
Table of Contents
The Tacit Knowledge Time Bomb: Why Your Most Important Software Knowledge Can’t Be Written Down
You’ve probably run the documentation initiative. Maybe twice. You told the team to write everything down: the architecture, the decisions, the edge cases. Six months later, you had a wiki that was already out of date and a codebase that was just as opaque as before.
That’s not a discipline problem. It’s a structural one. And the consequences, for your systems, your vendor relationships, and your business continuity, are more serious than most CEOs and COOs recognize until something breaks.
Institutional knowledge loss in software development happens when the people who understand how a system works leave before that understanding transfers. It’s the senior engineer who “just knows” why the billing module can’t run before 2 AM. It’s the vendor team that built your platform over four years and never wrote down a single architectural decision. It’s the system that works until someone leaves, and then it doesn’t.
The tacit knowledge time bomb is already ticking in most mid-market organizations. This guide explains why, and what the structural fix actually looks like.
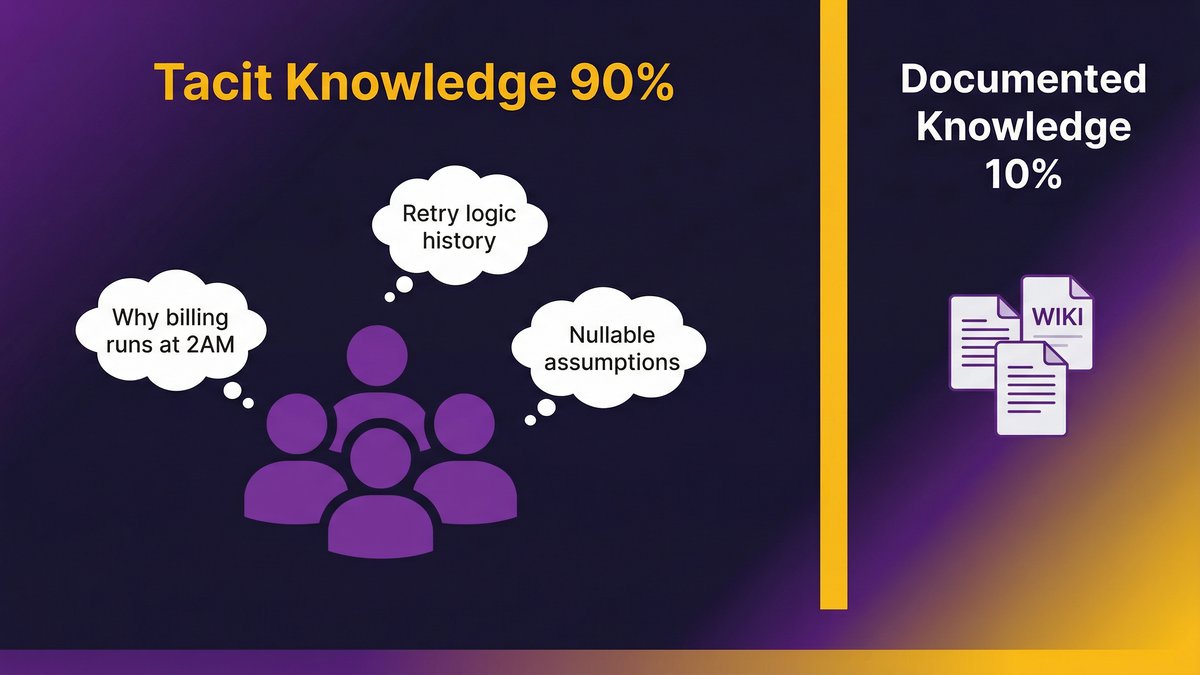
The 90/10 Problem: Why Most of What Your Software Team Knows Is Invisible
Most of what your engineering team knows about your software cannot be written down. Full stop.
According to docs.bswen.com (2026), tacit knowledge comprises approximately 90% of organizational knowledge. Documented knowledge, the wikis, runbooks, architecture diagrams, and code comments, represent only 10%. And that 10% is rarely up to date.
That asymmetry is the core problem. Every documentation initiative your organization has run has tried to close a 90/10 gap with a strategy designed for 10% of the knowledge. It was never going to work.
