
Table of Contents
Your CTO bought the AI tools. Your team ran the pilot. It didn’t work, or it worked in a sandbox and collapsed the moment you tried to connect it to anything real. So you hired a consultant, who told you to “modernize your data layer” before going further. Two months later, you’re no closer to AI capability, and the budget is gone.
This isn’t a procurement problem. It’s not a talent problem. It’s an architecture problem. And most organizations don’t find out until they’ve already spent the money.
Legacy system AI integration fails for a specific, diagnosable reason: legacy systems weren’t built to support AI workloads, and bolting AI onto them doesn’t change their underlying structure. Before you spend another dollar on AI tooling, you need to understand exactly what’s blocking you, and what it actually takes to remove that block.
Why Your Legacy System Isn’t Just Slow, It’s AI-Proof
A legacy system isn’t hard to integrate with AI; it’s structurally incompatible with AI. That’s a different problem, and it requires a different solution.
Most organizations discover this distinction the hard way. They assume legacy integration is a plumbing problem: connect system A to system B, configure an API, ship it. What they find instead is that the system can’t be connected to anything without significant structural work, because it was never designed to be.
The structural difference between ‘hard to integrate’ and ‘architecturally incompatible.’
A system that’s hard to integrate has APIs, but they’re poorly documented or inconsistently implemented. A system that’s architecturally incompatible with AI has no meaningful API surface at all. Business logic is embedded in the database layer, in stored procedures, in ETL jobs that run overnight and can’t be queried in real time. The system’s data model reflects a decade-old understanding of the business, and no one fully knows how it works anymore.
AI systems need clean, accessible, real-time data. They need APIs that can receive requests and return structured responses. They need infrastructure that can scale to support inference workloads. Legacy systems were built to do none of these things.
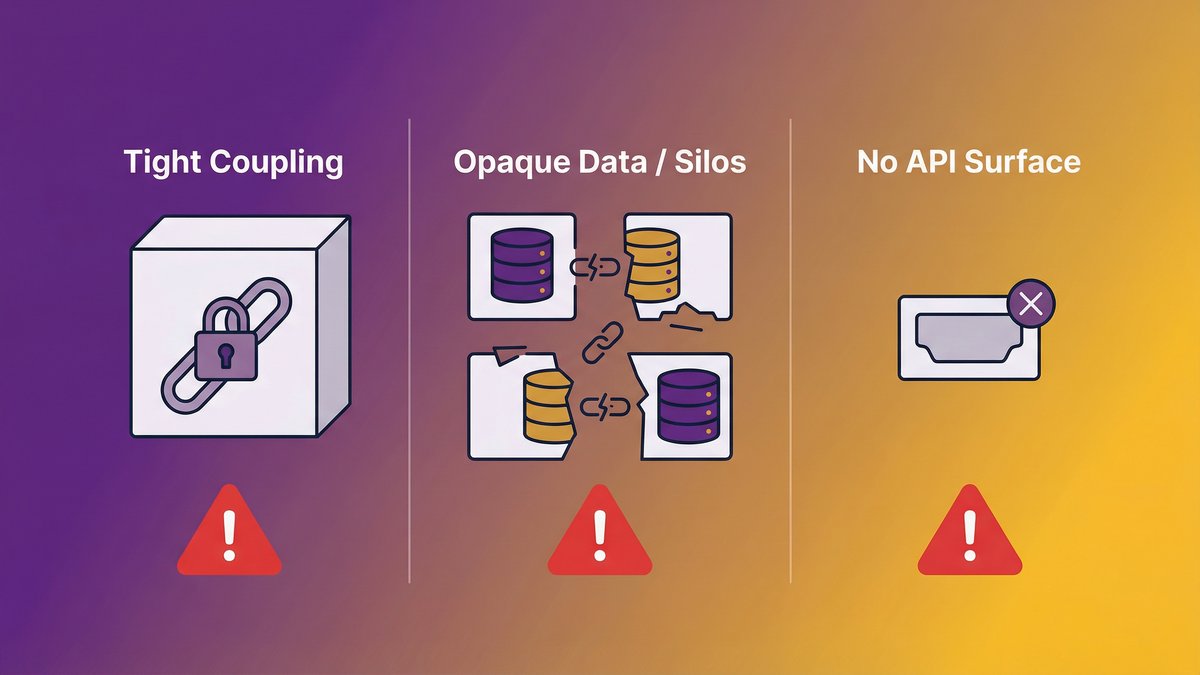
What makes a system AI-proof: monolithic coupling, opaque data, and absent APIs
Three structural properties make a system AI-proof:
Tight coupling. Monolithic architectures bind business logic, presentation, and data into a single unit. You can’t change one part without affecting the others. Adding AI requires inserting new logic at specific points in the system, but when everything is coupled together, there are no clean insertion points.
