
Table of Contents
AI Readiness Assessment: Why 80% of AI Projects Fail Before They Start (And How to Know If You’re Next)
You approved the AI initiative six months ago. The vendor presented a convincing pilot. The team was excited. Then nothing made it to production.
Or maybe it got to production and it doesn’t work the way anyone expected. Or maybe it’s still “in progress,” consuming budget and delivering status updates.
This is the experience waiting for most mid-market companies that skip the pre-work. That pre-work has a name: an AI readiness assessment.
According to OvalEdge, 80% of AI projects fail to deliver intended outcomes. That number gets cited constantly, but almost nobody asks the obvious follow-up: what are they failing on? If it’s not the AI model, not the use case, and not the team — what is it?
The answer, in almost every case, is the layer underneath. Infrastructure that was never built to serve AI. Data that exists but can’t be accessed in the format AI needs. Systems that were documented by the person who left three years ago, in a format no one can read.
This guide will show you exactly what an AI readiness assessment measures, where mid-market companies get stuck, and what a real pre-build diagnostic looks like before you spend another dollar on AI.
Quick answer: Why AI readiness assessments matter
- 80% of AI projects fail to deliver intended outcomes — and the failure almost never comes from the AI itself.
- The root cause is legacy infrastructure, undocumented systems, and missing data pipelines underneath the AI layer.
- An AI readiness assessment measures five dimensions: data, infrastructure, talent, governance, and strategic alignment.
- Most mid-market companies score between 22 and 38 out of 50 on their first assessment. The gap is normal, but ignoring it is costly.
- The right response is a pre-build diagnostic that addresses modernization and AI embedding simultaneously, not sequentially.
Why AI Projects Fail Before the First Line of Code Is Written
AI project failure starts at the foundation layer, not the AI layer. The model is rarely the problem. The data infrastructure underneath it almost always is.
According to OvalEdge, only 30% of AI pilots progress beyond the pilot stage. That means 70% of teams that build something promising hit a wall between the pilot and production phases. The wall isn’t a technical ambition. It’s an operational reality.
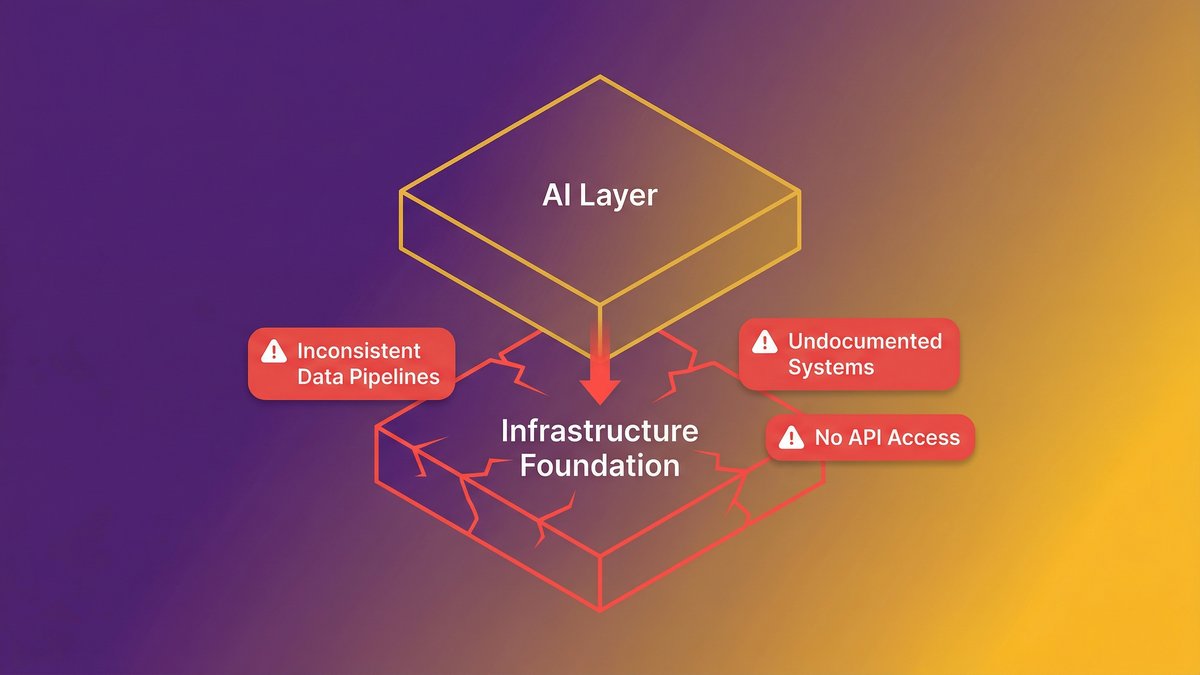
The real failure point: infrastructure, not intelligence
Here’s what that wall looks like in practice. A Series B SaaS company with 120 employees builds a promising AI feature during a three-month pilot. The model performs well in testing. Then the engineering team tries to deploy it against live data — and discovers the data pipelines feeding it are inconsistent, the systems generating that data weren’t designed with API-first architecture, and the ownership of the AI output is undefined. Legal gets involved. The pilot stalls.
