
Table of Contents
The CEO Wants AI Shipped. Your Stack Can’t Do It.
You’re the CTO. Your CEO walked out of a board meeting with a mandate to ship AI features this quarter. You know your system can’t do it — not because AI is hard, but because your infrastructure was never built for it. That’s the conversation no one is having out loud.
This isn’t an AI problem. It’s an architecture problem that AI just made visible.
The board doesn’t distinguish between “using AI tools” and “running AI agents.” You do. The gap between those two things is the gap between your CEO’s timeline and your technical reality. Understanding that distinction precisely is where this article starts.
What “AI-ready” actually means at the infrastructure level
“AI-ready” is not a mindset or a strategy. It’s a concrete set of architectural requirements. An AI agent needs a surface it can call, data it can read, services it can orchestrate, and a deployment pipeline that can push updates without a six-week freeze.
Your 15-year-old monolith meets none of those requirements. Not partially — none. The next section lays out exactly what an AI agent needs. Read it as a checklist against your current system.
What AI Agents Actually Demand from Your Infrastructure
AI agents have specific infrastructure requirements. They’re not generic AI tools you bolt on — they’re autonomous reasoning loops that call external tools, interpret results, and take sequential actions. Your infrastructure has to support that interaction model, or the agent can’t function.
Here’s what that means in concrete terms.
An API surface with callable tool endpoints
An AI agent operates by calling tools. Each tool is an API endpoint the agent can invoke: “query this database,” “update this record,” “trigger this workflow.” If your system has no API layer, the agent has nothing to call. Integration doesn’t become difficult — it becomes impossible.
Most legacy monoliths weren’t designed to be called externally. They were designed to run internally. That architectural choice, made fifteen years ago for perfectly good reasons, is the first structural blocker for any agent deployment.
Clean, unified data that the model can reason over
A language model reasons over data. It summarizes, classifies, extracts, and decides — but only from data it can see. Siloed databases, inconsistent schemas, duplicate records, and data locked inside application logic are all invisible to the model. Garbage in, hallucinations out.
According to the IBM Global AI Adoption Index, 25% of businesses name data complexity as their top barrier to AI adoption, and 22% say AI projects are too difficult to integrate and scale with their current infrastructure. Those numbers track with what development teams actually encounter: the data is there, but the model can’t reach it.
Modular services with clear domain boundaries
AI agents orchestrate multiple services. They call one service to fetch context, another to write a result, and another to send a notification. That requires modular architecture — services with clean interfaces and clear domain ownership. A monolith where business logic is entangled across shared database tables and direct function calls doesn’t support orchestration. It supports a single application doing everything internally.
A CI/CD pipeline that ships without six-week freezes
AI features iterate fast. Model versions change. Prompts get tuned. New agent tools get added. Without a CI/CD pipeline that can ship continuously, every iteration stalls at the deployment gate. Six-week release cycles aren’t just slow — they make AI development economically irrational. The feedback loops AI requires don’t fit inside them.
Why a 15-Year-Old System Fails Every One of These Requirements
Check the four requirements above against a typical legacy monolith. The result isn’t “partial fit.” It’s systematic failure across all four dimensions. Here’s why.
The data silo problem: your AI model can’t see half your data
Legacy systems accumulate data in isolated stores. The CRM lives in one database. The ERP in another. Operational data sits in a third, maintained by a vendor who controls schema access. None of these stores were designed to expose their data to external consumers — let alone to an AI model reasoning over them in real time.
Data quality compounds the silo problem. Fifteen years of schema drift, inconsistent entry standards, duplicate records from system migrations, and undocumented business rules embedded in application code mean the data you can access isn’t clean enough for a model to reason over reliably. The model doesn’t fail gracefully when data is dirty — it hallucinates.
The API void: no endpoints, no agent surface
If your system predates the API economy, it almost certainly has no API layer. Business logic runs inside the application. Data access happens through direct database queries within that same application. There’s no surface an AI agent can call because the system was never designed to be called.
Adding an API wrapper to a monolith doesn’t solve this. A wrapper exposes the monolith’s chaos — tightly coupled functions, undocumented behavior, brittle data dependencies — through a new interface. The agent can reach it, but the surface it reaches is unreliable.