Explicit vs. tacit knowledge in software systems
Explicit knowledge is what you can write down: API contracts, database schemas, deployment scripts, and user story libraries. It transfers cleanly. A new engineer can read it and act on it.
Tacit knowledge is everything else. It’s the reasoning behind architectural decisions that were never recorded. It’s knowing which database columns are technically nullable but functionally never null because three integrations depend on that assumption. It’s the production incident from two years ago that shaped how the team now thinks about retry logic, an incident that probably isn’t in your Jira backlog anymore.
No wiki captures that. No AI summarizer can reconstruct it from the codebase alone. It lives with specific people.
Why documentation initiatives consistently fail to close the gap
The failure pattern is predictable. Engineers are busy. Writing documentation isn’t shipping features. The initiative runs for a quarter, the wiki gets seeded, and then it slowly drifts from reality as the system evolves, and no one has time to maintain it.
There’s also a deeper problem: most tacit knowledge can’t be articulated even by the person who holds it. Ask a senior engineer why they built something a certain way, and they’ll say “it just felt right” or “I tried the other approach, and it broke something.” The reasoning is real. It’s just not in a form that can be extracted and stored.
Developers spend approximately 60% of their time understanding legacy code and only 5% writing new code. That number isn’t a productivity failure. It’s the cost of tacit knowledge concentration, knowledge that was never transferred and now has to be reverse-engineered every time someone new touches the system.
Read: “Tacit knowledge in software teams.”
The Bus Factor Is a Business Continuity Problem, Not an Engineering Problem
The bus factor measures how many people in your organization would need to be hit by a bus, quit, get poached, or burn out before a critical project collapses. A bus factor of one means a single person’s departure would leave you with a system nobody understands.
Most mid-market teams have a bus factor of one or two. This is not a theoretical concern.
What your bus factor actually measures, and how to assess yours
Your bus factor is effectively your concentration of tacit knowledge risk. It answers: “How few people currently hold the understanding this system needs to keep functioning?”
A bus factor of one means you have a single point of failure in a system that your business depends on. A bus factor of two is better, but not by much. According to LinuxSecurity.com (2026), citing JetBrains Bus Factor Explorer March 2026 data, MySQL, PostgreSQL, and SQLite all have a bus factor of two, meaning only two contributors understand the full codebase. For critical infrastructure, a bus factor below five is considered high risk.
To assess your own: list your three most critical software systems. For each one, ask how many people could explain its full operational behavior, not just the API surface but the deployment dependencies, the historical quirks, the undocumented assumptions. If the answer for any system is two or fewer, you have a live continuity risk.
Real business impact: project delays, cost of replacement, and system fragility
When a high bus-factor person leaves, the cost isn’t just the salary. According to ClearlyAcquired (2026), replacing high-level technical talent can cost 150–400% of their salary and delay projects by 6–12 months when knowledge hasn’t been transferred, with new hires requiring 16–20 weeks to reach full productivity.
For a senior engineer earning $130,000, the replacement cost ranges from $195,000 to $520,000. Before they’ve shipped a line of code.
The disruption isn’t linear either. Knowledge loss compounds. A key person exits. Their replacement spends months reverse-engineering what was obvious to their predecessor. They make conservative choices, touching as little as possible, which means features slow down and technical debt accumulates. The system gets more fragile because the person maintaining it is operating partially blind.
Read: “Key person dependency in software development.”