Nobody failed at AI. They failed at readiness.
According to Arcade.dev’s 2026 State of AI Agents report, 46% of enterprises cite integration with existing systems as their primary AI deployment challenge. Not the model. Not the use case. The existing systems need the AI to work with.
This is the failure the standard project planning process misses entirely. Project plans start with the AI use case. They should start one layer below that.
Read: “Why legacy infrastructure blocks AI deployment.”
What 80% failure rate data actually reveals about organizational readiness
The MIT report cited in Fortune (August 2025) noted that 95% of generative AI pilots at companies are failing. OvalEdge puts the broader AI project failure rate at 80%. These numbers aren’t measuring bad AI. They’re measuring organizations that attempted AI before they were ready for it.
The pattern is consistent: organizations prioritize the AI layer and assume the infrastructure layer will accommodate it. It almost never does without deliberate preparation.
According to Forrester, 70% of digital transformations are slowed by legacy infrastructure. AI adoption is a digital transformation. The math applies.
What an AI Readiness Assessment Actually Measures
An AI readiness assessment diagnoses whether your organization’s infrastructure, data, talent, governance, and strategy can support AI deployment before you build anything. It’s a pre-investment diagnostic, not a post-failure autopsy.
The assessment doesn’t measure how sophisticated your AI ambitions are. It measures whether the foundation underneath those ambitions can hold the weight.
The 5 dimensions of enterprise AI maturity
Most credible AI readiness frameworks evaluate across five dimensions. Each one creates a different category of failure if it’s missing.
1. Data readiness: Is your data accessible to AI systems, not just stored somewhere? Data quality, labeling, pipeline architecture, and format consistency all matter. According to OvalEdge, 67% of organizations cite data quality issues as their top AI readiness barrier. The data exists. Getting it into a form AI can consume is the problem.
2. Infrastructure readiness: Are your systems built to serve AI workloads? API availability, cloud architecture, compute capacity, and system integration points all factor in. On-premises infrastructure with no upgrade path is the most common blocker in mid-market companies.
3. Talent and skills readiness: Does your team have the capability to build, maintain, and govern AI systems? According to OvalEdge, 52% of organizations lack AI talent as a readiness barrier. This isn’t just about hiring a data scientist — it’s about whether your engineering team can maintain what gets built.
4. Governance and ethics readiness: Who owns the AI output? What happens when the model produces something wrong? Do you have policies covering AI-generated decisions? According to OvalEdge, 91% of organizations need better AI governance and transparency. Most mid-market companies have no governance framework at all.
5. Strategic alignment: Is AI connected to a specific business outcome, or is it a technology initiative searching for a problem? Assessments score whether leadership has defined success criteria, ownership roles, and integration with business strategy — not just a technology roadmap.
Why most assessments miss the legacy infrastructure layer
Generic AI readiness assessments score well on paper for companies that have a technically modern infrastructure. But they systematically miss a category that specifically affects mid-market companies: undocumented legacy systems.
