phase handoffs were built for human latency, not machine speed
Consider the sprint review. It exists because human developers need a checkpoint: a moment to step back, assess what shipped, and plan what comes next. That rhythm makes sense when the work between checkpoints took two weeks of focused human effort.
Now consider what happens when AI agents can generate 60–70% of the code in that sprint, run test coverage automatically, and flag architectural drift against the spec file in real time. The two-week sprint isn’t accelerating the work. It’s imposing a human-paced structure onto a process that no longer operates at human pace.
Where the friction lives: requirements to code, code to review, review to deploy
The highest-friction handoffs in the traditional SDLC are exactly the ones AI handles best: translating ambiguous requirements into structured specs, checking code against those specs, and validating that tested code is safe to ship. These aren’t coordination problems between humans anymore. They’re tasks that AI tools now run continuously in the background.
The CTO who wants to capture that value doesn’t need better tools. They need a delivery model designed to run without the handoff gaps those tools were originally built to bridge.
What AI Is Actually Doing to Each SDLC Phase
AI isn’t transforming the SDLC as a whole. It’s compressing specific tasks within each phase, and the cumulative effect of that compression is restructuring the sequence.
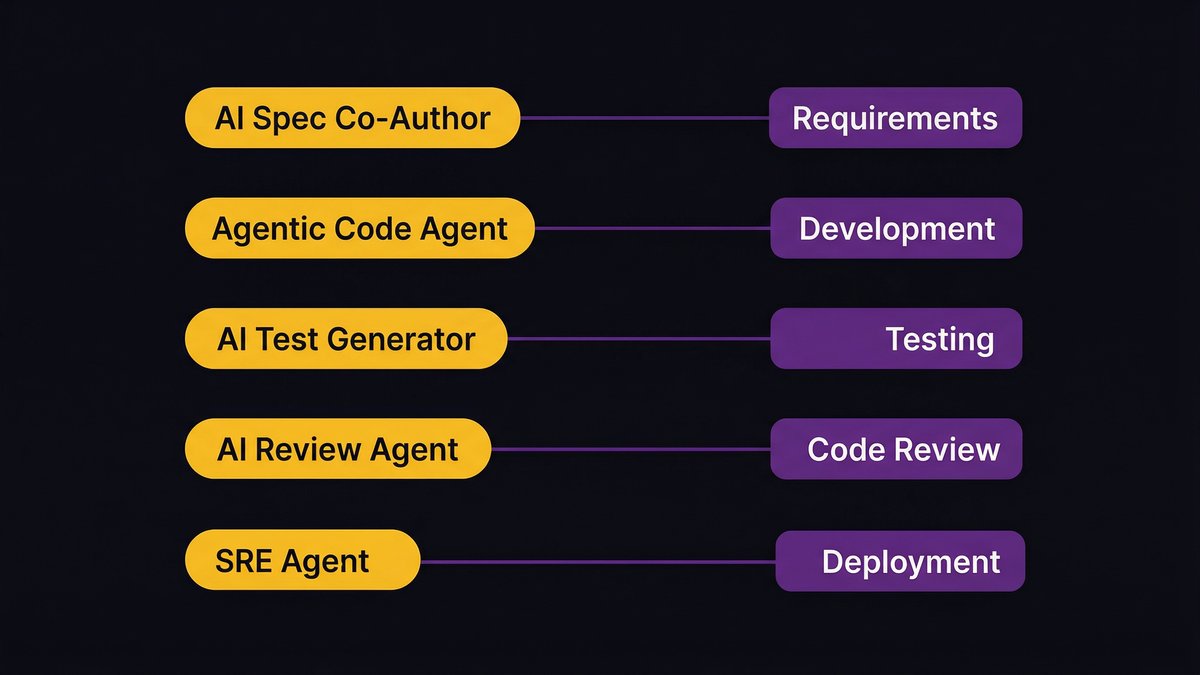
Requirements and planning: AI as spec co-author
The slowest part of requirements gathering has always been translation: turning a business problem described in operational language into a technical spec written in engineering language. AI bridges that gap directly.
Microsoft’s engineering teams now use spec-driven development where AI agents generate service blueprints and code scaffolds from requirements before a human developer opens a file. According to the Microsoft Azure blog (2026), the AI can produce a comprehensive requirements list, service blueprint, and initial code scaffold “before I’ve opened Notepad and started to decipher requirements.” That’s not a productivity gain within the old process. That’s the requirements phase and the initial development phase starting to merge.
Sprint planning follows the same pattern. AI-assisted story generation, effort estimation, and task breakdown reduce planning cycles from days to hours.
Development: from copilot assist to autonomous code agents
The copilot phase: AI suggesting completions while a developer types, is already giving way to agentic coding, where AI agents handle self-contained tasks with minimal human direction. According to Forrester (2026), agentic software development represents “the next phase of AI-driven engineering tools,” where AI agents can “plan, generate, modify, test, and explain software artifacts” end to end.
The implication for the SDLC isn’t faster typing. It’s that development is no longer a purely sequential process where one thing gets built before the next thing gets designed. Agentic systems can work across multiple components in parallel, within guardrails defined by the spec.
Testing and review: AI-generated test suites and agent-assisted code review
Testing is shifting from a post-development phase to a continuous practice. Nexa Devs builds AI-generated unit and integration tests alongside code delivery as a standard practice in every sprint, rather than as a separate end-phase. The effect is significant: according to the Qodo 2025 AI Code Quality Report, AI-assisted code reviews led to quality improvements in 81% of cases, compared to 55% with traditional review processes.
Code review is the same story. According to a 2026 Atlassian RovoDev study, 38.7% of comments left by AI agents in code reviews lead to additional code fixes. That’s not a reviewer being replaced. That’s the review cycle running faster and generating more actionable signals per pass.
Deployment and operations: agentic SRE and continuous observability
The final phase is moving in the same direction. SRE agents now handle proactive day-2 operations: monitoring for anomalies, analyzing logs for root cause, and surfacing triage information before a human is paged. Microsoft’s AI-led SDLC framework includes a dedicated “SRE Agent” step in its production model, framing it not as a support function but as a full phase of the delivery loop.
Deployment itself is increasingly deterministic and automated. The human judgment required at the gate between “tested code” and “deployed code” narrows when AI testing coverage is high, and deployment pipelines have tight validation gates.
Why Compressing Phases Eventually Eliminates the Handoffs Between Them
This is the structural argument most SDLC articles miss. Compressing work within phases is one thing. But the AI-augmented SDLC doesn’t just speed up each phase. It removes the reason the handoffs existed in the first place.
Wix CTO (Even-Haim Yaniv): Articulated that AI moves engineering focus from managing handover “handoffs” to AI-native, end-to-end ownership where frontend, backend, and mobile boundaries disappear.