When Your Vendor Holds the Knowledge: The Hidden Risk in Software Outsourcing
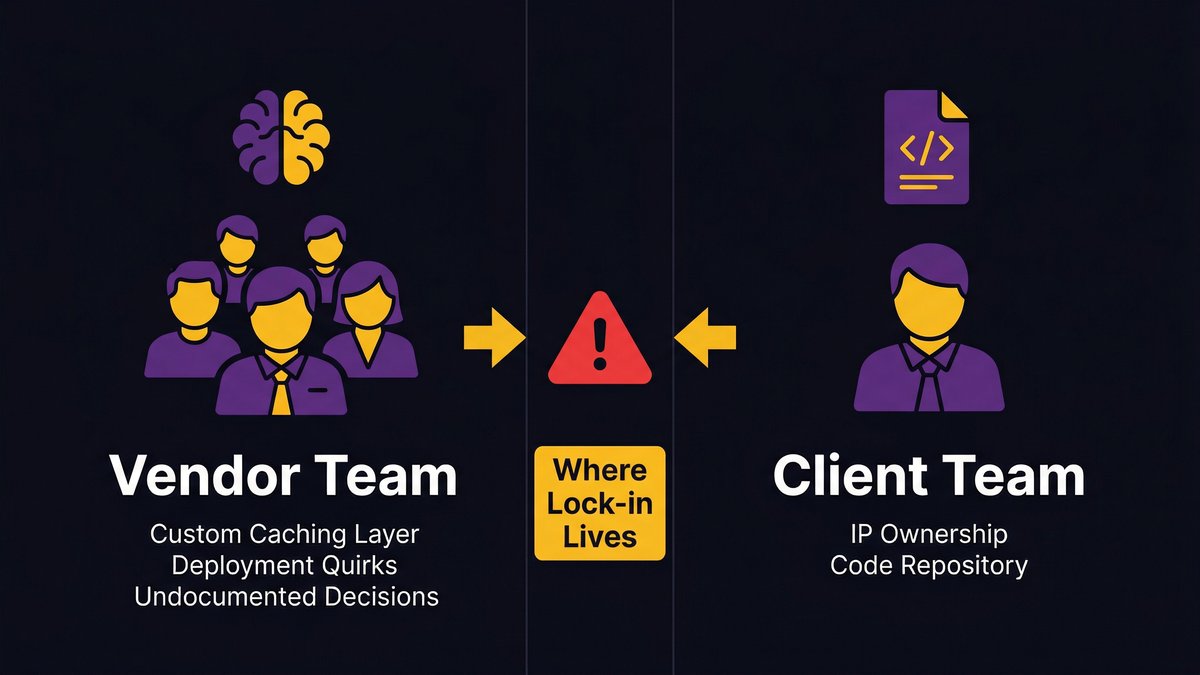
Here’s what most CEOs and COOs don’t account for: the bus factor problem isn’t limited to your internal team. It applies to every vendor relationship you have.
If a software vendor has been building and maintaining your platform for three years, they hold most of the tacit knowledge about how that system actually works. Your internal team has been involved, but they probably can’t explain the data flow across modules, the rationale behind the infrastructure choices, or what would break if you needed to migrate to a different hosting provider.
You may legally own the code. You don’t practically control the system.
The difference between owning code and controlling a system
Legal code ownership and operational control are not the same thing. According to Pragmatic Coders, “You can own the code’s copyright and still be locked in. Formal ownership isn’t the same as practical control over the product. Many companies formally own the IP but lack real, operational control over their product. The gap between formal ownership and practical control is where lock-in lives.”
That gap is the tacit knowledge gap. It’s not in your IP agreement. It’s a fact that only three people at your vendor understand the custom caching layer they built, and none of them are on your payroll.
How knowledge concentration at the vendor level creates dependency, even with IP ownership clauses
This form of lock-in is more durable than technical lock-in. You can migrate off a proprietary database. You can’t easily reconstruct four years of undocumented architectural decisions.
Consider what happens when you need to switch vendors or bring development in-house. Your new team inherits a codebase with no Architecture Decision Records, no documented deployment runbook, and a handful of modules that nobody outside the original vendor team has ever touched. The onboarding takes months. The first sprint is mostly archaeology. The first production incident exposes something nobody knew was there.
Fortune 500 companies lose $31.5 billion annually due to the failure to share information. A significant portion of that loss lives in the vendor handover gap, the institutional knowledge that is transferred contractually but not practically.
What Vendor Transition Failure Actually Looks Like
Vendor transitions don’t usually fail at the handover. They fail six months later.
The handover meeting went fine. Code is transferred. Documentation is delivered, typically including a README, some API specs, and any architecture diagrams the vendor can produce in the final sprint. Everyone shakes hands. Then the new team starts working.
Documentation gaps, undocumented dependencies, and lost configuration details
According to Dreamix, inadequate knowledge transfer is one of the most common causes of transition failure: “Documentation gaps, undocumented dependencies, and lost configuration details create expensive problems months after transition completion.”