Opaque data. Legacy systems often store data in formats that made sense in the 1990s: denormalized tables, proprietary binary formats, and undocumented field encodings. The data exists, but it can’t be extracted, cleaned, or used without significant transformation work. AI models need consistent, well-structured data to produce reliable outputs. Legacy data is rarely consistent or well-structured.
Absent APIs. If your system has no API layer, external services, including AI, can’t interact with it. You can’t send a request, you can’t receive a response, and you can’t integrate without building an API layer from scratch. That’s not an integration task. That’s a modernization task.
What legacy system modernization actually costs, read our blog post: “Legacy System ROI: Real Numbers from Companies That Actually Modernized.”
The Business Cost of Running AI on a Broken Foundation
Forcing AI onto a legacy infrastructure doesn’t deliver AI capability. It delivers failed pilots, wasted licenses, and a team that stops believing AI is worth trying.
This is where the CEO’s perspective matters most. You’re not evaluating architecture diagrams; you’re evaluating whether this investment is going to produce results. And right now, for most mid-market organizations, it isn’t. Not because AI doesn’t work, but because the foundation it’s running on was never designed to support it.
What happens when you force AI onto legacy infrastructure
The pattern is consistent. An organization buys an AI tool or builds a pilot. It works in isolation, in a clean dataset, in a sandbox environment, disconnected from production systems. The moment the team tries to connect it to the real system, the integration breaks. Data is missing or wrong. The system can’t handle the additional query load. Business logic that was assumed to be captured in the data turns out to be scattered across five different tables and three stored procedures.
The pilot gets shelved. The vendor relationship sours. The engineering team spends three months debugging the integration instead of building a new capability. You’re back where you started, but now you’ve spent the budget.
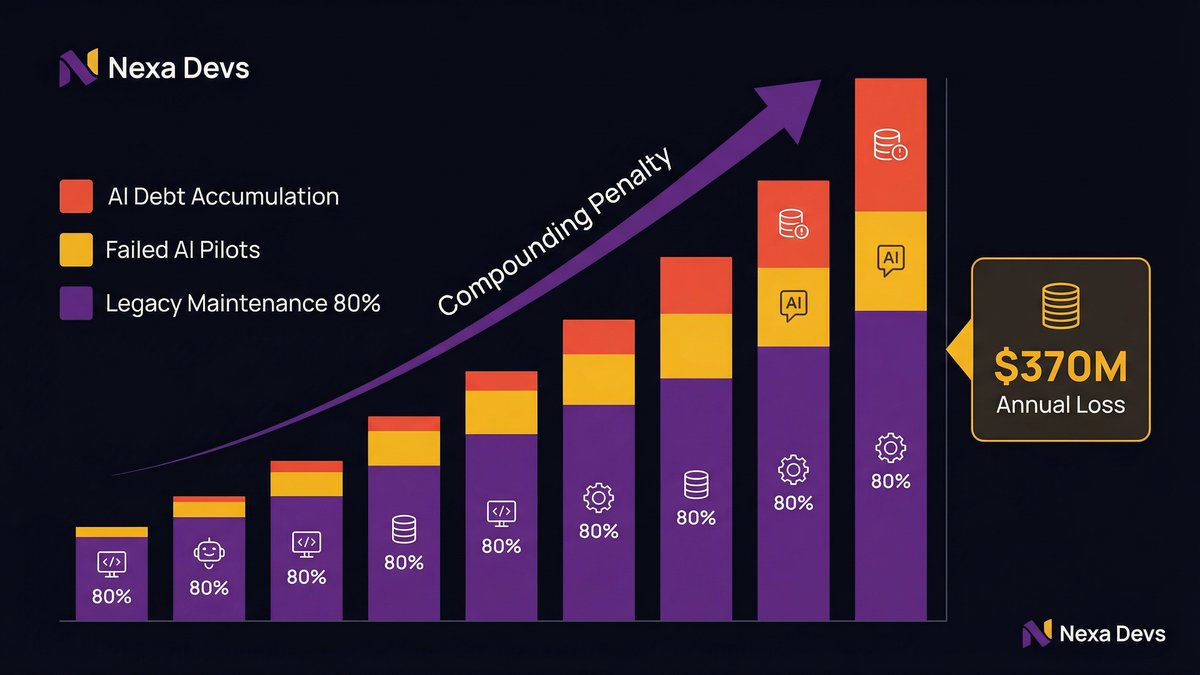
According to ncube.com, citing 2025–2026 data from Deloitte, Gartner, and McKinsey, legacy-heavy organizations spend up to 80% of their IT budgets on maintenance and support, leaving just 20% for innovation. When 80% of your budget is keeping the lights on, there’s very little left to fund the transformation work AI actually requires.
The compounding penalty: technical debt plus AI debt
There’s a second-order effect that most AI strategy discussions miss. Every failed AI initiative adds to your organization’s technical debt. You end up with half-implemented AI layers, abandoned middleware, prototype integrations that nobody maintains, and a codebase that’s now more complex than it was before you started.