The latency handoff: what takes time when AI handles the work
A handoff in the traditional SDLC has two components: the transfer of context (briefing the next team on what the previous team produced) and the wait time before the next team can act (scheduling, prioritization, capacity).
AI handles both. An agent consuming a spec file doesn’t need a briefing meeting. It reads the artifact directly. An agent that’s monitoring a CI pipeline doesn’t need to be scheduled. It acts when the trigger fires. The asynchronous, human-coordinated handoff collapses into a synchronous, machine-executed transition.
Stack Overflow losing 77% of new questions since 2022 isn’t just a statistic about AI coding tools gaining adoption. It signals that the “I don’t know how to do this next step” pause: the moment that used to generate a handoff, a Slack thread, or a Stack Overflow question, is disappearing from the development loop.
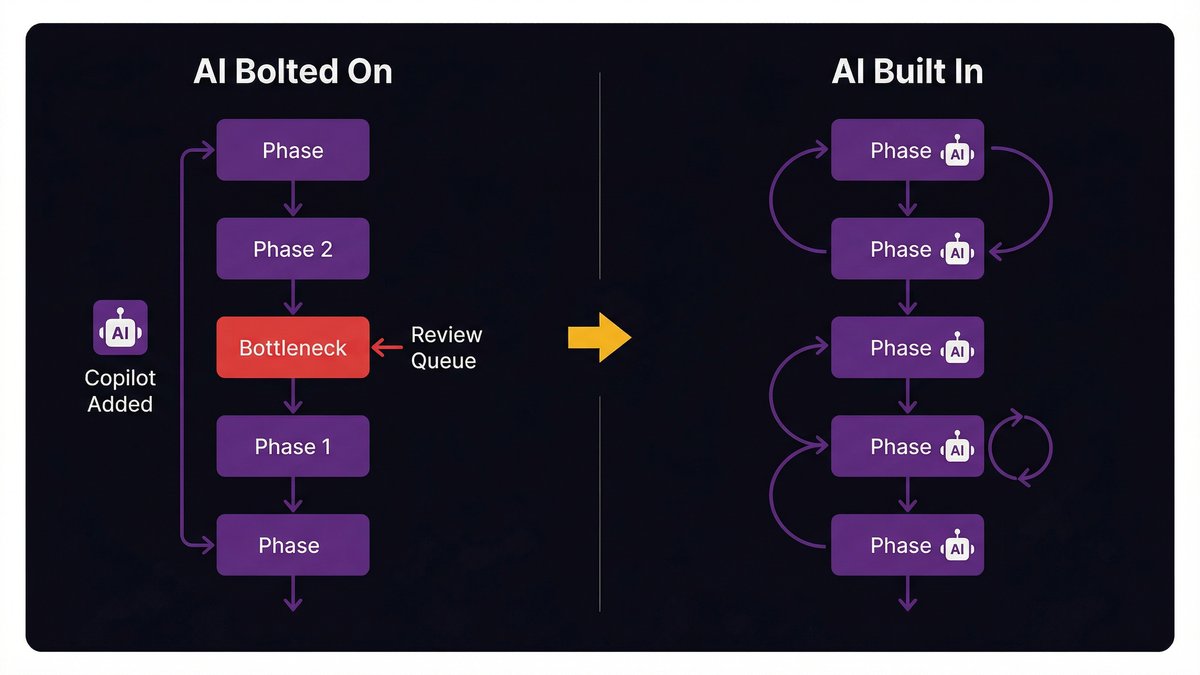
Continuous flow as an emergent property, not a process redesign
Here’s the important distinction: continuous flow in an AI-native SDLC isn’t a methodology you adopt. It’s what emerges when you remove the latency that made sequential phases necessary.
You don’t need to redesign your sprint structure. You need to embed AI deeply enough in each phase that the time between phases compresses on its own. When requirements and scaffolding happen in the same tool, when code and tests are written together, when deployment gates close automatically on quality signals, the “waterfall-inspired” sequence doesn’t need to be dismantled. It dissolves.
That’s a fundamentally different framing than “agile at scale” or “DevOps maturity.” It’s not about process redesign. It’s about what process structure survives when AI is doing the work that made each step take as long as it did.
The Productivity Gap: Why Most Teams Aren’t Seeing It
Here’s the uncomfortable reality: most teams have AI tools. Most aren’t seeing continuous flow.
According to research cited by ShiftMag (2026), 92.6% of developers now use AI coding assistants. Yet productivity gains across organizations remain around 10%. The tools are everywhere. The transformation isn’t.
AI bolted on vs. AI built in: the architecture difference
Adding GitHub Copilot to a team that runs a traditional two-week sprint with a separate QA phase and a manual deployment process does not produce an AI-augmented SDLC. It produces a traditional SDLC with a faster typing speed. The phase gates are still there. The handoff latency is still there. The sequential bottlenecks are still there.
The distinction matters for CTOs because “we’ve adopted AI tools” is not the same claim as “our delivery model is designed around AI.” The first is a tool purchase. The second is an architectural decision about how software gets built, how teams are structured, and how phases relate to each other.
Why 93% AI adoption can still yield only 10% productivity gain
Consider a concrete example. A development team adopts an AI code generation tool. The developers write code faster. But the code still goes into a review queue managed by two senior engineers who are bottlenecked. The faster-written code waits in the same queue as before. The cycle time doesn’t improve because the bottleneck isn’t code generation. It’s review throughput.
This is what McKinsey means when their research finds AI can improve developer productivity by up to 45%: it requires the entire delivery model to be redesigned around AI tooling, not just the individual task layer. According to McKinsey (cited by Ciklum, 2026), that 45% figure assumes AI is structurally embedded in the delivery process. Add a copilot to a broken handoff structure, and you get a faster arrival at the same queue.
The teams capturing real gains aren’t the ones with the most AI tools. They’re the ones whose delivery model was designed with AI in every phase from the start.
What an AI-Native Delivery Model Actually Looks Like
This is what changes when AI is built in rather than bolted on.