You might have a cloud-hosted application built in 2019 and an on-premises system built in 2008 that has never been formally integrated. The 2019 system scores well on infrastructure readiness. The 2008 system holds 60% of the operational data AI would need. That combination doesn’t show up cleanly in a standard assessment — and it’s the one that kills the project.
Read: “Legacy system modernization and AI readiness.”
The Legacy Infrastructure Problem No One Puts in the Assessment
Legacy infrastructure is the hidden variable in every AI readiness assessment. It’s often underdocumented, partially understood by a shrinking group of people, and structurally incompatible with the way AI systems need to consume data.
Most assessment frameworks treat infrastructure as a binary: you have cloud infrastructure, or you don’t. Real organizations have layers — some cloud, some on-prem, some somewhere in between. The assessment needs to go one level deeper.
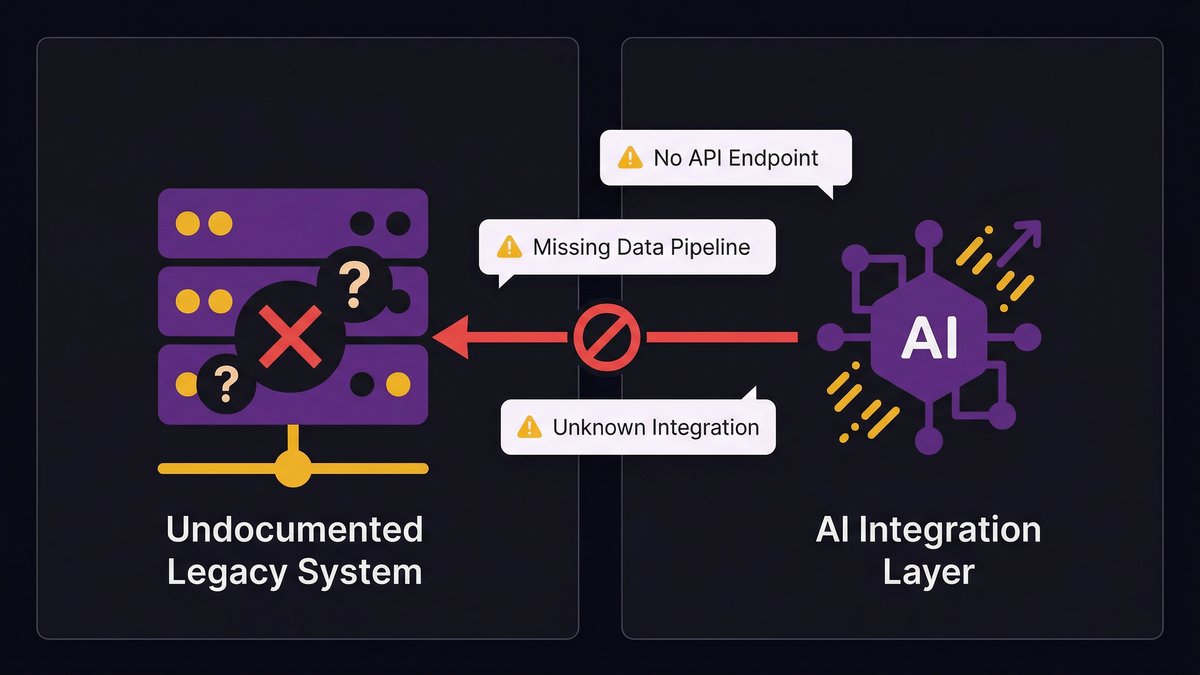
Undocumented systems and missing data pipelines: the invisible blockers
The highest-risk infrastructure problem isn’t outdated technology. It’s undocumented technology. A system running on a 2011 stack that’s fully documented, well-tested, and understood by your team is manageable. A system running on a 2023 stack built by a vendor who left no documentation, with three critical integrations no one remembers setting up and feeding data to five other systems in undocumented formats, is catastrophic.
AI needs reliable, structured data delivered through predictable pipelines. Undocumented systems can’t reliably provide either. You don’t know what data they’re actually producing, you can’t trace where it goes, and you can’t build a data pipeline on top of a system you don’t fully understand.