According to makingsense.com, citing recent research from ITpro, enterprises report losing around $370 million annually due to outdated technology and the burdens of technical debt. That figure is pre-AI. Add the cost of failed AI initiatives on top of existing debt, and the compounding penalty becomes significant fast.
As Cesar DOnofrio, CEO and co-founder of Making Sense, put it: “When legacy systems limit access to reliable data, slow down integration across workflows, or make change deployment complex and time-consuming, AI initiatives stop being strategic levers and become isolated experiments. Organizations may be able to run pilots, but they cannot operationalize or scale them.”
The Five Structural Barriers That Block AI Adoption
Five specific structural problems make legacy system AI integration fail. They’re not configuration issues. They’re architecture issues.
Understanding which of these is blocking you determines the right path forward.
Incompatible architecture: monoliths, tight coupling, and missing APIs
Monolithic architectures can’t support AI integration without significant structural changes. AI systems need to interact with specific functions, not the entire application. When everything is coupled together, you can’t reach one part without going through all the others. Decomposing a monolith into AI-accessible services is a months-long modernization project, not an integration task.
Data silos and quality: AI cannot learn from data it cannot access or trust
According to tredence.com, citing McKinsey, 70% of software in Fortune 500 companies is over two decades old. Systems that old were built before data integration was an architectural priority. Data lives in separate systems that don’t talk to each other, in formats that aren’t machine-readable, with quality problems that have accumulated over decades.
AI models produce outputs proportional to the quality and completeness of their inputs. Garbage in, garbage out. If your data is siloed, inconsistent, or inaccessible, no AI model will overcome that. Clean, consolidated data isn’t a nice-to-have; it’s the prerequisite.
Scalability deficits: legacy infrastructure cannot sustain AI workloads
Running inference on a language model or processing real-time predictions requires compute resources that legacy infrastructure wasn’t sized to support. On-premise servers from ten years ago, or cloud configurations optimized for batch processing, can’t handle the concurrent request volumes AI generates at production scale. Scaling the infrastructure isn’t optional; it’s required before AI can move past pilot.