Team structure when phases collapse: roles, rituals, and sprint redesign
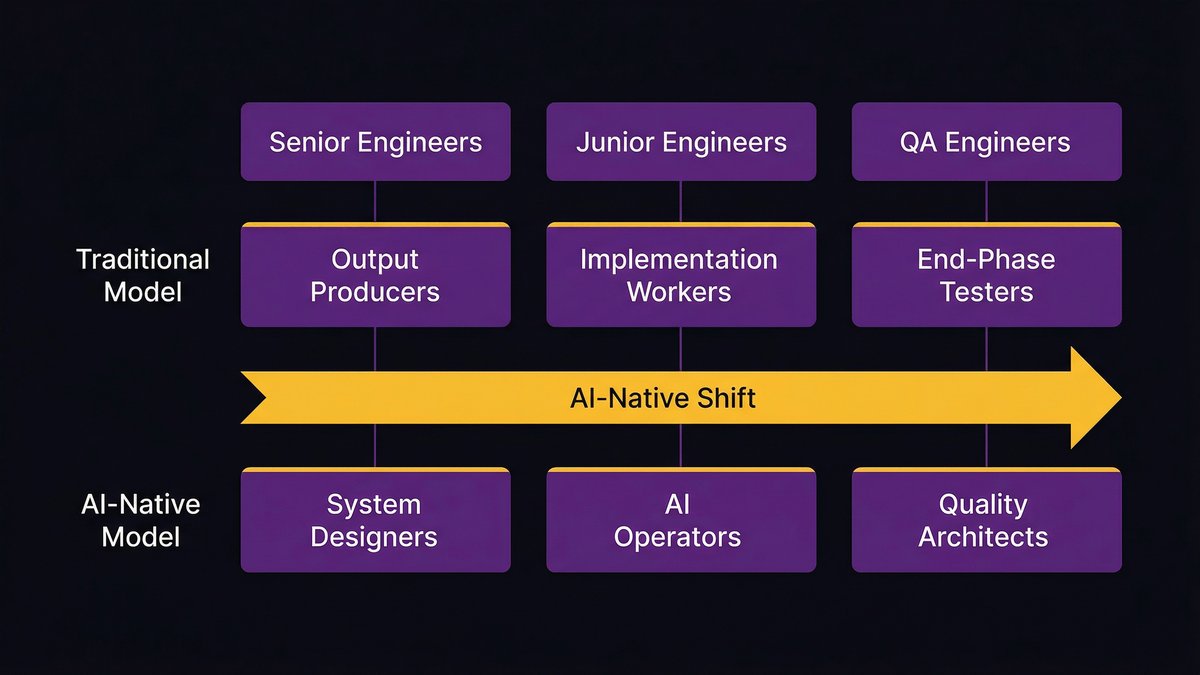
When AI handles spec translation, test generation, code review signals, and deployment validation, the engineering roles that existed to manage those handoffs change. Not disappear, but change.
Senior engineers shift from “output producers” to “system designers”: defining the spec files and architectural guardrails that AI agents work within. Junior engineers shift from “implementation workers” to “AI operators”: directing agents, reviewing outputs, and catching the cases where the agent misreads the intent. QA engineers become quality architects: designing the testing strategy and coverage criteria against which the AI-generated tests are built.
The sprint doesn’t disappear either. But it’s no longer structured around “what gets built this sprint.” It’s structured around “what gets verified and shipped this sprint.” The work that used to take most of the sprint happens in hours. The sprint time that remains goes to integration, validation, and the genuinely hard architectural decisions that AI can’t resolve.
The toolchain layer: what gets embedded at each phase vs. what stays human
Not every task in the SDLC is a good AI candidate. The ones that are: well-defined, pattern-based, repetitive, and tolerance-sensitive (code generation, test writing, deployment validation, log analysis). The ones that aren’t: novel architectural decisions, ambiguous product requirements that need stakeholder negotiation, security threat modeling that requires context AI doesn’t have.
The practical question for a CTO isn’t “which AI tools should we buy?” It’s “which specific tasks in our delivery model are AI-executable, and how do we restructure the process so those tasks run as background jobs rather than as sequential handoffs?”
Nexa Devs’ delivery model is built around this distinction. Every sprint phase has AI tooling embedded at the task level. The human work is explicitly structured around the decisions AI can’t make. The result is a delivery model where AI handles what AI handles well, and engineers handle what engineers handle well, with no process overhead bridging the two.
Running Modernization and AI Embedding in Parallel
The CTO reading this might be thinking: “Our stack isn’t ready for this. We’ve got legacy systems, undocumented services, and a monolith we’ve been meaning to decompose for three years.”
That’s not a blocker. It’s the starting point.
Why you don’t need a fully modernized stack to start
According to MIT’s State of AI in Business 2025, 95% of enterprise AI pilots fail to produce measurable ROI. The most common explanation is that organizations try to finish their modernization work before embedding AI, treating them as sequential initiatives. Modernize first, then add AI.
That sequence is wrong. The modernization work is slow, expensive, and produces business value only at the end. Embedding AI in the phases that are already running, right now, produces value immediately while the modernization work happens in parallel. You don’t need a clean microservices architecture to get AI-assisted code review on the services you’re building today. You don’t need a fully documented legacy system to use AI-generated tests on new feature development.
The incremental embedding approach: phase-by-phase AI activation
Start with the phase that has the clearest, most self-contained AI application in your current process. For most teams, that’s code review or test generation. Embed AI tooling at that specific task. Measure the cycle time before and after. Then move to the next phase.
Each phase you embed AI in produces two benefits: direct cycle time improvement in that phase, and reduced handoff latency to the next phase. The compound effect builds faster than most teams expect, because the gains aren’t linear. Faster code review reduces the time tests wait to run. Faster test runs reduce the time before deployment validation. Deployment validation runs automatically, removing a gate entirely.
The parallel modernization track feeds this process too. As legacy services get decomposed and documented, they become available for AI tooling that legacy code made impossible. Modernization and AI embedding aren’t competing priorities. They’re the same priority with two execution paths.
The Organizational Design Question CTOs Are Avoiding
The hardest part of the AI-augmented SDLC isn’t technical. It’s organizational.
When phases collapse, what happens to phase-based team ownership?
Most engineering organizations are structured around phases. There’s a QA team. There’s a DevOps team. There’s an architecture review board. These structures made sense when phases were discrete and each required specialized human judgment at a specific point in the sequence.
When AI compresses those phases and the handoffs between them shrink, the phase-based team structure starts to create friction rather than reduce it. The QA team is still reviewing tests that AI generated three days ago. The architecture board is still scheduling reviews for decisions that AI tools flagged during development. The DevOps team is still managing deployment gates that automated pipeline validation is perfectly capable of closing.
Reorganizing around this is politically difficult. Engineers whose roles were defined by phase ownership will push back. Senior engineers who built their authority on being the human gateway between phases will feel that authority threatened. A CTO who wants to capture the real gains of an AI-native SDLC has to navigate that organizational reality, not just the technical one.
Take a position on this: the teams that restructure their organizations around AI-native delivery will outperform the teams that add AI tools to phase-based structures. The performance gap between those two cohorts will widen every year.
Governance, accountability, and human-in-the-loop in a continuous flow model
Continuous flow doesn’t mean no checkpoints. It means checkpoints happen faster and are based on automated signals rather than scheduled reviews. The governance question isn’t “where do humans stay in the loop?” It’s “what signals should trigger human review, and how quickly can humans act on them?”