The new team doesn’t know what they don’t know. They discover the undocumented dependency when a scheduled job fails on the first of the month. They find the missing configuration detail when they deploy to staging, and everything breaks in a way that looks random. The lost architectural decision surfaces when they try to add a feature, and the code structure actively resists the change.
Each discovery costs time. The compounding effect is that the new team loses confidence in the system and starts making changes conservatively, which slows velocity further and accumulates more technical debt.
Why do transition failures emerge months after the handover, not at the handover?
There’s a delay built into the failure pattern. Most systems have seasonal or periodic behavior, month-end batch jobs, quarterly reports, and annual audit exports. The new team won’t encounter those pathways until the calendar triggers them. When they do, they’re operating without the tacit knowledge that the original team used to handle them.
This is why the immediate post-handover period looks fine. The system runs. The obvious features work. The new team reports no critical issues. Three months later, the first month-end cycle runs, and suddenly there’s a production incident nobody can explain.
Read: “Software vendor transition documentation.”
The Structural Solution: Building Systems That Outlive the People Who Built Them
Documentation initiatives fail because they’re retrofitted onto a delivery process that doesn’t naturally produce documentation. The fix isn’t discipline, it’s structure.
A delivery process that systematically captures tacit knowledge doesn’t ask engineers to write documentation after the fact. It builds documentation into every decision as it’s made. The output is a system that any competent engineer can understand, maintain, and evolve, regardless of whether the original builders are still involved.
Three mechanisms make this work in practice.
Architecture Decision Records (ADRs): documenting the ‘why’, not just the ‘what.’
An Architecture Decision Record is a short document that captures one architectural decision: what was chosen, what alternatives were considered, and why the chosen approach was taken. Not the code, the reasoning.
ADRs are the closest thing to capturing tacit knowledge that exists in practical software engineering. They don’t capture everything. But they capture the most important decisions, the ones that shaped the system’s structure, the tradeoffs that were deliberately accepted, the paths that were explored and rejected.
A system with complete ADRs is fundamentally more transferable than one without them. A new team can read the ADR for why the caching layer works the way it does and understand the constraints the original team was operating under. Without that record, they’re guessing.
ADRs should be written at decision time, not retroactively. Retroactive ADRs are reconstructions; they capture what was decided, but not the actual reasoning, which is already partially lost.
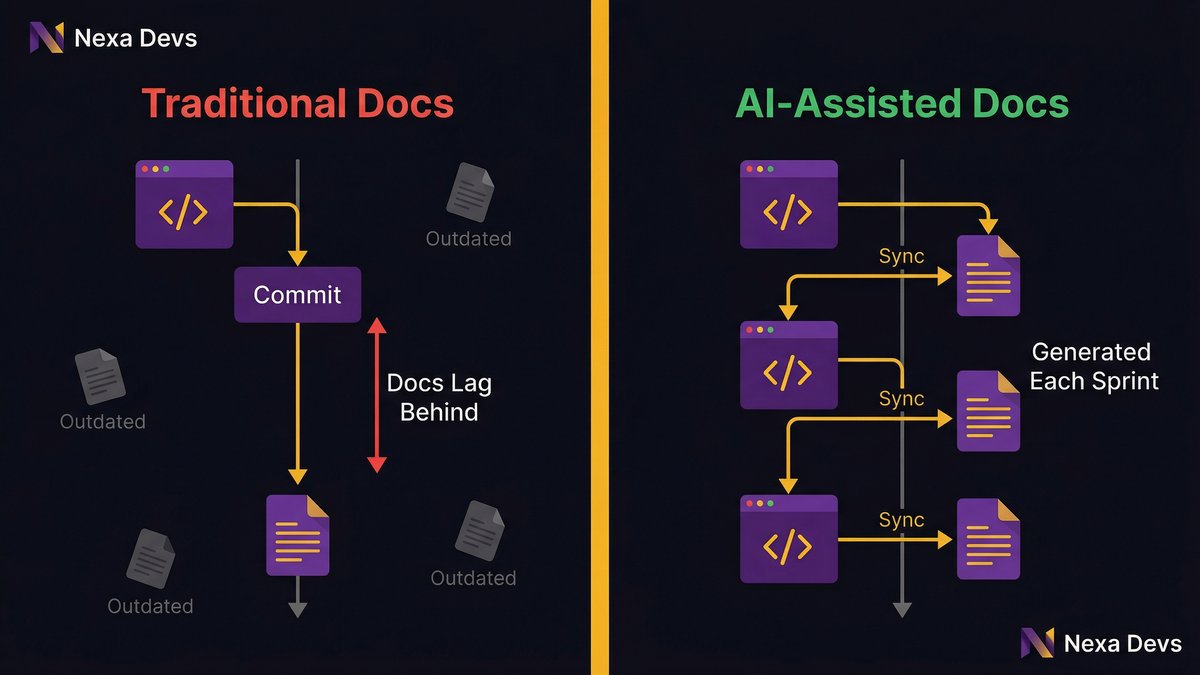
AI-assisted documentation: how modern tooling closes the tacit knowledge gap at scale
AI tooling has changed what’s possible in documentation. Modern AI-assisted development workflows can generate documentation artifacts continuously, user stories, API references, deployment runbooks, and test coverage summaries as part of the delivery process rather than as a separate phase.