This is why the pre-build diagnostic has to go deeper than the assessment checklist. The checklist asks, “Do you have data pipelines?” The diagnostic asks, “Are those pipelines documented, tested, and owned by someone who’s still here?”
Why bolting AI onto a broken foundation fails every time
AI-on-top-of-legacy is the most common deployment pattern and the most reliable way to produce the failure rate OvalEdge is measuring. The logic sounds reasonable: build the AI layer, connect it to existing systems via API, and don’t touch the legacy infrastructure. You preserve operational continuity, limit the project scope, and ship faster.
Here’s what actually happens. The API connection works in testing, where data is clean, and volume is low. In production, the legacy system produces inconsistent data formats at unpredictable intervals. The AI model receives garbage, outputs garbage, and someone notices six weeks in. Then the conversation turns to whether the problem is the AI model, even though the problem has always been the data pipeline.
“Traditional modernization tends to over-index on protecting how things work today rather than building for what’s next,” says Skylar Roebuck, CTO at Solvd. “AI capability is compounding rapidly, and the real risk for mid-market companies is delay.”
That delay compounds when you build AI on top of a foundation that can’t support it. You don’t save time by skipping modernization. You create a rework cycle that costs more than the original modernization would have.
The mid-market gap: when your infrastructure was built before AI existed
Enterprise companies with Fortune 500 infrastructure face a different AI-readiness problem than mid-market companies. They have resources, dedicated engineering teams, and technology roadmaps that can absorb a multi-year modernization program.
Mid-market companies — 50 to 500 employees, operational systems that have compounded in complexity over 10 to 15 years — are in a different position. Their infrastructure was designed to run the business of 2012. It wasn’t designed to feed AI agents, expose clean APIs, or maintain data pipelines that meet modern consistency standards.
Unlike enterprise companies, mid-market organizations typically don’t have a dedicated platform engineering team to run modernization while the business continues to operate. The same engineers maintaining the legacy system are also responsible for any AI work. That structural constraint is the mid-market AI readiness gap — and a standard assessment framework won’t surface it.
Read: “Technical debt as an AI readiness blocker.”
Common AI Readiness Gaps in Mid-Market Organizations
Most mid-market companies share four specific readiness failures. They’re not unique — but they are predictable. Which means they’re diagnosable and fixable before you start building.
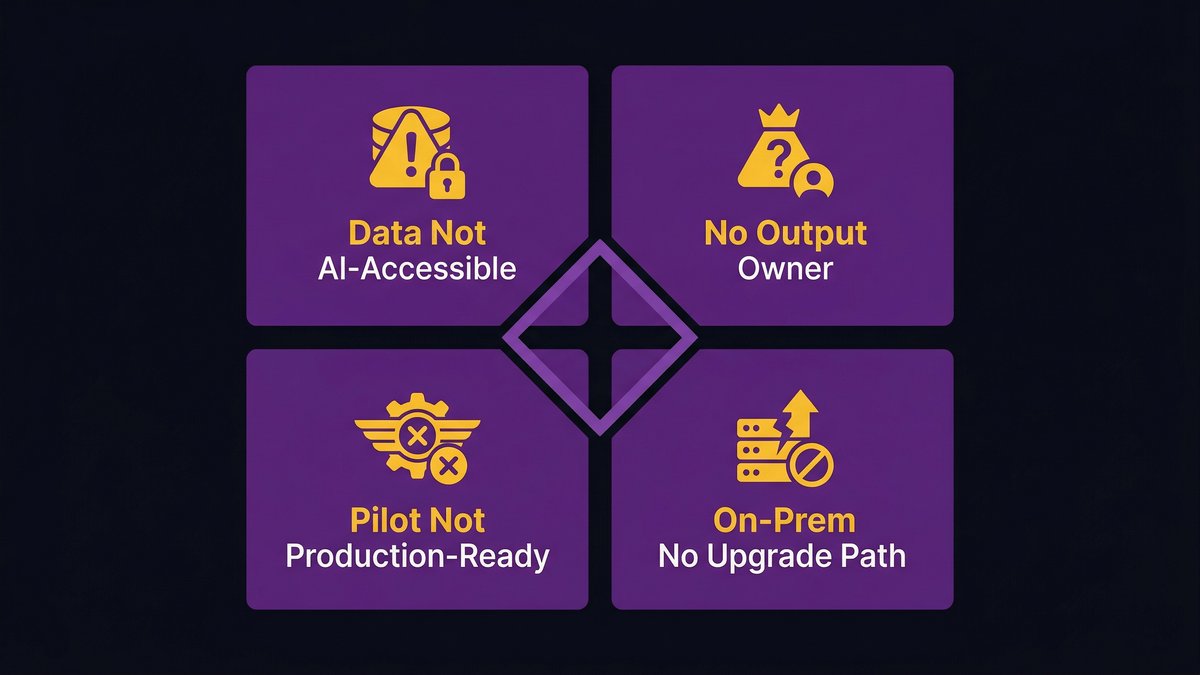
Data exists, but is not AI-accessible
This is the most common gap. Your company generates enormous amounts of operational data. It lives in your CRM, ERP, legacy databases, spreadsheets, and email archives. You know it’s there.