PwC’s Responsible AI in the SDLC framework (2026) frames this well: governance in an agentic SDLC requires “human review checkpoints, automated testing in CI/CD pipelines, and documented decision-making processes.” The checkpoints exist. They’re just triggered by system signals rather than calendar events. That’s a meaningful governance upgrade for most teams, not a governance risk.
The accountability structure changes, too. When AI is generating code and writing tests, the engineer who defined the spec and the architectural guardrails is more accountable for the quality of what ships than the engineer who typed the most lines. That accountability shift needs to be explicit in how teams are evaluated and how work is recognized.
Nexa Devs builds software delivery teams around AI-native workflows, not the other way around. If you’re evaluating whether your current delivery model can capture the gains of an AI-augmented SDLC, talk to our team about your specific stack and delivery structure.
What is AI-augmented SDLC?
The AI-augmented SDLC embeds AI tooling into every phase of software delivery: requirements, development, testing, review, and deployment. Unlike adding a code completion tool to an existing workflow, the AI-augmented SDLC redesigns how phases relate to each other so that AI handles the tasks that create handoff latency between them.
What is the AI process in SDLC?
In an AI-augmented SDLC, AI operates at the task level within each phase. During requirements, AI helps translate business language into technical specs. During development, AI agents generate, review, and test code. During deployment, AI validates quality signals and manages pipeline gates. The human role shifts to defining guardrails, making architectural decisions, and reviewing AI output on complex or novel problems.
What is agentic software development?
Agentic software development uses autonomous AI agents that can plan, write, test, and modify code with minimal human intervention on well-defined tasks. Unlike copilot tools that assist while a human drives, agentic tools take a high-level instruction and execute it across multiple steps. They’re most effective when the scope is bounded, and the success criteria are clear.
Is AI writing 90% of code?
Not yet at most organizations. Around 41% of all code written is currently AI-generated. The 90% figure comes from Dario Amodei’s projection, which hasn’t materialized on that timeline. What matters for CTOs is whether the delivery model is structured to make AI output reviewable, testable, and architecturally sound.
Your developers are busy. Your IT budget keeps growing. Yet your roadmap keeps slipping, your competitors keep shipping faster, and your board is asking why you haven’t deployed AI yet. You haven’t been mismanaging the business. You’ve been paying a tax you didn’t know had a name.
Technical debt cost is the most expensive line item not on your P&L. It shows up as engineering hours that disappear into maintenance. As features that take 12 weeks instead of two. As AI pilots die in staging because the underlying systems can’t support them. And it compounds, quietly, every quarter, while you’re focused on everything else.
This isn’t an IT problem. It’s your problem. And it’s solvable.
Technical Debt Isn’t an IT Problem. It’s a Business Problem.
Technical debt is a CEO-owned strategic liability, not a developer housekeeping task. You’re carrying it on your balance sheet right now; you just don’t have a line for it.
The Financial Analogy That Finally Makes It Real
The term “technical debt” was coined by software developer Ward Cunningham in 1992. His analogy was precise: writing fast, imperfect code to ship quickly is like taking out a loan. You get the speed now. But you pay interest later, in every feature that takes longer to build because the foundation is fragile, in every engineer who spends Fridays patching rather than creating, in every system integration that fails because no one documented how the pieces connect.
The problem with debt analogies is that most CEOs hear “debt” and think it’s recoverable. Standard debt sits on your balance sheet. You know what you owe, you know the interest rate, you can plan payoff. Technical debt doesn’t work that way. It’s invisible. It doesn’t appear on any report you review. And its interest compounds faster than most leaders realize, because the people best positioned to quantify it, your engineering team, are often the ones most reluctant to surface it to leadership.
When “We’ll Fix It Later” Becomes “We Can’t Build Anything New”
There’s a progression every CEO with legacy technology eventually hits. Phase one: the system works, but it’s slower to change than it used to be. Phase two: new features take three times as long as they should because every change risks breaking something else. Phase three: engineers stop proposing new ideas because they know the system can’t support them. Phase four: a competitor ships an AI feature your customers want, and your team tells you it would take eighteen months to build the same thing.
An unnamed CEO client of software modernization firm Corgibytes described the inflection point precisely: “Features used to take two weeks to push three years ago. Now they’re taking 12 weeks. My developers are super unproductive.”
That CEO wasn’t mismanaging their engineering team. They were running a system in which every change carried the full weight of every shortcut that came before it.
What Technical Debt Is Actually Costing Your Business Right Now
The technical debt cost for a mid-market company is not theoretical. It’s quantifiable, and the numbers are larger than most CEOs expect when they first see them.
The $5.4–$10 Million Annual Drain Most Mid-Market CEOs Don’t Know They’re Carrying
According to zazz.io’s cost modeling for mid-market enterprises, the realistic annual cost of unmanaged technical debt sits between $5.4 million and $10 million per year. That range accounts for engineering capacity consumed by maintenance, delivery delays, security remediation, and talent attrition. It does not include the cost of missed market opportunities or deferred AI investments, those multiply the number further.
Zoom out to the macro level, and the scale becomes staggering. According to Accenture, technical debt consequences cost US businesses $2.41 trillion every year, a figure so large it’s hard to map to your own P&L, until you realize what’s sitting inside it: millions of mid-market companies paying the same compound interest you are.
Gartner estimates that technical debt now represents 20 to 40 percent of the total value of technology estates across enterprise organizations. That’s not a rounding error on your balance sheet. It’s a structural liability.
The Four Budget Lines Where Technical Debt Is Already Showing Up
Most CEOs can feel the cost of technical debt without being able to point to it. Here’s where it lives:
Engineering salaries are spent on maintenance, not creation. According to The New Stack (cited by vFunction), up to 87% of an application’s budget goes to maintaining accumulated technical debt, leaving only 13% for new capability. Your engineers are not unproductive. They’re underwater.
Delivery timelines that cost you deals. When a competitor can ship a product update in two weeks and yours takes twelve, that gap is visible to your customers before you are. Delivery velocity is a revenue variable, not a technical one.
Security exposure from systems that can’t be patched. The IBM Cost of a Data Breach Report 2024 puts the average breach cost at $4.88 million. Organizations running outdated, under-maintained systems report materially higher breach costs. Your legacy codebase isn’t just a productivity drag, it’s an unbooked liability.
Talent you can’t hire or retain. Senior engineers choose their next role partly based on the stack they’ll work in. A legacy codebase populated with undocumented workarounds is a recruiting liability. It’s also a retention liability for the engineers already on your team.
The Four Places Technical Debt Bleeds Money
Technical debt cost isn’t concentrated in one line item. It bleeds across four distinct operational areas, each of which maps to a business outcome you’re already tracking.