The tight coupling trap: every change is a crisis
In a tightly coupled system, changing one component risks breaking ten others. Developers know this, so they avoid changes. Features that used to take two weeks now take twelve. Every sprint carries a risk assessment meeting before any meaningful work starts.
That environment is incompatible with AI development, which requires constant iteration. You can’t tune an agent’s tool definitions when every tool definition change triggers a full regression cycle. You can’t ship a new model version when deployment requires six weeks of coordination.
Maintenance-dominated IT: your team is busy keeping the lights on
According to CIO Dive (2025), only 29% of annual IT budgets go toward transformative technologies, while 43% is devoted to maintaining legacy systems. Your team isn’t failing to build AI features because they lack skill. They’re failing because 43 cents of every dollar you give them goes to keeping an aging system alive — not building anything new.
As Cesar DOnofrio, CEO and co-founder of Making Sense, states: “AI initiatives stop being strategic levers and become isolated experiments” when infrastructure spending crowds out the investment that would make those initiatives work.
Why “Bolting AI On Top” Always Fails
When board pressure mounts, the tempting answer is an AI layer without touching the underlying system. A middleware wrapper. An AI-powered front end that talks to the existing back end. A pilot scoped specifically to avoid the structural problems.
This approach produces demos. It doesn’t produce production AI capabilities.
The demo works because you hand-picked the data the model would see, kept the agent’s scope narrow enough to avoid the broken API surface, and accepted a manual deployment process. When the pilot graduates to real workloads, every one of those constraints comes back. The agent starts calling endpoints that return inconsistent responses. It reasons over data that wasn’t cleaned for the pilot. The release cycle prevents updates from shipping fast enough to iterate on model behavior.
According to Gartner (via Modus Create), more than 40% of agentic AI projects are predicted to be canceled by 2027 due to cost and value-proof challenges. The pilot-to-production gap is structural, not motivational. Organizations that fail at production AI aren’t insufficiently committed. Their infrastructure isn’t ready for it.
A wrapper on a broken foundation is still a broken foundation.
See why the pilot-to-production gap is structural, not motivational — and what it looks like in practice: Legacy Systems AI Integration: Why Your Stack Is the Bottleneck
What an AI-Ready Architecture Actually Looks Like
AI-ready architecture isn’t a single technology choice. It’s a set of design decisions that together give an AI agent the surface it needs to operate. Each of the four agent requirements maps directly to a layer of the target architecture.
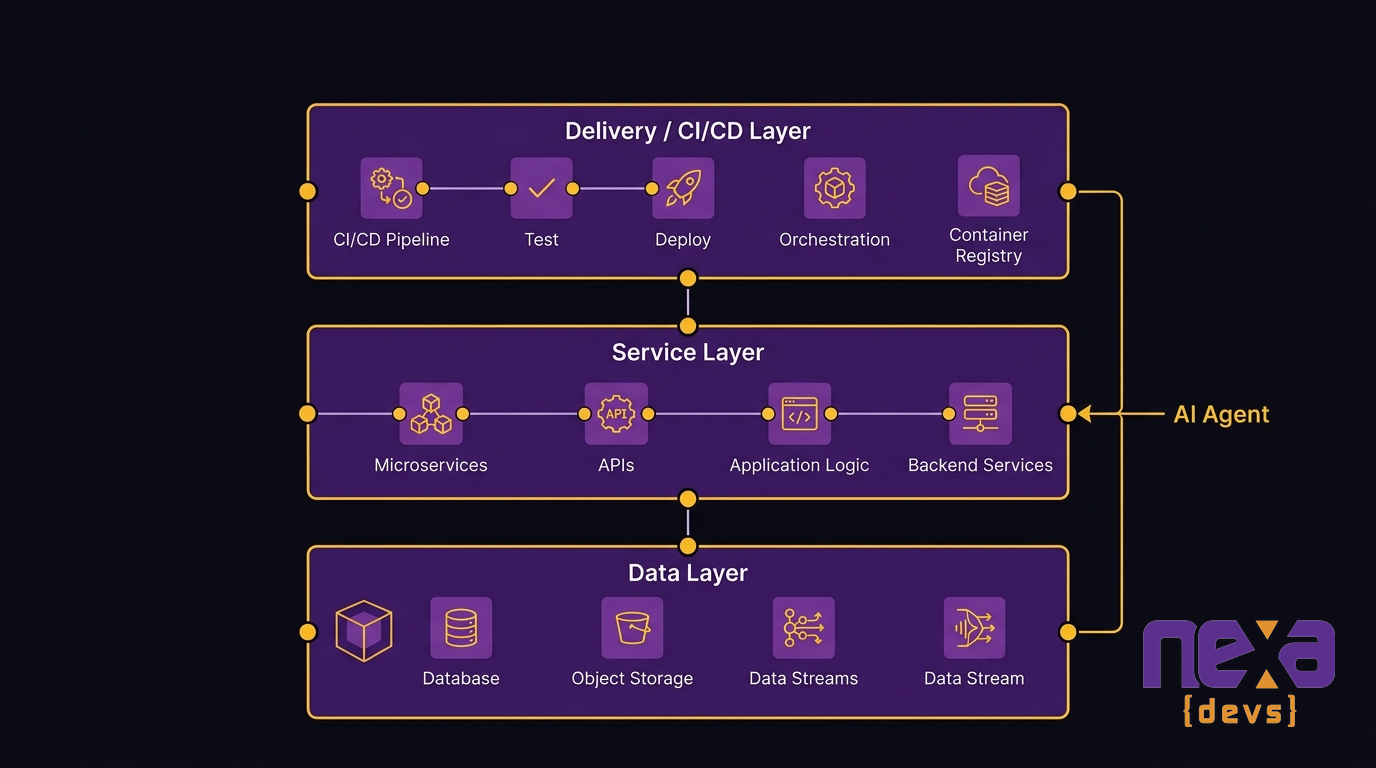
Data layer: unified, observable, queryable by external systems