AI systems can’t access most of it. The data is in formats that require transformation before an AI model can consume it. The pipeline from storage to model doesn’t exist. The transformation logic for inconsistent formats hasn’t been written. So the data sits — full of signal, structurally inaccessible.
The assessment question “Do you have sufficient data?” almost always gets answered yes. The follow-up question “Is your data AI-accessible?” almost always gets answered no, once you dig one level deeper.
No one owns the AI output
If your AI system generates a recommendation, a prediction, or an automated decision — who owns that output? Who reviews it for accuracy? Who’s accountable when it’s wrong?
This question sounds simple. It rarely has a simple answer. Organizations building AI features often define ownership for the AI input (the model, the training data, the deployment infrastructure) and leave AI output ownership undefined. That gap creates liability exposure and makes production deployment politically impossible.
Every AI readiness assessment should require a named owner for AI output before any build begins. That person doesn’t need to be technical. They need to be accountable.
Pilot success mistaken for production readiness
A pilot that works in a controlled environment tells you the AI approach is sound. It doesn’t tell you the underlying infrastructure can support it at scale, with real data volumes, under production load conditions.
This is the specific failure behind the “only 30% of AI pilots progress beyond the pilot stage” statistic. The pilot succeeded. The infrastructure couldn’t support what the pilot proved was possible.
The gap between pilot and production is a readiness gap, not an AI gap. It requires the same infrastructure assessment you should have run before the pilot began.
Infrastructure is on-prem with no upgrade path
On-premises infrastructure isn’t automatically an AI readiness blocker. Documented, well-maintained, API-accessible on-prem systems can support AI workloads.
But on-prem infrastructure built before cloud architecture existed — with no APIs, no documented integration points, and no planned migration path — is a hard constraint. AI systems that need elastic compute, cloud-based model hosting, or real-time data access can’t run effectively against a locked-on-prem backend.
The assessment question isn’t “is your infrastructure on-prem or cloud?” The question is: does your infrastructure have a realistic path to supporting AI workloads in the next 12 months? If the answer is no, modernization needs to happen before AI deployment — not alongside it.
What a Pre-Build Diagnostic Looks Like in Practice
A pre-build diagnostic differs from a standard AI readiness assessment in one critical way: it’s designed to inform a specific build decision, not to generate a generic readiness score.
A standard assessment tells you where you stand across the five dimensions. A pre-build diagnostic tells you what has to change before you can build what you’re planning to build — and sequences that work so modernization and AI development happen simultaneously, not in separate phases.
The difference between an assessment and a diagnostic
An assessment scores your current state. It benchmarks you against a maturity model and identifies gaps. It’s useful for understanding where you are.
A diagnostic goes further. It maps your current state against the specific requirements of the AI capability you want to build. Instead of asking “are your data pipelines adequate?” — a generic assessment question — it asks “are your data pipelines adequate for the specific model and use case you’re planning, given your current data volumes, formats, and consistency levels?”
The difference sounds subtle. The operational implications are significant. A diagnostic produces a sequenced action plan. An assessment produces a gap report.