Engineering Capacity: 25–40% Spent Maintaining the Past, Not Building the Future
Engineering teams in high-debt environments spend 25 to 40% of their total capacity managing the consequences of existing debt rather than building new capability, according to zazz.io’s cost analysis. Think about what that means in dollar terms. If your engineering team costs $3 million per year in fully loaded labor, you’re burning $750K to $1.2M annually on work that produces zero new business value. Every sprint. Every quarter.
This isn’t a performance management problem. You won’t fix it by hiring more engineers or changing project managers. You fix it by reducing the base cost every engineer carries before they write a single line of new code.
Delivery Velocity: Why Your Roadmap Always Runs Behind
A technical debt-laden codebase doesn’t just slow individual features. It slows everything, simultaneously, in ways that are hard to attribute directly to debt. An engineer estimates it will take three days for a change. It takes two weeks because the systems they’re touching have dependencies no one documented three years ago. Multiply that across every feature on your roadmap and you have a systematic execution gap that no amount of project management will close.
As Cesar DOnofrio, CEO and co-founder of Making Sense, put it: “We see the ROI floor drop out when organizations spend 80% of their budget on bespoke middleware just to get fragmented systems to talk to each other. At that point, you aren’t investing in intelligence; you are paying a legacy tax to keep the lights on.”
That’s not an abstract observation. It describes the exact condition most mid-market technology stacks are operating in today.
Security Exposure: Unpatched Legacy Is an Unbooked Liability
Legacy systems accumulate security debt alongside technical debt. Unpatched vulnerabilities. End-of-life dependencies. APIs that haven’t been updated since the software was first written. None of this shows up as a liability on your books until a breach makes it real.
The IBM 2024 data is clear: the average data breach costs $4.88 million. For organizations running high proportions of outdated systems, that number climbs. Your cybersecurity insurance may cover some of it. It won’t cover the reputational cost, the regulatory exposure, or the customer trust you lose.
Talent Attrition: The Hidden Multiplier Nobody Models
A senior engineer who leaves because the codebase is unmaintainable costs you their salary, plus 50–200% of that salary in recruiting and onboarding time for their replacement. That replacement then spends six months trying to understand a system with no documentation, during which their productivity is a fraction of what you’re paying for.
According to an OutSystems survey cited by Forbes, 86% of technology executives have been impacted by technical debt within the previous 12 months. Most of them report talent attrition as one of the primary downstream effects. The engineers who leave first are almost always the best ones, the ones with options.
Technical Debt Is Now an AI Readiness Problem
This is the angle no competitor covers, and it’s the one that matters most in 2026. Technical debt doesn’t just cost you engineering capacity. It blocks your AI strategy entirely.
Why Legacy Codebases Can’t Support the AI Investments Your Board Is Asking About
AI systems don’t work in isolation. Every meaningful AI capability, whether that’s a workflow automation, an intelligent recommendation engine, or a natural language interface for your internal tools, requires access to your systems of record. It needs clean, structured data. Callable APIs. Loosely coupled architecture that can absorb new integrations without cascading failures.
Your legacy codebase probably has none of that. It has hardcoded integrations that break when you touch them. Databases that store the same field in five different formats across three different tables. Middleware written in 2014 that nobody on your current team fully understands.
The real constraint for AI is not intelligence; it’s integration. AI cannot generate measurable ROI if it operates outside the core systems of record. That’s the architectural reality most AI strategy conversations skip.
According to a McKinsey-cited figure reported by Devox, 80% of organizations need to modernize their legacy environments to achieve the AI-driven efficiency gains their boards now expect. Your AI pilot didn’t fail because the technology isn’t ready. It failed because your infrastructure isn’t ready for the technology.
Every Quarter of Delay Widens the Gap Between You and Your AI-Enabled Competitors
Here’s the dynamic that makes the technical debt cost problem genuinely urgent in 2026, not just expensive: your competitors aren’t waiting.
A competitor that has already modernized their core systems is running AI features today that your team can’t replicate for eighteen months, not because of budget, and not because of engineering talent, but because their foundation can support it and yours can’t. Every month they operate AI-enabled and you don’t, they’re compressing delivery cycles, automating decisions, and creating customer experiences you can’t match.
The gap compounds. And it compounds faster than the underlying debt does, because AI capability is not a linear improvement, it’s an exponential one. Getting there six months later than a competitor doesn’t mean arriving six months behind. It means arriving with two years’ worth of compounded disadvantage to overcome.
Why Waiting Costs More Than Fixing
Every CEO instinct says “wait until we have budget clarity” or “tackle this after the current roadmap clears.” Those instincts are wrong here, and the math explains why.
The Compounding Nature of Technical Interest
Standard financial debt charges you a fixed interest rate on a fixed principal. Technical debt is different, both the principal and the interest rate grow as the debt ages. A system with six months of accumulated shortcuts is painful to work in. A system with six years of accumulated shortcuts is an engineering emergency that requires specialist intervention just to understand what’s there before you can fix anything.
The interest compounds because the people who understand the system leave. Documentation doesn’t get written. New features get built on top of broken foundations, adding their own shortcuts to the pile. Each engineer who joins the team inherits everything that came before them, and each one makes rational local decisions, “I’ll patch this rather than rewrite it, there isn’t time”, that add to the global debt load.
Ray Forte, an executive at Analog Devices, described finding that their infrastructure cost was “in the low 80s” as a percentage of budget. They knew it. They’d been living with it. The question was whether to act now or wait for a cleaner moment that never arrived.
What the Math Looks Like One Year from Now vs. Today
Here’s the capital allocation reality: the cost of remediating technical debt increases the longer you wait, because the debt itself grows and because the market context changes around it.
Delay one year at $7 million in annual technical debt cost, and you’ve spent $7 million more than you needed to. But that’s the conservative case. The realistic case includes the AI competitive gap that opened during that year, the security incident you didn’t have budget to prevent, and the two senior engineers who left because they didn’t want to spend their careers debugging a system built in 2011.
According to Devox’s 2026 research, organizations that complete modernization with AI-augmented methodologies report productivity gains of 20–30% and cost reductions up to 15%. Those gains begin accruing the day the work is done. Every quarter of delay is a quarter those gains don’t compound for you, while your competitors capture them.
What Modernization Actually Looks Like on the Other Side
The fear that stops most CEOs from acting on technical debt isn’t the cost of fixing it, it’s the fear of what fixing it might break. The answer to that fear is specifics, not reassurance.
What Organizations Report After Completing Modernization
The pattern across organizations that complete modernization is consistent. Engineering teams that previously spent 25–40% of their capacity on maintenance work find that number drops below 10%. Feature delivery cycles compress; changes that took twelve weeks take three. Security surface area shrinks because the codebase is documented, current, and patched.
The less obvious outcome is organizational. Engineers who were burning out on legacy maintenance become productive again. Recruitment conversations change when you can tell candidates they’re joining a modern, AI-native codebase. And the CEO walks into board meetings with a technology story that’s about capability, not containment.
