
Table of Contents
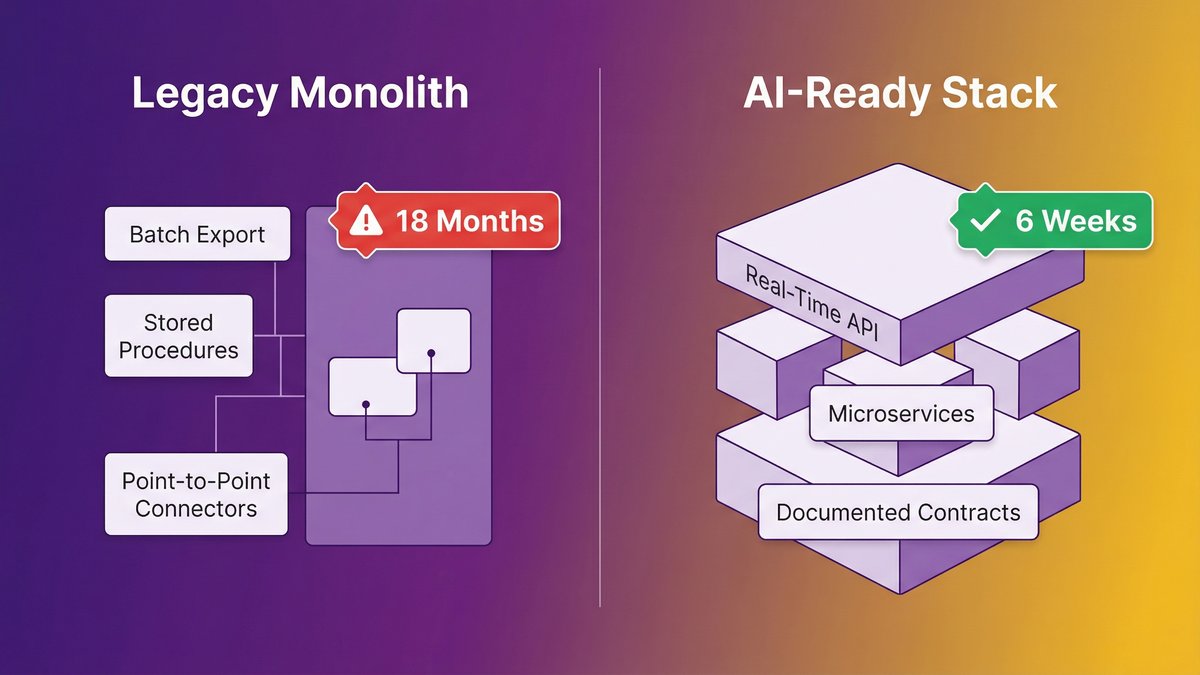
You watched a competitor launch an AI feature in six weeks. Your engineering team quoted you 18 months just to “get the systems ready.” That gap isn’t a strategy problem or a budget problem. It’s a stack problem, and it’s structural.
AI readiness in the enterprise isn’t about picking the right AI vendor. It’s about whether your underlying architecture can support AI at all. Legacy systems built for operational stability, the kind that kept your business running reliably for a decade, were not designed for real-time data access, API-first integration, or the modular component structure that AI agents require. That’s not a configuration gap. It’s an architectural one.
This post explains why, shows you the three specific characteristics that make AI impossible on most legacy stacks, and ends with a checklist that most mid-market legacy shops fail four out of five times.
Quick answer: Why AI readiness enterprise initiatives stall
- AI readiness is an architecture problem, not a tool selection problem; legacy systems built for operational stability can’t support AI agents by design.
- Three stack characteristics block AI: no real-time data access, no API-first design, and no modularity.
- According to Gartner, 40% of enterprise applications will embed AI agents by the end of 2026, up from less than 5% in 2025. The gap is widening fast.
- Traditional rip-and-replace rebuilds typically run past 18 months and add compounding risk; AI-augmented modernization is the alternative.
- Most mid-market legacy stacks fail 4 of the 5 readiness criteria at the bottom of this post.
The 18-Month Wake-Up Call: What Legacy Systems Are Really Telling You
Your legacy stack isn’t just slowing you down. It’s telling you something specific: your architecture was built for an era AI doesn’t operate in.
Why your competitor shipped an AI feature in weeks
They didn’t have a better AI strategy. They had a different foundation. A competitor who ships an AI feature in six weeks is starting from an architecture that already exposes data in real time, already has documented API contracts, and already runs services that are independently callable. Their AI vendor plugs in. Yours hits a wall.
