
Table of Contents
The demo looked great. Your team wired up an AI agent in a staging environment, it called the right endpoints, processed the right data, and did exactly what the vendor promised. Then someone said, “Let’s run this in production.” And everything stopped.
That’s not an AI problem. It’s an infrastructure problem. AI agents require three things your legacy stack almost certainly doesn’t have: clean data contracts, observable system state, and an integration-ready architecture. When those three ingredients are missing, no model, however capable, can operate reliably in your environment. The agent doesn’t fail because it’s bad at reasoning. It fails because it’s driving blind through undocumented systems with inconsistent data and no way to recover from errors it can’t see.
This guide explains exactly what AI agents need, where legacy stacks fall short, and the incremental path forward that doesn’t require halting your current roadmap.
Quick answer: Why AI agents fail on legacy stacks
- AI agents require clean data contracts, observable systems, and integration-ready architecture; most legacy stacks have none of these.
- The failure point lies in the infrastructure, not the AI model itself.
- According to IDC, only 4 of every 33 AI pilots ever reach production, an 88% failure rate.
- The fix is incremental: establish data contracts, add observability, and rationalize documentation, in that order.
- Mid-market teams cannot halt their roadmap for a complete rewrite. A phased approach with a dedicated partner is the way to achieve it.
Your AI Agent Demo Worked. Your Production Environment Will Not.
The production failure isn’t a surprise; it’s predictable. Here’s why it keeps happening, and what the controlled POC environment is hiding from you.
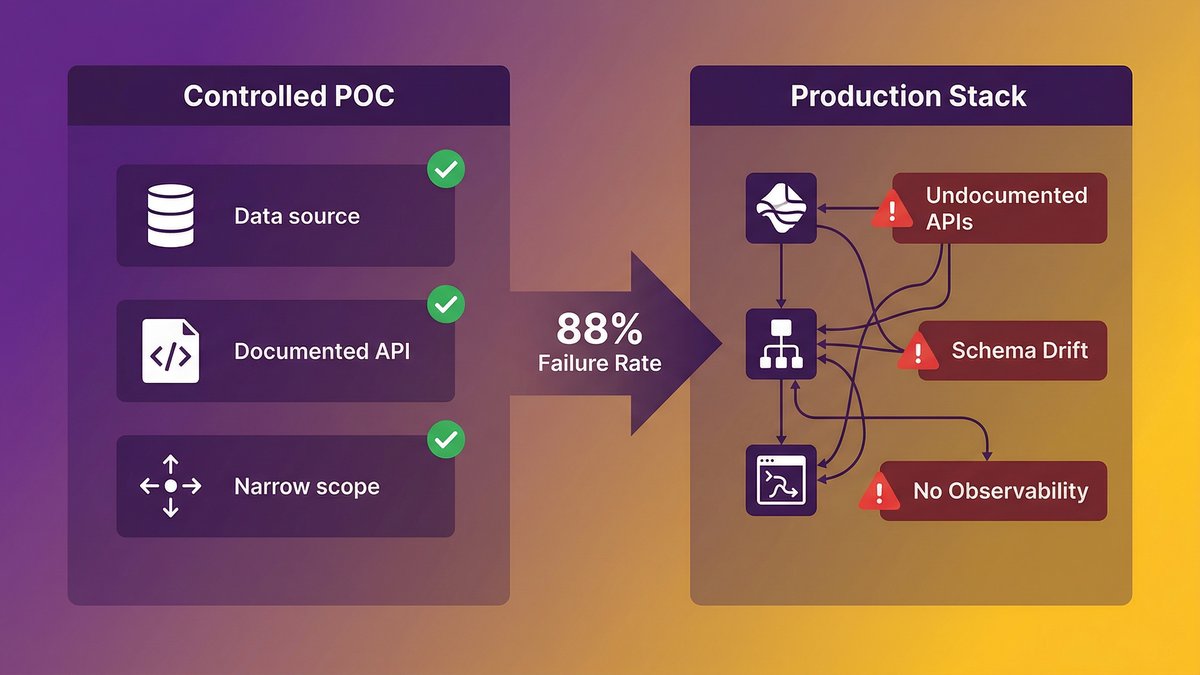
The gap between a controlled POC and your actual stack
A proof-of-concept (POC) environment is engineered to succeed. You pick a data source that’s reasonably clean, point the agent at a well-documented internal API, and keep the scope narrow enough that nothing breaks. That environment has almost nothing in common with your actual production stack.