Security and compliance gaps: AI surfaces attack vectors; legacy systems weren’t built to handle
Legacy systems weren’t designed with modern threat models in mind. AI integration creates new attack surfaces, model poisoning, prompt injection, and data exfiltration through inference outputs, which require governance frameworks legacy systems don’t have. In regulated industries (healthcare, financial services, education), this is a hard stop. You can’t deploy AI without the audit trails and access controls it requires, and most legacy systems don’t have them.
Model deployment complexity: nowhere to run inference at production scale
Even if you’ve built a capable AI model, deploying it to production requires infrastructure for serving predictions, monitoring outputs, retraining on new data, and rolling back bad versions. Legacy environments typically have none of this. MLOps is a discipline built for modern infrastructure. Legacy infrastructure can’t support it without significant re-engineering.
Why “Add an AI Layer” Doesn’t Work (And What Does)
The most common attempted shortcut, adding an AI middleware layer on top of the existing system, creates a new maintenance liability without solving the underlying problem. We’re going to say this plainly: it doesn’t work, and you should know why before you try it.
The non-invasive AI layer fallacy
The pitch sounds reasonable: don’t touch the legacy system. Build an AI layer on top that reads data from it, processes it, and sends outputs back. This way, you preserve existing functionality while adding AI capability.
Here’s what actually happens. The AI layer depends on data from the legacy system. The legacy system’s data quality is inconsistent. So the AI layer inherits the data quality problems. The AI layer also depends on the legacy system’s availability and performance. When the legacy system slows down, which it does, the AI layer degrades too. You’ve now doubled your maintenance surface without improving the underlying architecture.
The “non-invasive AI layer” approach works in narrow, well-scoped cases, reading from a clean, well-maintained data source to power a specific output. It doesn’t work as a general strategy for organizations whose core systems are architecturally broken.
What readiness actually requires: the structural prerequisites for viable AI integration
AI integration becomes viable when four structural conditions are met:
- The system has an API surface that can receive requests and return structured responses
- The data layer produces clean, consistent, trustworthy outputs that AI can use
- The infrastructure can scale to support inference workloads without degrading core system performance
- The governance and security posture meet the requirements of AI deployment introduce
These aren’t features you add on. They’re architectural conditions. Building them requires structural changes to the system, which is modernization, regardless of what you call it.
The Two Viable Paths: Sequential vs. Dual-Track Modernization
Two approaches to this problem actually work. Everything else is a workaround that defers the problem. Here’s how to choose between them.
Path 1: Modernize first, then add AI
Sequential modernization means treating legacy modernization and AI integration as two separate projects executed in order. You modernize the system first, decompose the monolith, clean the data, build the API layer, migrate to scalable infrastructure, and then integrate AI into the modernized platform.
This is the lower-risk path for organizations with significant regulatory exposure or where system downtime is unacceptable. It’s also the slower path. A full sequential modernization before any AI capability is realistic, takes 18–36 months for complex legacy environments. That’s a long time to wait in a market where competitors aren’t waiting.
Path 2: AI-augmented modernization, embedding AI capability as the foundation is rebuilt
The dual-track approach runs modernization and AI integration in parallel. Instead of modernizing the system and then building AI capability, you use AI tooling to accelerate the modernization itself, automated code analysis, AI-assisted migration, and smart testing, while simultaneously designing the modernized architecture to be AI-ready from the start.
The output isn’t a modernized legacy system that AI will eventually be added to. It’s a system whose architecture was designed with AI integration as a first-class requirement. AI features emerge from the same project that produced the modernized foundation.