Devox’s 2026 Legacy Modernization Report documents the trend across organizations that have completed modernization: productivity gains of 20–30% and cost reductions up to 15% through AI-augmented delivery models. These aren’t ceiling numbers, they’re what organizations report at the start of the compounding curve.
Why AI-Augmented Modernization Changes the ROI Math
Traditional modernization projects have a deserved reputation for running long and expensive. A three-year migration that creates a new set of dependencies isn’t a solution, it’s a different version of the same problem. That reputation is why most CEOs, when they hear “modernization,” mentally price it at 18 to 36 months of disruption and uncertainty.
AI-augmented modernization changes the economics. When AI is applied across the entire SDLC, requirements analysis, architecture design, implementation, testing, documentation, the process is faster, more thoroughly documented, and less likely to create new technical debt as it clears the old. Organizations don’t emerge from the project with new black boxes they can’t maintain. They emerge with systems they own, architectures they understand, and documentation their own engineers can work from.
At Nexa Devs, AI across the full SDLC isn’t a feature, it’s the delivery methodology. Systems we build or modernize come with complete documentation packages: UML architecture diagrams, API references, test coverage reports, and architecture decision records. That documentation transfers to you unconditionally at project close. You own it. Full stop. No new vendor dependency to replace the old one.
That’s the exit from the hidden tax, not a migration project that runs forever, but a modernization engagement that ends with you in control.
Five Questions Every CEO Should Be Able to Answer About Their Technical Debt
If you can answer these five questions confidently, your technical debt is being actively managed. If you can’t, you’ve likely been paying the hidden tax longer than you realize.
1. What percentage of your engineering capacity goes to maintenance vs. new capability? If you don’t know, your engineers do, and they’re probably uncomfortable with the answer. The benchmark for a healthy codebase is under 20% on maintenance. Most mid-market legacy systems run 25–40%. Some run higher.
2. How long does it take to ship a feature from approved to deployed? If the answer has gotten longer over the past three years without a corresponding increase in feature complexity, that’s technical debt compounding. It’s not a team performance problem.
3. When did your core systems last receive a full security audit? Not a scan, an audit. If the answer is “more than 18 months ago” or “I’m not sure,” you have unquantified security liability in your technology stack.
4. If your two most technical people left tomorrow, what would break? Key-person risk in a technology context is technical debt risk. If critical system knowledge lives in someone’s head rather than in documentation, that’s as real as any code-level debt, and typically more dangerous.
5. Can your current codebase support the AI integration your board is asking about? If your CTO or VP of Engineering can’t give you a confident “yes” to this question, the answer is almost certainly no. And the gap between where you are and where you need to be is the most urgent version of technical debt your business is carrying.
If you can’t answer three or more of these confidently, you’re not alone, and this is exactly what a structured technical debt assessment is designed to surface.
Technical debt cost is real, it’s large, and it’s compounding right now. You don’t need to boil the ocean to fix it, but you do need to know what you’re carrying before you can make a capital allocation decision that makes sense.
The first step is understanding the scope. Nexa Devs runs structured architecture assessments that quantify your technical debt in financial terms, map it against your AI readiness requirements, and produce a modernization roadmap your leadership team can evaluate against your actual business priorities, not a generic framework.
Ready to see what your technical debt is actually costing you?
Book a no-commitment architecture assessment with the Nexa Devs team. We’ll give you numbers, not generalities.
FAQ
What are the 4 types of technical debt?
Technical debt falls into four categories: deliberate (shortcuts taken knowingly to ship faster), accidental (poor design decisions made without recognizing the long-term cost), outdated (code that aged as technology and business needs changed), and environmental (dependencies on third-party systems that have degraded). Most mid-market companies carry all four simultaneously.
What does technical debt actually cost a mid-market business?
According to zazz.io’s cost modeling, the realistic annual cost for a mid-market company with unmanaged technical debt runs between $5.4 million and $10 million per year, covering lost engineering capacity, delivery delays, security remediation, and talent attrition. This excludes opportunity costs from blocked AI initiatives.
How does technical debt block AI adoption?
AI systems require clean data, callable APIs, and loosely coupled architecture. Most legacy codebases lack all three. AI pilots succeed in sandboxes but fail to connect to the actual systems of record where business data lives. Modernizing the underlying codebase is the prerequisite for AI, not optional prep work.
How do you fix technical debt without disrupting live operations?
Incremental modernization, not a big-bang rewrite, is the right approach for mid-market companies. Each phase targets a specific component, runs in parallel with live operations, and produces both cleaner architecture and new capability. AI-augmented delivery accelerates each phase while generating documentation that makes future changes safer.
What’s the difference between technical debt and a legacy system?
A legacy system is old software. Technical debt is accumulated shortcuts, missing documentation, and deferred maintenance, it can exist in a five-year-old system as readily as a twenty-year-old one. Most mid-market companies have both: aging systems with compounding debt. That combination is what makes modernization urgent.
You have run the pilots. You have approved the budget. You have sat through the demos. And you are still waiting for AI to show up in your P&L. The problem is not your AI strategy. The problem is what AI has to run on.
Legacy systems AI integration fails at the foundation level — not because AI technology does not work, but because the systems underneath it were never designed to support it. Every failed pilot, every abandoned proof of concept, every “we need more time” update from the project team traces back to the same cause: a stack that cannot give AI what AI needs.
According to Agentic AI Solutions (2026), 78% of organizations say AI readiness is a top priority, yet only 23% have completed a formal AI readiness assessment. That gap — between aspiration and infrastructure — is where your AI investment goes to die.
This article explains why it keeps happening and what the actual path forward looks like.
Your AI Pilots Aren’t Failing — Your Stack Is
Your AI pilots are not failing because of the AI. They are failing because the system the AI has to read, write to, and integrate with was built before AI existed as a production concept — and it shows.
This distinction matters because it changes the solution. If the pilots are failing, you build better pilots. If the stack is failing, you fix the stack. Most mid-market organizations spend two or three pilot cycles learning this the hard way, then arrive at a modernization conversation eighteen months late and significantly over budget.
The pattern is consistent. A team identifies a high-value AI use case — automated document processing, intelligent workflow routing, predictive maintenance alerts. They scope a proof of concept, run it in isolation, and it works. Then they try to connect it to the actual operating system, and everything stops. The data is in the wrong format. The integration point does not exist. The authentication layer blocks the API call. The database schema has not been documented since the original developer left. The “quick fix” to get around it takes three months.
“When legacy systems limit access to reliable data, slow down integration across workflows, or make change deployment complex and time-consuming, AI initiatives stop being strategic levers and become isolated experiments,” according to Cesar DOnofrio, CEO and co-founder of Making Sense. “Organizations may be able to run pilots, but they cannot operationalize or scale them.”
That is the wall. And the wall is structural.