The asymmetry here is stark. A Series B SaaS company on a modern microservices stack can have a working AI co-pilot in a sprint. A mid-market operations platform built on a 12-year-old monolith with batch-export data pipelines can’t do the same thing in 18 months, not because the AI is harder, but because the plumbing doesn’t exist.
According to Gartner, 40% of enterprise applications will embed AI agents by the end of 2026, up from less than 5% in 2025. Your competitor is in that 40%. The question is whether you will be.
The “systems readiness” answer your engineering team keeps giving you
When your CTO says, “We need to get the systems ready first,” that’s not stalling. That’s a precise technical diagnosis. The frustrating part is that it’s accurate.
Legacy systems weren’t built to fail at AI. They were built to succeed at something else: operational stability, batch processing, and predictable throughput. Those design goals are now exactly the wrong design goals for an AI-enabled business. Your engineering team knows this. What they don’t always have is a path through it that doesn’t require shutting down the business to get there.
Read: AI-ready architecture
AI Readiness Is Not a Tool Problem, It’s an Architecture Problem
Stop looking at AI vendors. Look at your stack. The constraint is architectural, and no vendor selection process fixes an architectural constraint.
What “operational stability” architecture looks like under the hood
Operational-stability systems share a recognizable anatomy. Data lives in a relational database with tables designed for transactional accuracy, not query flexibility. Business logic is embedded deep in stored procedures or monolithic application code that hasn’t been touched since the original developer left. Integrations between systems run on point-to-point connectors, often undocumented, that break if either side changes. Deployments require planned downtime windows because nothing is truly independent.
This architecture is defensible. It produced reliability. It kept your business running.
It also cannot support AI agents. Not without modification that goes all the way down to the data layer.
Why are the same systems that kept your business running blocking AI
The design choices that created reliability in 2012 are the same design choices that create AI-incompatibility in 2026. Batch exports instead of real-time data streams. Tightly coupled modules instead of independently callable services. Direct database access instead of API contracts. No architectural separation between “where data lives” and “how systems consume it.”
As Cesar DOnofrio, CEO and co-founder of Making Sense, puts it: “When legacy systems limit access to reliable data, slow down integration across workflows, or make change deployment complex and time-consuming, AI initiatives stop being strategic levers and become isolated experiments.”
That’s the exact failure mode most mid-market AI initiatives hit at month three.
Read: Technical debt and AI readiness
Three Stack Characteristics That Make AI Impossible
Your stack blocks AI in three specific ways. Each one is a hard blocker, not a configuration problem.
No real-time data access: why AI agents need live data, not last night’s batch
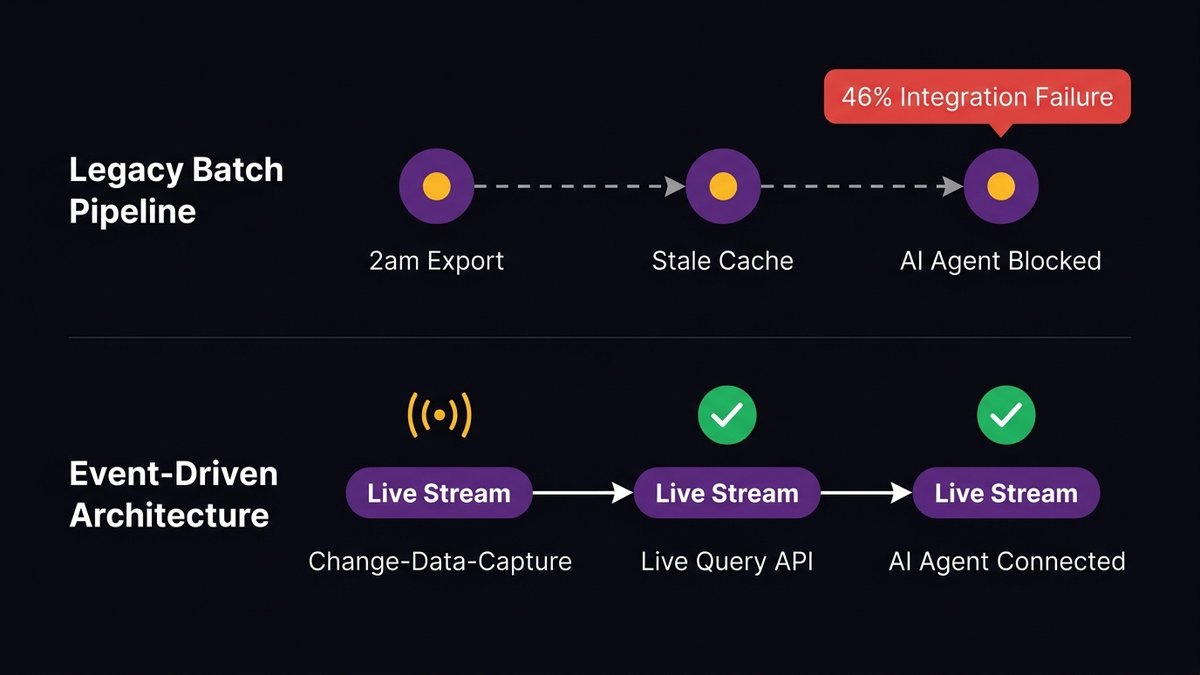
AI agents don’t run on historical exports. They need access to live, current data, what’s happening now, not what happened at 2 am when the batch job ran. Most legacy systems generate data as a side effect of transactions and export it on a schedule. The AI agent asks, “What’s the current inventory level?” and the system’s honest answer is “whatever it was at midnight.”