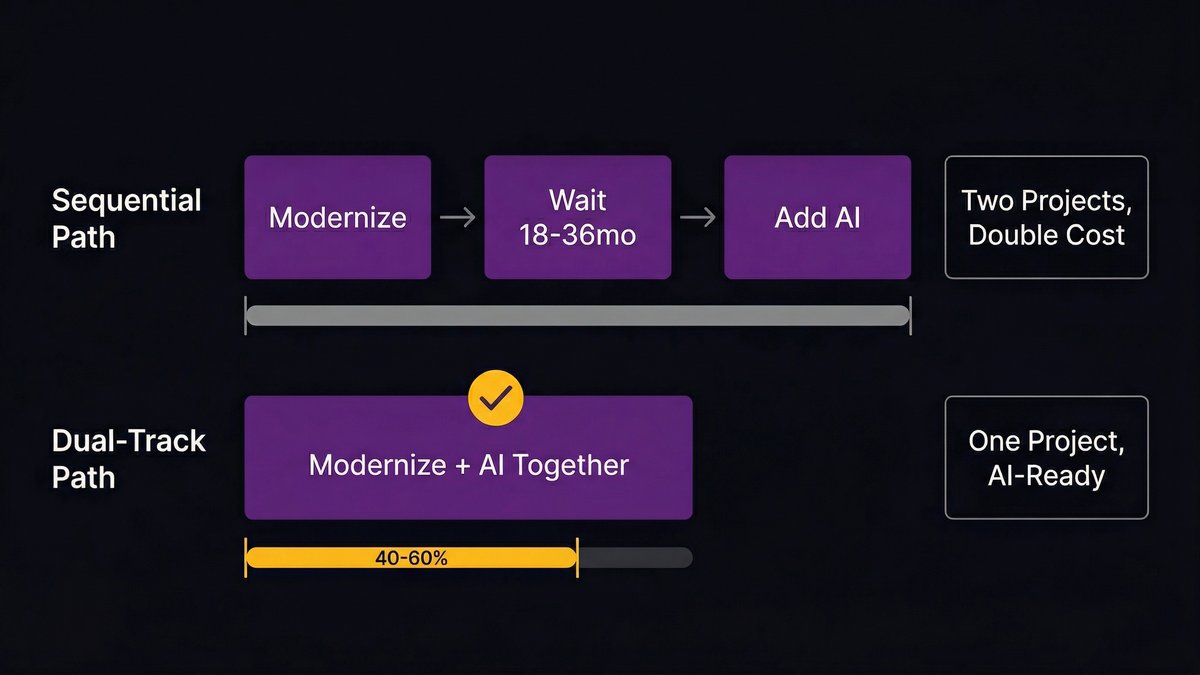
Why the dual-track approach compresses the timeline and eliminates the ‘two separate projects’ trap
The most expensive mistake organizations make is treating modernization and AI integration as sequential projects with separate budgets, teams, and timelines. This doubles the disruption and unnecessarily extends the timeline.
The dual-track approach produces the same outcome in roughly 40–60% of the time, because the modernization work is informed by AI integration requirements from day one. You don’t build a foundation and then retrofit it. You build a foundation that’s already designed for what you need it to do.
Legacy modernization delivers a 74% reduction in IT costs across hardware, software licensing, and staffing. When that modernization is paired with AI capability development in a single project, the ROI timeline compresses significantly, because you’re not paying for two separate transformations.
This is what Nexa Devs’ AI-augmented SDLC is designed to do. Rather than sequencing a modernization engagement followed by an AI integration engagement, the AI-augmented delivery process treats AI readiness as an architectural requirement that shapes the modernization work itself. The foundation and the capability come out of the same project.
Learn more about AI-augmented Software Development Life Cycle (SDLC) in our blog posts.
How to Assess Your AI Readiness: A Structural Checklist for CTOs
Your AI readiness comes down to four questions. If you can’t answer yes to all four, AI integration will fail or stall. Here’s how to evaluate each one honestly.
API surface area: Can your systems be decoupled?