What Nexa maps before any modernization engagement begins
At Nexa Devs, no modernization or AI integration engagement starts without a pre-build diagnostic phase. This isn’t optional, and it isn’t billable overhead. It’s the mechanism that makes the subsequent build reliable.
The diagnostic maps four things before any code is written:
- Infrastructure topology — which systems exist, how they’re connected, which connections are documented, and which are held together by institutional knowledge that lives in one person’s head.
- Data pipeline audit — which data sources feed which systems, in what formats, at what frequency, with what consistency. Where the pipeline is broken, undocumented, or dependent on a manual process.
- AI use case compatibility — whether the specific AI capability being planned can be supported by the current data and infrastructure state, or whether infrastructure work needs to come first.
- Ownership mapping — who owns each system, who owns the data flowing through it, and who will own the AI output once it’s in production.
This diagnostic takes days, not weeks. It produces a written map the client owns. And it determines the sequence: what gets modernized first, what gets built alongside modernization, and what gets deferred.
How does simultaneous stack modernization and AI embedding work
The conventional approach sequences modernization and AI in two phases: modernize first, then build AI. This sounds logical. It’s slow, expensive, and creates a false choice.
Nexa’s approach runs both tracks simultaneously. Every sprint delivers two things: modernization work that cleans up infrastructure for AI compatibility, and AI feature development that operates against the progressively cleaner infrastructure.
This requires a team that understands both modernization and AI development concurrently — and a delivery process that can sequence work across both tracks without one blocking the other. That’s the structural capability the diagnostic phase establishes.
The result: clients don’t wait 12 months for modernization to be completed before seeing any AI capabilities. They see AI capability advancing in parallel with the infrastructure improvements that make it sustainable.
Ready to find out where your gaps actually are? Schedule a diagnostic call with Nexa Devs.
Read: “AI-augmented development process”
AI Readiness Maturity Levels: Where Mid-Market Companies Actually Score
The five-level maturity model is the standard framework for scoring AI readiness across dimensions. Most mid-market organizations land in a specific band — and knowing that band before you start is operationally useful.
The 5-level maturity model explained
Level 1 — Initial/Ad-hoc: No structured approach to AI. Individual tools are used opportunistically. No governance, no data strategy, no defined ownership. AI happens despite the organization, not because of it.
Level 2 — Developing: Some AI pilots underway. Data strategy is being defined. Technology infrastructure is being assessed. No production deployments at scale. This is where most mid-market companies start their assessment journey.
Level 3 — Defined: Repeatable AI processes in place. Data pipelines documented and maintained. Governance framework established. Some AI capabilities in production. The organization knows how to build and run AI — but not yet at scale.
Level 4 — Managed: AI capabilities are measured, monitored, and continuously improved. Infrastructure is AI-native. Governance is operational, not aspirational. Multiple production AI systems are running reliably.
Level 5 — Optimizing: AI is embedded in core operations. Continuous improvement loops run automatically. The organization generates its own AI capability advancement through learning and iteration.
Why most mid-market enterprises score between 22 and 38 out of 50
According to Intuz, most mid-market enterprises score between 22 and 38 out of 50 on their first AI readiness assessment. That range maps to Levels 2 and 3 in the maturity model — developing to defined.
This isn’t a failure. It’s a realistic starting point for organizations that have been running operational systems for a decade or more without AI in mind. The infrastructure exists. The data exists. The processes exist. None of them were designed for AI.
What this means practically: if you score in the 22–38 range, you’re not starting from scratch. You’re starting from an infrastructure that needs focused modernization in specific areas — not a complete rebuild — before AI development can proceed reliably.
The 5-Question AI Readiness Self-Assessment (Take It in 5 Minutes)
This isn’t a scoring tool. It’s a signal. Each question maps to one of the five dimensions of AI readiness. If you answer “no” or “I don’t know” to three or more, your organization needs a pre-build diagnostic before any AI investment proceeds.
Answer honestly — these questions are designed to surface the gaps that sink AI projects, not the ones that make you feel prepared.
Question 1 — Data accessibility
Can your team pull a clean, structured dataset from your primary operational systems in under 24 hours, without a manual extraction process and without calling the one person who knows the database schema?