This is why 46% of respondents in Arcade.dev’s 2026 State of AI Agents report cite integration with existing systems as their primary challenge. The integration challenge is almost always a data-access challenge in disguise. The system can’t give AI what it needs at the moment it needs it.
Real-time data access requires a data layer built for event-driven consumption, streaming pipelines, change-data-capture patterns, or, at a minimum, an API layer that queries live records. Legacy batch-export architectures need significant re-engineering before they’re AI-capable. That’s not a configuration setting.
No API-first design: the integration wall every AI vendor hits
Every serious AI vendor will ask one question early in your evaluation: “What APIs can we call?” If the answer is “we have some endpoints, but they’re not fully documented” or “we’d need to build those,” the evaluation just got significantly more expensive.
API-first design means every system capability is exposed through a documented, versioned, contract-based API before any external consumer is built. Legacy systems were almost never built API-first. They were built to do a job internally. APIs were added later, often inconsistently, often without documentation, often by developers who are no longer there.
When the AI vendor hits that wall, the options are: build a custom integration layer (expensive, slow, brittle), build the APIs that should have been there from the start (the right answer, but adds months), or wrap the AI around a surface-level data export that doesn’t actually give it what it needs (produces a failing pilot at month four). Most organizations take door three. Then wonder why the pilot didn’t scale.
No modularity: why you can’t embed AI into a monolith without breaking it
Embedding AI into a monolithic application requires you to surgically modify code that was never designed to be modified surgically. Business logic is intertwined. Changing one component means testing the entire application. Deploying one fix means deploying everything. The feedback loop between “write the AI feature” and “verify it works in production” stretches from days to months.
Modular architectures, where services are independently deployable, independently testable, and independently callable, allow AI to be embedded into specific workflows without touching unrelated ones. Monoliths don’t allow that. Every AI feature becomes a full-application deployment risk.
This is the part your CTO is describing when they say “we’d have to restructure significant portions of the codebase.” They’re right. That’s not pessimism. It’s an accurate read of what AI actually requires.
Read: “Legacy systems and AI agents.”
Why the Pilot-to-Production Gap Keeps Widening
AI pilots work in controlled conditions. Production doesn’t offer controlled conditions.
What failed AI pilots have in common
According to IDC research, for every 33 AI pilots launched, only 4 reach production, an 88% failure rate. That’s not a technology failure. It’s an infrastructure failure. Pilots succeed by working around the constraints of the production system. They use curated datasets, custom data exports, manually assembled API responses, and a dedicated implementation team that doesn’t represent what production support looks like.
When the pilot is handed to production infrastructure, real data access patterns, real integration dependencies, real deployment processes, it hits every constraint that was bypassed during the pilot. And it fails.
According to McKinsey, 62% of organizations are experimenting with AI agents. Only 23% successfully scale them. The gap between 62% and 23% lives in the production infrastructure.

The hidden cost of “AI-on-top-of-legacy” workarounds
There’s a tempting intermediate move: build the AI on top of the legacy system through a combination of data exports, API wrappers, and integration middleware. Don’t touch the underlying architecture, just build AI around it.
This works. For a while. The cost appears later: integration brittleness that breaks when either side changes, data latency that degrades AI accuracy, a middleware layer that becomes its own technical debt, and a system that still can’t support the next generation of AI capabilities. You’ve bought six to twelve months of AI capability at the cost of compounding the architectural problem underneath.
According to data from IDC, legacy data infrastructure drives $108 billion in annual wasted AI investment. A significant portion of that waste is the AI-on-top-of-legacy pattern: real money spent on AI tooling that can’t perform because the underlying system won’t support it.