Can you interact with specific business functions, read a customer record, trigger a transaction, query an inventory position, through a defined API? Or does accessing that function require going through the entire application?
If your answer is “we’d have to build an API layer first,” that’s the scope of your modernization project, not a pre-existing foundation. Document which functions need API exposure for your highest-priority AI use cases, and that list becomes your modernization roadmap.
Data accessibility: Is your data structured, accessible, and clean enough for training or inference?
Can you extract a clean dataset for any entity your business cares about, customers, products, orders, transactions, in a structured format without weeks of ETL work? Or is that data scattered across tables, partially duplicated, inconsistently formatted, or locked in a system with no export capability?
Data quality problems don’t get fixed by AI. They get inherited. The data your model trains on determines the quality of its outputs. If you can’t characterize your data quality today, your AI integration will produce results you can’t trust.
Infrastructure elasticity: Can your compute layer scale for AI workloads?
Production AI inference generates request volumes and compute demands that are qualitatively different from traditional transactional workloads. A server sized for 500 concurrent users running your ERP system may not have the headroom to run real-time inference alongside it.
Test this before you integrate. Run a load simulation that approximates your target AI use case alongside your normal production workload. If performance degrades, you need infrastructure changes before integration, not after.
Governance posture: Do you have the audit trails AI requires?
AI in production requires logging of model inputs and outputs, version control for models in deployment, rollback capability when model behavior degrades, and access controls that limit who can query the model and with what data. These aren’t optional in regulated industries; they’re required.
If your current system lacks audit logging, model governance, and an access control framework that can scope AI queries, that’s the infrastructure you need to build before deploying AI to production.

The Incremental Path: Modernizing Without a Big-Bang Rewrite
You don’t have to rewrite everything to get AI-ready. The strangler fig pattern gives you a path that keeps production running while the modernized architecture grows around it.
The strangler fig pattern applied to AI readiness
The strangler fig pattern replaces a legacy system incrementally. Rather than shutting down the old system and launching the new one on a fixed date, you build new services alongside the old system. Traffic is gradually routed to the new services as they’re validated. Over time, the old system is “strangled”, its functionality replaced piece by piece, until it can be decommissioned safely.
Applied to AI readiness, this means you don’t have to achieve full architectural modernization before getting any AI benefit. You identify the specific services that need to be API-enabled and data-clean to support your highest-priority AI use cases. You modernize those services first. You get a limited but functional AI integration while the broader modernization continues in the background.
This matters for mid-market organizations because it produces demonstrable progress without the all-or-nothing risk of a complete system replacement.
What the 5 R’s of modernization mean for AI integration sequencing
The five standard modernization strategies, Rehost, Refactor, Rearchitect, Rebuild, and Replace, have different implications for AI readiness:
Rehost (lift-and-shift to the cloud): improves infrastructure scalability and enables cloud-native AI services. Doesn’t fix data quality or API surface area problems. Good first step for infrastructure elasticity.
Refactor (optimize existing code without architectural change): reduces technical debt and improves maintainability. Minimal direct impact on AI readiness unless the data model or API surface is explicitly addressed.
Rearchitect (change the structure significantly): highest AI-readiness impact. Decomposing a monolith and building an API layer directly enables AI integration. The right choice for systems where architecture is the blocker.
Rebuild (rewrite from scratch on a modern stack): maximum AI readiness, maximum risk, and timeline. Justified only when the existing system is so degraded that incremental improvement isn’t viable.
Replace (commercial off-the-shelf replacement): fast but rarely full AI readiness, COTS systems have their own AI integration constraints. Evaluate AI capability as a selection criterion, not an afterthought.
Most mid-market modernization paths involve a combination: Rehost to improve infrastructure, Rearchitect to decompose the core, and targeted Rebuild for components too broken to salvage.
What Mid-Market Companies Get Wrong That Enterprise Guides Won’t Tell You
Most AI integration content is written for organizations with 5,000 employees, a dedicated AI team, and an 18-month runway. If that doesn’t describe you, the playbook doesn’t apply.