A unified data layer makes data accessible to systems outside the application — including AI models. That doesn’t mean a single database. It means an architecture where schemas are consistent, access is controlled through documented interfaces, and data exposed to external consumers is validated and clean.
This requires data governance work alongside technical architecture work: defining ownership of each data domain, establishing data quality standards, and retiring the hand-coded integrations that currently move dirty data between isolated stores.
Service layer: API-first design with loosely coupled modules
An API-first service layer means every business capability is exposed through a defined, callable interface. Services have clear domain boundaries — one service owns customer data, another owns order processing, another owns notifications. They communicate through those interfaces, not through shared database tables or internal function calls.
This design makes each service independently deployable and independently testable. It’s also what gives an AI agent a clean set of tools to call. Each API endpoint becomes a potential agent tool. The cleaner the interface, the more reliable the agent behavior.
Delivery layer: CI/CD that supports iterative model deployment
A CI/CD pipeline built for AI deployment ships model updates, prompt changes, and agent tool definitions independently of full application releases. That means feature flags, automated test gates, and deployment environments that mirror production closely enough to catch model behavior regressions before they reach users.
Without this layer, AI iteration stalls at the deployment gate. With it, the feedback loop between model behavior and business outcome compresses from weeks to hours.
How to Get There Without Replacing Everything
A big-bang rewrite is almost never the right answer. It takes longer than projected, costs more than budgeted, and forces a live business to run on a frozen codebase during execution. The organizations that have successfully modernized toward AI-ready architecture didn’t replace everything at once — they replaced strategically.
Identify the AI-blocking chokepoints first — not the entire system
Not every part of your system blocks AI. The parts that block it are specific: the modules with no API surface, the databases where the data an AI agent would need sits in the most chaotic schema, the services where a single change triggers the longest regression cycle.
Start with an architecture assessment that maps your system against the four agent requirements. The output isn’t a list of everything that needs to change. It’s a ranked list of the specific components whose current state prevents AI deployment. Fix those first.
Book a software architecture assessment with Nexa Devs
The strangler fig pattern: incrementally replace without a full shutdown
The strangler fig pattern is the standard incremental modernization approach: build new, clean services alongside the legacy system, route traffic to them progressively, and retire legacy components as they’re replaced. The system stays live throughout. The new architecture grows while the old one shrinks.