The Modernization Trap: Why Traditional Rebuilds Make It Worse
The obvious answer is: modernize the system. But “modernize” done wrong produces outcomes that are worse than the status quo.
The rip-and-replace myth: why 18-month timelines are optimistic
A full system rewrite, rip out the old, build the new, sounds clean. It isn’t. It requires running two systems in parallel: the old one, which can’t go down because the business runs on it, and the new one, which needs to reach feature parity before you can switch over. Feature parity is harder than it sounds because legacy systems accumulate undocumented behavior over a decade. The new system has to replicate that behavior without anyone having written it down.
Eighteen months is when these projects start. Two to three years is where most of them end. And a significant number never complete at all, stalling at 70% migration while new requirements keep arriving for a system that’s half-old, half-new, and fully unmaintainable.
As Ashwin Ballal, CIO at Freshworks, says: “Organizations are trading one subpar legacy system for another. Adding vendors and consultants often compounds the problem, bringing in new layers of complexity rather than resolving the old ones.”
How maintaining legacy while rebuilding creates compounding risk
While the rebuild runs, the legacy system continues aging. Bug fixes on the old system have to be replicated in the new system or ignored. Security vulnerabilities in the old system have to be patched even though you’re “replacing it.” The team is split between maintaining the system that pays the bills and building the system that will replace it, and both suffer.
The compounding dynamic is real: every month the rebuild takes is another month the legacy system accumulates new technical debt, another month the AI ambitions sit on hold, and another month your competitor extends their lead with the AI features they shipped last quarter.
What AI-Augmented Modernization Actually Looks Like
There’s a third option between “stay on legacy” and “rewrite everything.” It uses AI to accelerate the modernization itself.
Using AI to accelerate migration without stopping the business
AI-augmented modernization applies AI tooling across the development lifecycle, requirements analysis, architecture documentation, code migration, test generation, and API design to compress timelines without requiring the business to stop. The approach: modernize incrementally, starting with the components that block AI integration first.
According to Ciklum, citing McKinsey research, AI can improve developer productivity by up to 45%. When that productivity improvement is applied to the modernization process itself, not to building new features on the old system, it changes the math on what’s achievable in a given timeline. A migration that traditional delivery would take 24 months can be approached in 14 to 16 months with AI-augmented delivery.
The key distinction from rip-and-replace: you’re not building a parallel system that replaces the old one all at once. You’re extracting, modernizing, and redeploying components incrementally. The legacy system stays live. Each completed component is one less thing the legacy system has to carry.

Why cleaner architecture emerges faster with AI-augmented delivery
AI-assisted code analysis, automated documentation generation, and AI-accelerated refactoring don’t just speed up the process; they produce a cleaner result. AI tooling applied at every phase of the development lifecycle surfaces design inconsistencies earlier, generates documentation as a continuous output of the process rather than a post-project sprint, and produces test coverage that traditional manual processes frequently skip under time pressure.
The output of an AI-augmented modernization isn’t just a faster migration. It’s a system that emerges with cleaner architecture, documented APIs, and the test coverage needed to safely embed AI agents into it afterward. The modernization doesn’t just “get the systems ready.” It produces a system that’s ready by design.
At Nexa Devs, this is how we approach every modernization engagement. We use AI across the full development lifecycle, not as a tool layered on top of delivery, but as the method through which the delivery happens. The result is a system you own fully: complete documentation transferred at project close, SLA-based support that continues after launch, and no new vendor dependency to replace the old one.
The AI-Ready Stack: What You Actually Need Before You Can Scale AI
Here’s the destination. Three layers, each with a specific requirement.
Data layer: real-time access over batch reporting
An AI-ready data layer exposes current data through event-driven patterns. Change-data-capture pipelines that push updates as they happen. Query APIs that return live records, not cached exports. A data access model that treats the AI agent as a first-class consumer, not an afterthought that reads from the same batch export the finance team uses every morning.
This doesn’t require a complete data warehouse rebuild. It requires designing a real-time access layer over your existing data, one that the AI can call without needing a data engineer to prepare a custom export first.
Integration layer: API-first contracts, not point-to-point connectors
AI-ready integration means every system capability has a documented, versioned API. Not “we have some endpoints”, documented, versioned, tested, with known response schemas. When the AI agent needs to call your inventory system, it calls an endpoint that returns a consistent response structure. When the AI agent needs to update a record, it calls a write endpoint with defined authorization and validation.