This matters because the traditional documentation problem was a time-and-incentive problem: engineers needed time they didn’t have and had no strong incentive to spend it on documentation. AI-assisted tooling eliminates the time cost. Documentation that previously took a senior engineer half a day to produce can be generated, reviewed, and committed in minutes.
The result is documentation that stays current because it’s generated alongside the code rather than written separately.
Unconditional documentation transfer: what it means in practice
Unconditional documentation transfer means every documentation artifact produced during the engagement is transferred to the client at project close, regardless of whether the engagement continues. Not licensed. Not accessible via the vendor’s portal. Owned by the client.
This is different from standard practice. Most vendors deliver code and a README. The internal project knowledge, the sprint history, the architectural decisions, the test coverage reports, and the system design documents typically stay with the vendor or get lost in the transition.
Unconditional transfer means you end the engagement with the documentation you’d want if you were hiring a new engineering team tomorrow. Because you might be.
Knowledge Sovereignty: What You Should Own Beyond the Code
Knowledge sovereignty is the condition where you, not your vendor, hold practical control over your system. You own the code legally. You also understand it operationally. Your team can maintain it, evolve it, and explain it to a new vendor without the original builders in the room.
Most organizations that believe they have knowledge sovereignty don’t. They have code ownership. It’s not the same thing.
Practical control vs. legal ownership, the gap where lock-in lives
The legal contract says you own the IP. But do your internal team members understand the system’s deployment architecture? Do they know what would break if you changed your hosting provider? Can they explain the data flow between the modules your vendor built?
If the answer is no, your knowledge sovereignty is nominal. Your practical dependency on the vendor is real, and that dependency doesn’t expire when the contract does.
The gap between legal ownership and practical control is exactly where vendor lock-in lives. It’s invisible in the contract. It’s very visible when you need to switch vendors.
A checklist: what a knowledge-sovereign software engagement looks like
Before you sign or renew a software development engagement, verify:
- Architecture Decision Records: Does the vendor produce ADRs as a standard deliverable? Are they committed to the codebase, or are they stored somewhere the client owns?
- Unconditional documentation transfer: Is every documentation artifact transferred at project close, regardless of engagement continuity?
- System design documents, UML architecture diagrams, data flow diagrams, and integration maps- are these client-owned deliverables or internal vendor artifacts?
- Onboarding independence, could a competent external engineer onboard to this system using the documentation alone, without calling the vendor?
- Deployment runbook: Is there a documented, tested process for deploying, rolling back, and diagnosing production issues?
- No undocumented dependencies. Are all external integrations, credentials, and configuration dependencies documented in a format the client controls?
A vendor that can’t answer yes to all six items is concentrating on knowledge they should be transferring. That concentration is a risk you’re carrying.

What 10+ Years of Embedded Partnership Actually Produces
There’s a structural difference between a project-based vendor relationship and a long-term embedded partnership. The difference isn’t just tenure. It’s a knowledge direction.