For AI readiness, each new service built in this pattern is API-first and agent-ready from day one. You don’t end up with a legacy system patched with modern components. You end up with a modern system built incrementally around the legacy core.
At Nexa Devs, the delivery process is AI-native from the first sprint. Systems built or modernized through our process emerge with clean architecture, complete API documentation, and the test coverage that makes future AI integration straightforward — not as a post-delivery activity, but as a standard artifact of how we build.
How to show AI wins while the foundation is being built
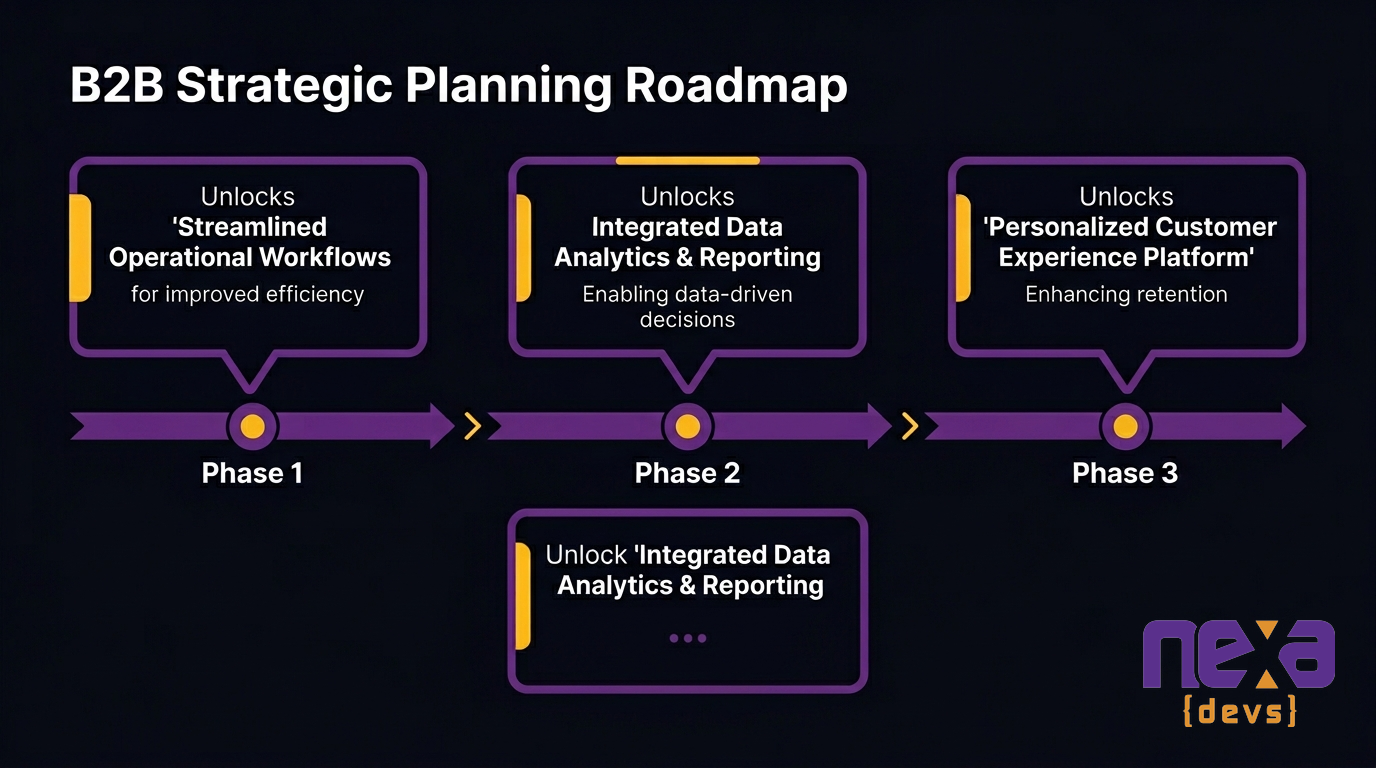
The modernization roadmap doesn’t have to be invisible to the business while it runs. Each phase can be sequenced to unlock a specific AI capability when it completes.
Phase one cleans the customer data domain and exposes it through a new API. That immediately enables an AI agent to answer customer-facing queries from clean data. Phase two extracts the order processing service. That enables an AI agent to take order actions autonomously. Each phase produces both architectural improvement and a new AI capability the business can see.