The Legacy Tax: What That System Is Actually Costing You Right Now
Before you can solve the AI readiness problem, you need to see the full cost of what you are already paying. The legacy tax is not a line item — it is the cumulative drag across maintenance spend, lost velocity, and foreclosed opportunity.
The maintenance budget that crowds out innovation spend
Most mid-market organizations spend 60–80% of their technology budget keeping existing systems running. That figure is not a generalization — it is the operating reality for companies running systems built five, ten, or fifteen years ago that have accumulated patches, workarounds, and undocumented dependencies at every layer.
According to McKinsey’s analysis of 500 engineering teams (2025), teams carrying high technical debt took 40% longer to ship features compared to low-debt teams. That is not a technical statistic. That is a competitive one — it means every capability your business needs takes 40% longer to reach your customers than it should.
The maintenance budget is also a ceiling. When 70–80 cents of every technology dollar goes to keeping existing systems alive, you have almost nothing left for the capabilities that would change your competitive position. You approve the AI initiative and then watch it consume the same budget that was supposed to fund growth.
“We see the ROI floor drop out when organizations spend 80% of their budget on bespoke middleware just to get fragmented systems to talk to each other,” said Cesar DOnofrio of Making Sense. “At that point, you aren’t investing in intelligence. You are paying a legacy tax to keep the lights on.”
The compound cost: technical debt + lost AI opportunity
According to Making Sense (2026), citing ITpro research, enterprises lose approximately $370 million annually due to outdated technology and technical debt. That number is striking in isolation, but it understates the real cost for mid-market organizations because it does not include the opportunity cost of every AI initiative that stalls, scales back, or gets canceled entirely.
Technical debt and AI opportunity cost compound each other. The more debt you carry, the harder AI integration becomes. The harder AI integration becomes, the longer competitors who have already modernized extend their lead. Every quarter you delay is not a neutral pause — it is compounding disadvantage.
Why Every AI Pilot Hits the Same Wall
AI pilots consistently fail to scale because they hit two specific infrastructure barriers: data that exists but cannot be accessed, and integration costs that consume the project budget before the AI component can function.
Data you own but cannot use
Legacy systems were built to store and process data inside a single system, not to share it. The data architecture that made sense in 2010 — when your systems did not need to communicate with anything outside themselves — is the same architecture that blocks every AI model in 2026.
AI models need clean, accessible, consistently structured data. What legacy systems typically provide is the opposite: data locked in proprietary formats, split across siloed databases that do not talk to each other, missing the metadata that would make it useful, and governed by access layers that predate modern API standards.
According to IT Brief (2026), 44% of organizations invest in custom software primarily to improve integration, while 40% name integration as their biggest challenge. Those two numbers describe the same problem from opposite directions: everyone knows the data needs to connect, and almost no one has solved it yet.
As Jesper van den Bogaard, CEO of Factor Blue, describes it: “Data silos are not simply a technical problem; they are also an organizational one. Organizations aren’t aware of the huge impact data silos can have within their organization, so they do not invest enough time and resources in tackling or preventing this issue.”
The integration layer that consumes your AI budget before launch
The Futurum Group’s global survey found that 35% of organizations identified legacy system integration as the single highest-cited barrier to AI adoption — above cost, above skills gaps, above regulatory concerns.
The mechanism is straightforward. Before an AI model can process a single transaction, your team has to build the integration layer that connects it to your existing data. In a modern stack, this is a standard API call. In a legacy environment, it is often months of custom middleware development, format translation, authentication workarounds, and testing — all of it burning budget that was earmarked for the actual AI initiative.
By the time the integration is functional, the project has consumed most of its runway. The AI component gets scoped down or shelved. The team reports that the “pilot worked” — because the technical proof of concept did work — but it never makes it into production. The next budget cycle, the same conversation starts again.
The Pilot-to-Production Gap: Where Mid-Market AI Actually Dies
The pilot-to-production gap is the specific failure mode that most modernization content ignores. It is not a resourcing problem, and it is not a skills problem. It is a structural consequence of trying to operationalize AI on infrastructure that was not designed for it.
According to S&P Global Market Intelligence, 46% of AI projects are abandoned between proof of concept and broad adoption — a figure that surged from 17% to 42% in a single year. That trajectory does not describe organizations losing interest in AI. It describes organizations repeatedly running into the same infrastructure ceiling and running out of runway before they can clear it.
The pilot works because it runs in isolation. A sandbox environment, a subset of clean data, a controlled integration point. None of those conditions exists in production. When the project moves from the sandbox to the actual operational environment, the gap between “this worked in the demo” and “this works in your systems” becomes the gap between a successful pilot and a canceled project.
According to CBIZ’s Q1 2026 Mid-Market Pulse Report of more than 1,300 business leaders, 84% of mid-market businesses are prioritizing cost optimization and productivity, while 41% report concerns about technology and AI modernization. Those 41% have not failed at AI strategy. They have collided with legacy infrastructure and are trying to figure out what to do next.
The pilot-to-production gap is structural. You cannot sprint, resourcefully, or budget your way past it. You can only fix the foundation it runs on.
Why Layering AI on Top Makes the Problem Worse
After a failed pilot, the intuitive response is to find a different way in. Add a layer on top of the existing system. Buy a point solution that handles the AI component without touching the legacy stack. Use a wrapper API that abstracts the integration problem away.
This approach is understandable. It is also the reason most mid-market organizations end up with two broken systems instead of one.
When you add a layer on top of a legacy foundation, the legacy foundation’s problems do not disappear — they migrate upward. The data quality issues that blocked your first pilot now block the AI layer you added to get around the first pilot. The integration bottlenecks that consumed your original project budget now also apply to the new layer you built on top. You have doubled the surface area of the problem while solving none of its root causes.
There is also a compounding ownership problem. Every layer you add without modernizing the foundation increases the complexity of the total system. More complexity means more dependencies. More dependencies mean more key-person risk, more integration costs, more maintenance overhead, and more barriers to the next capability you want to add.
“Legacy systems have become so complex that companies are increasingly turning to third-party vendors and consultants for help,” said Ashwin Ballal, CIO of Freshworks. “But the problem is that, more often than not, organizations are trading one subpar legacy system for another. Adding vendors and consultants often compounds the problem, bringing in new layers of complexity rather than resolving the old ones.”
The workaround is not a path forward. It is a longer route to the same wall.
AI-Augmented Modernization: The Path Through the Wall, Not Around It
The path through the wall is modernizing the foundation the AI will run on — and using AI itself to do it faster and at lower cost than traditional modernization approaches have required.
AI-augmented modernization does not mean adding AI features to your legacy system. It means using AI across every phase of the software development lifecycle to rebuild the foundation: requirements analysis, architecture design, implementation, testing, and documentation. AI handles the repetitive, time-consuming work at each phase so the engineering team can move faster and produce cleaner results than traditional development timelines allow.