In a project-based engagement, the vendor accumulates knowledge about your system and takes it with them when the project ends. Your organization ends the engagement with the code and a documentation gap. The vendor ends it with an institutional understanding that they can apply elsewhere.
In a long-term embedded partnership, knowledge flows in both directions.
How long-term embedded relationships structurally prevent knowledge concentration
A vendor team that has worked with your organization for eight or ten years understands your system the way an internal team would, but with the documentation discipline that internal teams rarely maintain. They know the history. They’ve built the ADRs. They’ve seen the system evolve through four major initiatives and know why the architecture looks the way it does.
Critically, they have a structural incentive to keep that knowledge transferable. If the engagement is ongoing and the client can credibly switch vendors, the embedded team knows the documentation needs to be good enough that a replacement team could take over. That incentive doesn’t exist in a project-based relationship where the vendor exists at launch.
Nexa’s longest client relationships, UCLA David Geffen School of Medicine (10+ years), TSB (8+ years), Townsend (5+ years), are not retained because of price or proximity. They’re retained because the accumulated system knowledge, maintained in transferable form, creates genuine value that compounds over time.
The compounding knowledge advantage: clients accumulate, not depend
Every year of an embedded partnership where documentation is maintained as a deliverable, the client’s knowledge position improves. The ADR library grows. The system design documents stay current. The onboarding materials reflect the current state of the system.
A client who could not have replaced their vendor three years ago can now. Not because the vendor got easier to replace, but because the knowledge was deliberately kept in client-owned form throughout the relationship.
That’s the structural opposite of knowledge lock-in. It’s also the condition that makes a long-term embedded partnership genuinely different from a recurring project-based dependency.
If you’re evaluating your current vendor relationship and want to understand where your knowledge position actually sits, start with an architecture assessment. That conversation will surface what your team actually controls versus what it only legally owns.
The Knowledge You Don’t Own Is a Risk You’re Carrying
Your software systems are assets. The knowledge required to maintain them is also an asset. The question is who holds it.
If the answer is “a few specific people”, internal or vendor, you’re exposed. That exposure compounds every quarter. The knowledge gets more concentrated, the system gets less documented, and your practical dependency on those few people grows.
The structural fix starts with demanding transferable knowledge as a deliverable, not a byproduct. ADRs as standard output. Documentation that’s generated alongside code, not retrofitted after. Unconditional transfer at project close.
That’s not a new vendor category. It’s a different standard, one you can write into your next engagement.
Want to understand where your current knowledge position actually sits? Reach out to Nexa Devs for a no-cost architecture assessment. We’ll tell you what your team actually controls.
FAQ
What does loss of institutional knowledge mean?
Loss of institutional knowledge means that when key people leave, they take understanding that was never documented or transferred. In software development, this makes systems that work become systems nobody fully understands, raising maintenance costs and increasing vendor dependency.
What is the impact when institutional knowledge of IT processes is not captured and recorded?
When IT process knowledge isn’t captured, organizations face longer onboarding times, higher error rates during changes, and growing vendor dependency. Developers spend roughly 60% of their time understanding legacy code rather than building new capabilities (CAST Software).
What are key person dependencies?
A key person dependency exists when one individual holds critical knowledge that no one else has. In software teams, this is typically a senior engineer whose departure would stall the project until knowledge is reconstructed, at significant time and cost.
What is the bus factor in business?
The bus factor is the number of people who would need to leave before a critical project collapses. A bus factor of one means one departure causes a crisis. Even major databases like MySQL and PostgreSQL have a bus factor of two, meaning only two contributors hold a full system understanding (LinuxSecurity.com, 2026).
How can we reduce the bus factor?
Reduce bus factor through pair programming, code reviews, Architecture Decision Records, and cross-training. For vendor relationships, require unconditional documentation transfer as a contract term. The goal is to ensure no single person’s departure leaves any system unmanageable.
What are the 4 C’s of knowledge management?
The 4 C’s are Capture, Curate, Connect, and Communicate. In software: Capture means producing ADRs and system design documents during delivery. Curate keeps them current. Connect the links’ knowledge to the systems it describes. Communicating makes it accessible to any engineer who needs it.