This is the conversation that rarely happens in vendor content, conference keynotes, or analyst reports: the advice being given to mid-market companies was designed for enterprises with fundamentally different constraints. Following it produces initiatives that stall, fail to achieve ROI, or require resources the organization doesn’t have.
Why enterprise modernization playbooks don’t scale down to $50M–$500M organizations
Enterprise AI integration programs have dedicated transformation teams, multi-year budgets, and the organizational tolerance for projects that take three years to show results. They can afford to run parallel tracks, absorb failed experiments, and maintain the legacy system indefinitely while the new architecture is built.
Mid-market companies can’t. They have one engineering team. They can’t afford to keep the old system running while building a new one if the new one is going to take 24 months. They don’t have the governance infrastructure that enterprise frameworks assume. And they don’t have the internal AI expertise to implement the recommended technical patterns.
Technical debt and outdated architectures directly affect how investors assess operational risk and future performance, particularly in M&A scenarios. For a mid-market company, this isn’t abstract: it’s what happens when a potential acquirer does technical due diligence and finds a system that can’t support modern integration. The deal structure changes, or the deal dies.
Mid-market-specific constraints: budget, team size, and risk tolerance
Three constraints define the mid-market AI integration problem:
Budget constraint. There’s no separate “AI transformation” budget. The money for AI integration comes from the same envelope as everything else. This means the approach has to produce value fast enough to justify continued investment, not in year three, but in year one.
Team size constraint. A five-person engineering team can’t run a modernization program, maintain production systems, and build AI features simultaneously. The math doesn’t work. Any strategy that requires expanding internal headcount by 50% to execute isn’t a strategy; it’s a prerequisite.
Risk tolerance constraint. A mid-market company can’t survive a six-month production outage during a system migration. The big-bang rewrite that failed to deliver for three years in a row isn’t just a cost problem; it’s an existential risk that the board will never approve again.
The right approach for mid-market organizations is narrow, staged, and designed to produce demonstrable results within the first 90 days. Start with the highest-value AI use case. Identify the minimum modernization work required to support that use case. Execute that first. Use the outcome to fund the next stage.
This is where an experienced nearshore partner with AI-augmented delivery capability outperforms both in-house teams and traditional project vendors. The nearshore model gives you senior engineering capacity without the headcount burden. The AI-augmented SDLC compresses timelines. And the dual-track approach means you’re not running two separate projects, you’re running one.
What are the 5 R’s of modernization?
The 5 R’s are Rehost, Refactor, Rearchitect, Rebuild, and Replace. For AI readiness, Re-architect has the highest impact; it decomposes monolithic systems and creates the API surfaces AI needs. Most mid-market paths combine Rehost (for infrastructure) with Rearchitect (for structure).
Why does legacy system AI integration fail so often?
It fails because legacy systems weren’t built to support AI workloads. They lack APIs, their data is siloed and inconsistent, and their infrastructure can’t scale for inference. Bolting an AI layer on top inherits these problems. Successful integration requires structural modernization, not just new tooling.
Can you add AI to a legacy system without a full rewrite?
Yes, for specific well-scoped use cases where the target data is already clean. The strangler fig pattern allows incremental modernization, replacing specific services one at a time while keeping the rest running. It produces AI capability without the all-or-nothing risk of a full rewrite.
How long does it take to make a legacy system AI-ready?
A focused use case via the strangler fig approach: 3–6 months. Enterprise-wide transformation: 12–24 months. The dual-track approach, modernizing and embedding AI simultaneously, compresses the overall timeline by 40–60% compared to sequential projects.
What’s the difference between a pilot and production AI integration?
A pilot run is performed against a clean, controlled dataset in isolation. Production integration runs against live data at full volume with real business consequences for errors. According to Gartner, 42% of AI pilots never reach production, usually because the underlying system can’t support production integration without structural changes.