Using AI across the entire SDLC to modernize the foundation
According to McKinsey, generative AI can deliver 40–50% acceleration in tech modernization timelines and a 40% reduction in costs from technical debt. Those numbers change the calculus on modernization ROI significantly. A project that previously required 24 months can reach delivery in 12–14. A budget that previously required board-level approval becomes a manageable capital allocation.
According to McKinsey, cited by Ciklum (2026), AI can improve developer productivity by up to 45%. When that productivity gain applies specifically to modernization work — migrating legacy data structures, rewriting undocumented business logic, building integration layers, generating test coverage — the compound effect on timeline and cost is substantial.
The specific mechanism: AI-assisted requirements analysis surfaces design risks earlier. AI-accelerated sprint planning reduces planning overhead. AI-generated test coverage means production-ready code reaches deployment with far fewer defect cycles. AI-produced documentation means the knowledge embedded in every engineering decision does not disappear when the engagement ends.
What you get at the end that you didn’t have before
The deliverable is not “a modernized system.” The deliverable is a system that can accept AI integration — with clean data architecture, documented APIs, modern authentication standards, and the integration layer already in place.
When the modernization is complete, the AI pilots you ran before will work. Not because the AI is different, but because the foundation it needs now exists. The data is accessible. The integration points are documented. The architecture supports the connections your AI tools require.
That is the distinction between AI readiness as an aspiration and AI readiness as an infrastructure state. One is a strategy. The other is a system.
Complete Ownership: Why Documentation Transfer Is the Difference Between Modernization and a New Black Box
Every mid-market CEO who has been through a major system implementation knows the feeling: you paid for a new system, but you don’t actually own it. The vendor holds the source code logic. The integration documentation lives in their heads. You need their team to change anything. You traded one black box for another.
This is the risk that most modernization conversations never surface — and it is the risk that turns a good modernization project into a new dependency problem. You fix the legacy stack, but you end up equally locked into the firm that did the fixing.
The antidote is documentation transfer — not as a courtesy at project close, but as a contractual standard deliverable on every engagement. UML architecture diagrams. System design documents. API references. User story libraries. Test coverage reports. Every decision the engineering team made, documented and transferred unconditionally to you at the end of the engagement.
Documentation transfer means you can hand the system to your internal team. It means a new vendor can pick it up without starting from scratch. It means the organizational knowledge is in documents, not in someone’s head. It means when the engagement ends, you own the system — actually own it, in the same way you own any other business asset.
“Want control? Own the repo, app store, and cloud. Day 1. If they say ‘we’ll transfer at the end’, run,” warned one founder advising others on outsourcing risks in a widely cited Reddit thread on software ownership.
When evaluating any modernization partner, documentation transfer is not a negotiating point — it is a minimum standard. If it is not unconditional and complete, you are not modernizing your system. You are refinancing your dependency.
What to Ask Before You Hire a Modernization Partner
Most modernization vendor conversations are structured around what the vendor can build. The more important question is what you will own when they are done. These questions give you a CEO-level filter before you go deeper into technical evaluation.
On AI-augmented delivery: – Does your team use AI across the entire development lifecycle, or only in isolated phases? Ask for specifics — requirements, sprint planning, implementation, testing, and documentation are each distinct. – How does AI-augmented delivery reduce timeline and cost compared to traditional approaches? Ask for examples from comparable mid-market engagements.
On the foundation you will inherit: – When the engagement ends, will my stack be able to accept AI integration without additional middleware? What specifically makes it AI-ready? – What does the data architecture look like after modernization? Can you show me how integration points are documented?
On ownership and documentation: – What documentation do you transfer at project close? Is it unconditional — meaning it transfers regardless of whether we continue the engagement? – If I need to hand this system to a new vendor in three years, what would they receive from you to get up to speed?
On dependency risk: – After delivery, can my internal team or another vendor maintain and evolve this system without your involvement if we choose? – What would a clean handover look like, and have you executed one before?
On accountability: – Do you offer SLA-based ongoing support after delivery, and does that support cover systems you built as well as systems built by other vendors? – Can I speak with a client who is three or more years into their engagement with you?
The answers to these questions tell you whether you are buying a modernized system or buying a new dependency dressed in modern clothing.
Why do mid-market AI pilots fail to scale beyond proof of concept?
Mid-market AI pilots fail to scale because the proof of concept runs in a controlled environment with clean data and isolated integration points. When the project moves to production, it collides with legacy data silos, undocumented APIs, and integration layers that do not exist. According to S&P Global Market Intelligence, 46% of AI projects are abandoned between pilot and production. The cause is structural, not a resourcing or skills gap.
How much does legacy system modernization cost for a mid-market company?
Modernization costs vary by system complexity, age, and scope, but AI-augmented approaches have meaningfully changed the range. According to McKinsey, generative AI delivers 40–50% acceleration in modernization timelines and 40% reduction in costs from technical debt. A project that previously required $500K–$2M and 18–24 months can now be scoped significantly lower. A software architecture assessment is the right first step to get an accurate estimate for your specific system.
How long does legacy system modernization take?
Traditional modernization projects run 12–36 months for mid-market systems. AI-augmented modernization compresses that range substantially. McKinsey’s research indicates 40–50% timeline acceleration through generative AI applied across the SDLC. The actual timeline depends on system complexity, integration requirements, and whether the modernization is phased or comprehensive. A phased approach — starting with the highest-priority integration bottlenecks — can deliver AI-ready
What is the fastest path to AI readiness for mid-market organizations?
The fastest path is not another pilot — it is a targeted modernization of the specific infrastructure blocking your highest-value AI use case. Identify the integration bottleneck that killed your last pilot, scope the minimum foundation work required to remove it, and execute that modernization with AI-augmented tooling to compress the timeline. This is faster than a full platform replacement and produces a working AI-ready system, not a proof of concept.
How can companies modernize legacy systems without replacing everything?
Phased modernization addresses the highest-impact areas first — typically data architecture, integration layers, and API documentation — without requiring a full platform replacement. The goal is to make the existing system AI-compatible, not to rebuild it from scratch. This approach avoids the 24–36 month timeline of a full rewrite and the operational risk of migrating live systems all at once. AI-augmented development compresses each phase further.
What is the ROI of legacy modernization for mid-market firms?
The ROI calculation has two components. The direct cost of inaction: according to Making Sense (2026), citing ITpro research, enterprises lose approximately $370 million annually due to technical debt and outdated technology. The cost of delay compounds because AI-enabled competitors extend their advantage each quarter you wait. The positive ROI case includes the 40% feature velocity gain from eliminating high technical debt, the AI productivity gains (up to 45% per McKinsey), and the competitive capability that becomes available once the foundation is in place.