If the answer is no, your data readiness gap will kill your AI project before the model is trained.
Question 2 — Infrastructure compatibility
Are your core operational systems accessible via documented, maintained APIs — or do they require direct database access, custom middleware, or tribal knowledge to query?
If any critical system is accessible only through undocumented integrations, your infrastructure can’t reliably feed an AI system in production.
Question 3 — Ownership clarity
Can you name the person in your organization who will be accountable for the accuracy and consequences of your AI system’s outputs — not the person who built it, but the person who owns what it produces?
If that person isn’t named yet, you don’t have governance. You have a liability.
Question 4 — Pilot-to-production track record
Has your organization successfully taken any software system from pilot to production in the past 18 months — not a vendor-hosted SaaS deployment, but a custom system your team built and now maintains in production?
If the answer is no, you have a production deployment readiness gap that will surface when you try to scale an AI pilot. The AI project won’t be the first thing this gap kills.
Question 5 — Use case specificity
Can you describe your AI initiative in a single sentence that includes: what it predicts or automates, using which data, to produce which measurable outcome, owned by which team?
If that sentence requires more than one “and” or leaves any of those four elements undefined, you don’t have a use case. You have a direction.
Score yourself: five yes answers means your organization has foundational readiness for AI development. Three or more ‘no’ or ‘don’t know’ answers indicate a pre-build diagnostic is the right first step — not another pilot.
What to Do After Your Assessment: From Diagnostic to Delivery
Once you’ve completed an AI readiness assessment or pre-build diagnostic, you have two kinds of output: a score and a sequence. The score tells you where you are. The sequence tells you what to fix and in what order.
Most organizations treat the assessment as the end of the process — they file the report and wait for budget approval to start modernization. That’s the wrong move.
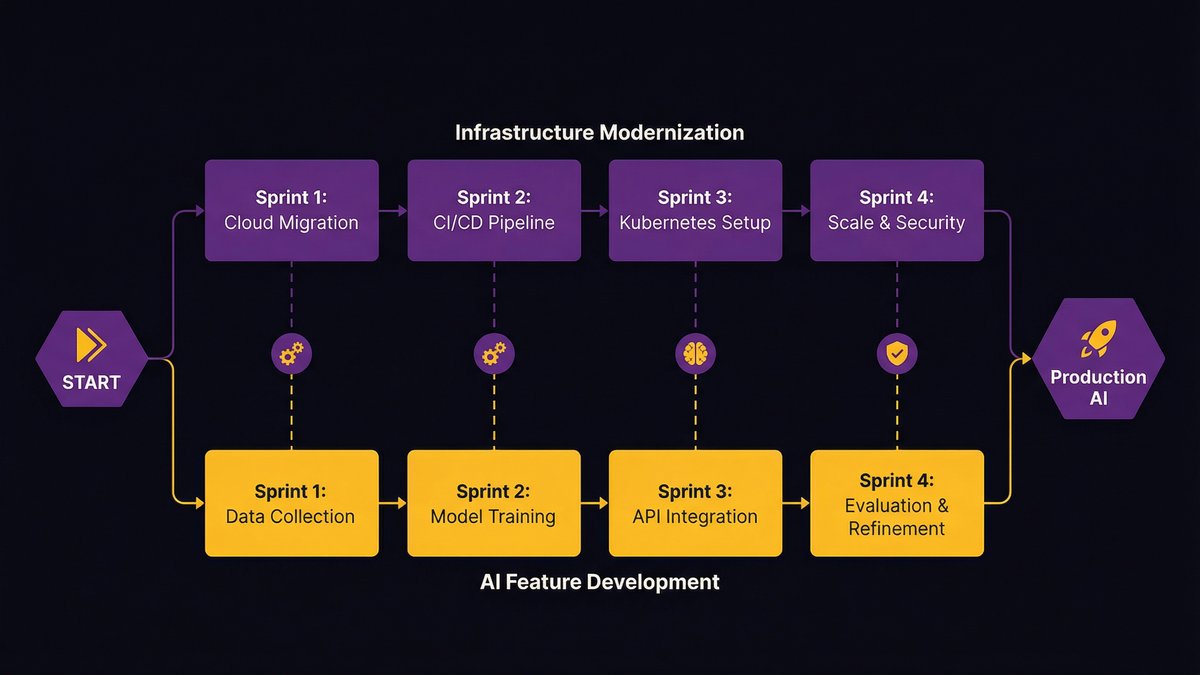
How to prioritize modernization before AI investment
The diagnostic produces a sequenced list of infrastructure improvements ranked by their impact on the AI capability you’ve committed to building. Start there — not with the longest list of improvements, but with the specific changes that unblock the target use case.