This is the language that keeps the modernization roadmap funded: every infrastructure investment maps to a specific AI feature that ships when the phase completes.
Talking to Your CEO: Reframing Infrastructure as AI Strategy
The CEO wants AI shipped. You need a budget to modernize the infrastructure that makes AI possible. Those two things sound like a conflict. They’re actually the same conversation — if you frame it correctly.
The cost of not modernizing vs. the cost of a phased modernization
The consequences of technical debt aren’t deferred — they’re compounding. According to AEI (2025), the consequences of technical debt, including cybersecurity incidents, operational failures, and legacy maintenance costs, total $2.41 trillion annually across U.S. businesses. That’s the cost of not fixing it.
A phased modernization has a known cost and a defined timeline. The alternative — continuing to pay 43% of the IT budget to keep legacy systems alive while AI capability accumulates in competitors — has an unknown cost that grows every quarter.
As Skylar Roebuck, CTO of Solvd, has noted: “AI capability is compounding rapidly.” The real risk isn’t moving too fast. It’s the compounding cost of delay.
How to frame infrastructure investment as AI readiness investment
The framing that works with CEOs isn’t “we need to modernize our infrastructure.” That sounds like a sunk-cost engineering project with no visible output. The framing that works is: “each phase of this modernization unlocks a specific AI capability — here’s what ships in phase one, what ships in phase two, and the business outcome attached to each.”
Infrastructure investment and AI strategy are the same investment when you sequence the work correctly. That’s the argument that moves budget.
The organizations competing with you for market share aren’t waiting. If your infrastructure can’t support AI agents today, the question isn’t whether to modernize — it’s how fast you can afford to move.
Build AI Capability on Architecture That Can Hold It
You can’t run AI agents on a system with no API surface, dirty siloed data, and a six-week deployment cycle. That’s not a problem you work around with the right vendor or the right model. It’s a structural constraint — and the only path through it is fixing the structure.
The answer isn’t a big-bang rewrite. It’s a phased modernization that sequences infrastructure improvements to unlock AI capabilities as each phase completes, so the business sees AI wins while the foundation is being built.
Nexa Devs runs architecture assessments that map your system against the four requirements AI agents actually need, then delivers incremental modernization using an AI-native process that produces clean architecture and full documentation as standard artifacts. You end up owning the system — not renting access to a new dependency.
Ready to find out where your infrastructure stands?
Book an Architecture Assessment with Nexa Devs
FAQ
How to integrate AI into legacy systems?
Start with an architecture assessment to identify which components block AI deployment — missing API layer, siloed data, tightly coupled services. Use the strangler fig pattern to build API-first replacements incrementally alongside the existing system. Sequence each phase to unlock a specific AI capability on completion. Bolting an AI layer on top without fixing the underlying architecture produces demos, not production capability.
What are the challenges of legacy modernization?
The main challenges are tight coupling, data silos, no API surface for AI agents to call, and a maintenance burden that consumes budget. According to CIO Dive (2025), 43% of IT budgets go to keeping legacy systems alive — leaving little for modernization. Justifying infrastructure investment to business stakeholders before AI features ship is the key organizational challenge.
What is the legacy model in AI?
In infrastructure terms, a legacy system is a monolithic or end-of-life application that predates the API economy and can’t support modern AI agent workflows — no callable interface, unclean or siloed data, and tight internal coupling that makes change risky. This structural mismatch is the most common AI-readiness blocker for mid-market organizations.
What are the problems with legacy systems?
Legacy systems have four structural problems that block AI: no API layer, siloed and dirty data, tight coupling that makes every change a crisis, and a maintenance burden that consumes IT budget. According to CIO Dive (2025), 43% of IT budgets go to legacy maintenance — leaving only 29% for transformative technology investment.
Why are AI agents not working?
AI agents fail in production because the infrastructure wasn’t built for them. Agents need callable API endpoints, clean unified data, loosely coupled services for orchestration, and a fast deployment pipeline. When those four requirements aren’t met, agents work in controlled pilots and fail under real workloads. The failure is the infrastructure, not the agent.