Point-to-point connectors between legacy systems, the duct tape and rubber cement of most mid-market stacks, don’t scale when AI becomes the new consumer. They break. They return inconsistent data. They don’t have the error-handling AI workflows that are required. The integration layer has to be rebuilt API-first before AI can rely on it.
Application layer: modular services AI agents can call
The application layer needs to be modular enough that AI agents can invoke specific capabilities without triggering side effects in unrelated parts of the system. An AI agent that needs to check order status shouldn’t have to navigate a monolith that bundles order management, inventory, billing, and customer records into the same codebase.
Modularity doesn’t require a full microservices rebuild. The strangler fig pattern, gradually extracting services from the monolith, one domain at a time, gives you modular, callable services without requiring the entire monolith to be decomposed before AI can touch anything. Each extracted service is immediately AI-accessible. The monolith shrinks while AI capability grows.
The 5-Point AI Readiness Checklist: Where Does Your Stack Stand?
Run through these five criteria honestly. A typical mid-market legacy stack fails four of them.
1. Real-time data access
Can an external system, including an AI agent, query your live operational data without waiting for a scheduled batch export? If your data access model is export-based, you fail this one.
2. Documented, versioned APIs
Do you have a documented API layer with versioned endpoints, known response schemas, and active maintenance? If your integration approach relies on direct database access, undocumented connectors, or one-off scripts, you fail this one.
3. Independent deployability
Can you deploy a change to one part of your system without a full application deployment? If your deployment process requires taking everything down or running a full regression test suite for a single module change, you fail this one.
4. Observable production behavior
Do you have logging, monitoring, and tracing granular enough to debug an AI agent interaction in production? If your observability stack can’t tell you what happened inside a specific transaction in real time, you fail this one.
5. AI-accessible documentation
Is your system documented well enough that an AI agent or a new developer could understand how to interact with it without asking the one person who built it? If the answer is “it’s in Gary’s head,” you fail this one.
Most mid-market organizations reading this fail four of five. That’s not an indictment, it’s a diagnosis. The path through it is architectural modernization, done incrementally, in a sequence designed to unlock AI capability at each phase rather than waiting until the entire system is rebuilt.
If you want to know exactly where your stack sits against these five criteria, start with an architecture assessment. It’s the fastest way to turn a frustrating 18-month estimate into a prioritized, phased roadmap that produces AI capability in months, not years.
Ready to find out where your stack actually stands?
An architecture assessment from Nexa Devs maps your existing system against AI-agent requirements, the exact five criteria in the checklist above, and produces a sequenced modernization roadmap that unlocks AI capability at each phase. No 18-month wait. No business disruption. No new black-box dependency.
Book an architecture assessment or contact us to talk through where your stack sits today.
FAQ
What is the AI readiness process?
AI readiness for enterprises is a structured assessment of whether your current architecture can support AI deployment at scale. It covers data access patterns, integration layer design, application modularity, and observability. The process starts with an architecture audit mapped against AI-agent requirements, then produces a prioritized modernization roadmap.
Why are AI implementations failing?
Most enterprise AI implementations fail because they’re deployed on infrastructure that can’t support them in production. Common causes: legacy batch data pipelines, undocumented APIs, and monolithic architectures. According to IDC research, only 4 of every 33 AI pilots reach production, an 88% failure rate driven almost entirely by infrastructure constraints.
Is 95% of AI failing?
IDC data shows approximately 88% of AI pilots don’t reach production. McKinsey reports 62% of organizations experiment with AI agents, but only 23% scale them successfully. The consistent pattern: pilots succeed in controlled conditions, then fail when hitting real production infrastructure with legacy constraints.
What are the 4 pillars of AI readiness?
The four pillars are: (1) data infrastructure, real-time, accessible, high-quality data; (2) integration architecture, API-first, documented, independently deployable; (3) organizational alignment, executive buy-in, and cross-functional coordination; (4) security and governance, privacy, compliance, and responsible AI controls. For mid-market organizations, pillars one and two are the most common blockers.
Why do AI pilots fail to scale in enterprises?
AI pilots fail to scale because conditions that make them succeed, curated test data, custom integrations, and dedicated teams, don’t exist in production. Real production requires live data from legacy systems, undocumented API integration, and standard deployment processes. Legacy architecture failures become visible exactly when the pilot moves to production.
What percent of AI implementations fail?
IDC research shows 88% of AI pilots don’t reach production scale. S&P Global data shows 46% of AI projects are scrapped between proof-of-concept and broad adoption, up from 17% previously. Across multiple sources, the failure or abandonment rate ranges from 46–88%, depending on how failure is defined and when it’s measured.