A common mistake is treating infrastructure modernization as a prerequisite that has to be completed before AI development starts. This turns a 6-month AI project into an 18-month program.
The better approach is modular: identify the minimum viable infrastructure state that supports the AI use case, modernize to that state in parallel with early development, and treat further modernization as ongoing work. According to Deloitte, nearly 60% of AI leaders identify legacy system integration as their primary barrier to agentic AI adoption. The organizations that succeed don’t eliminate that barrier before starting — they sequence around it.
Why AI-augmented development from day one beats retrofitting
If you’re modernizing your infrastructure to support AI, the development team doing that modernization should use AI in their delivery process. Not as a feature — as the delivery mechanism.
When AI is embedded in the modernization process itself, two things happen. The work moves faster. AI-augmented development teams achieve higher test coverage, cleaner architecture, and more consistent documentation than traditionally staffed teams working at the same pace. And the systems that emerge from that process are inherently better suited to AI integration, because they were built by a team that understands AI requirements from the inside.
Retrofitting AI onto a system built without AI in mind requires translating every integration point, every data format, and every API contract. Starting with AI-augmented development produces systems where those integration points, formats, and contracts were designed for AI compatibility from the first sprint.
That’s the structural advantage of addressing both layers simultaneously. Not AI-on-top-of-legacy. Not modernization-then-AI. Both, from day one.
The Diagnosis Comes Before the Build
Every AI project that failed in the past three years had a moment where someone saw the gap and kept moving anyway. The pilot looked good enough. The use case was compelling. The budget was approved. The gap — in the data, the infrastructure, the documentation, the governance — got deprioritized.
That’s the decision this post is designed to interrupt. The AI readiness assessment isn’t bureaucratic overhead. It’s the work that determines whether the build that comes after it has a chance of making it to production.
Most mid-market companies score between 22 and 38 out of 50. That’s not a disqualifying score. It’s a starting point. The question is whether you address the gaps before or after you’ve spent the budget.
If you want to know exactly where your gaps are and what it would take to close them, the pre-build diagnostic is the right first step — not another pilot, not another assessment checklist.
Schedule a diagnostic conversation with Nexa Devs. We’ll map your infrastructure against your AI use case and tell you specifically what needs to change before development begins.
FAQ
What are the 4 pillars of AI readiness?
The four most consistent pillars are: data readiness (accessible, structured, quality-controlled data), infrastructure readiness (systems that support AI workloads), talent readiness (capability to build and maintain AI), and governance readiness (ownership, accountability, and ethics framework). Most comprehensive frameworks add strategic alignment as a fifth pillar.
What is an AI readiness framework?
An AI readiness framework is a structured model for evaluating your organization’s ability to build, deploy, and maintain AI systems. It scores the current state across data, infrastructure, talent, governance, and strategy — producing a maturity score that identifies gaps and prioritizes improvements before any AI build begins.
What is the AI readiness process?
The AI readiness process runs in three stages: a structured assessment that scores the current state and maps gaps; a sequenced improvement plan that prioritizes infrastructure and data work by impact on the target use case; and a build phase against progressively improved infrastructure, with governance in place before AI output enters production.
Why do most AI projects fail before reaching production?
Most AI projects fail because the infrastructure, data pipelines, and governance beneath the AI layer aren’t ready for production workloads. Pilots work with clean data and low volume. Production exposes inconsistent data formats, undocumented integrations, undefined output ownership, and infrastructure that can’t scale. The AI doesn’t fail — the foundation does.