Production environments carry 10–15 years of accumulated decisions, three generations of engineers, two ERP upgrades that never fully retired the old system, and a dozen internal APIs documented only in the heads of whoever built them. An AI agent navigating that environment isn’t doing the same job as an agent operating in a controlled sandbox. It’s operating inside a system that was never designed for autonomous traversal, with data that means different things in different places, and with no reliable way to signal when something has gone wrong.
The POC succeeded because you created the conditions for it to succeed. That’s not a failure of the demo; it’s a failure of the evaluation design.
According to Deloitte (2025), nearly 60% of AI leaders identify legacy-system integration as the primary barrier to agentic AI adoption. The problem isn’t a knowledge gap about what AI can do. It’s a structural gap between what AI agents need and what most enterprise stacks provide.
Why 88% of AI pilots never reach production
According to IDC research, for every 33 AI pilots launched, only 4 reach production, an 88% failure rate. That number is striking. But it’s not surprising once you understand what’s happening at the infrastructure layer.
POC environments abstract away the exact problems that kill production deployments: messy data, undocumented systems, brittle integrations, and missing observability. You’ve proven the model can do the job. You haven’t proven your infrastructure can support it doing the job at scale, under load, in an environment it can’t fully see.
The agent isn’t the variable. Your stack is.
What AI Agents Actually Require to Function at Scale
AI agents need three specific infrastructure capabilities before they can operate reliably in any environment. Here’s what each one means technically and why its absence causes production failure.
Clean data contracts: structured interfaces, not just any API endpoint
A data contract is a formal, versioned agreement about what data looks like at a system boundary, field names, data types, expected ranges, null handling, and update frequency. An AI agent issuing a tool call to retrieve customer order history needs to know the format it’ll receive back. If the response schema changes, even slightly, the agent’s reasoning can break in ways that are hard to detect and harder to debug.
Most legacy stacks don’t have data contracts. They have APIs that work, most of the time, for the people who built them. That’s a different thing. “Works for the team that built it” is not a contract. It’s institutional knowledge encoded into production behavior.
Clean data contracts mean the agent can call a tool, receive a predictable response, and take reliable action based on what it receives. Without them, you’re asking the agent to reason against an interface that shifts under its feet.
Observable systems: agents fail silently without a traceable state
Observability means you can answer three questions about any system component at any time: what is it doing, what state is it in, and when did that state last change. In a traditional user-facing application, a failure produces a visible error or an alert. An AI agent failing silently in a poorly observable system produces something worse: confident wrong answers.
If an agent calls an internal service and receives a stale cache response, it doesn’t know the data is three hours old. If an integration layer drops a message during high load, the agent doesn’t know the downstream action never completed. The agent continues reasoning as if its information is accurate, and the damage compounds.
Observable systems give agents the ground truth they need to detect anomalies, surface errors upstream, and stop rather than act on bad data.
Integration-ready architecture: what ‘agentic-ready’ means technically
An integration-ready architecture is one where services expose stable, callable tool endpoints; data flows through a layer that enforces consistency rather than around it; and access control is granular enough to let an agent take specific actions without requiring blanket system access.
Most legacy architectures weren’t designed with this model in mind. Integrations were built point-to-point, one-off, for specific use cases. The result is a web of dependencies that’s fragile, hard to extend, and nearly impossible for an autonomous agent to navigate without breaking something.
“Agentic-ready” isn’t a vendor marketing term. It’s a technical description of an architecture that supports autonomous system traversal without causing cascading failures.
The Legacy Stack Anatomy: Where AI Agents Break Down
Most legacy stacks fail AI agents in three specific places. Knowing which applies to your environment tells you where to start.
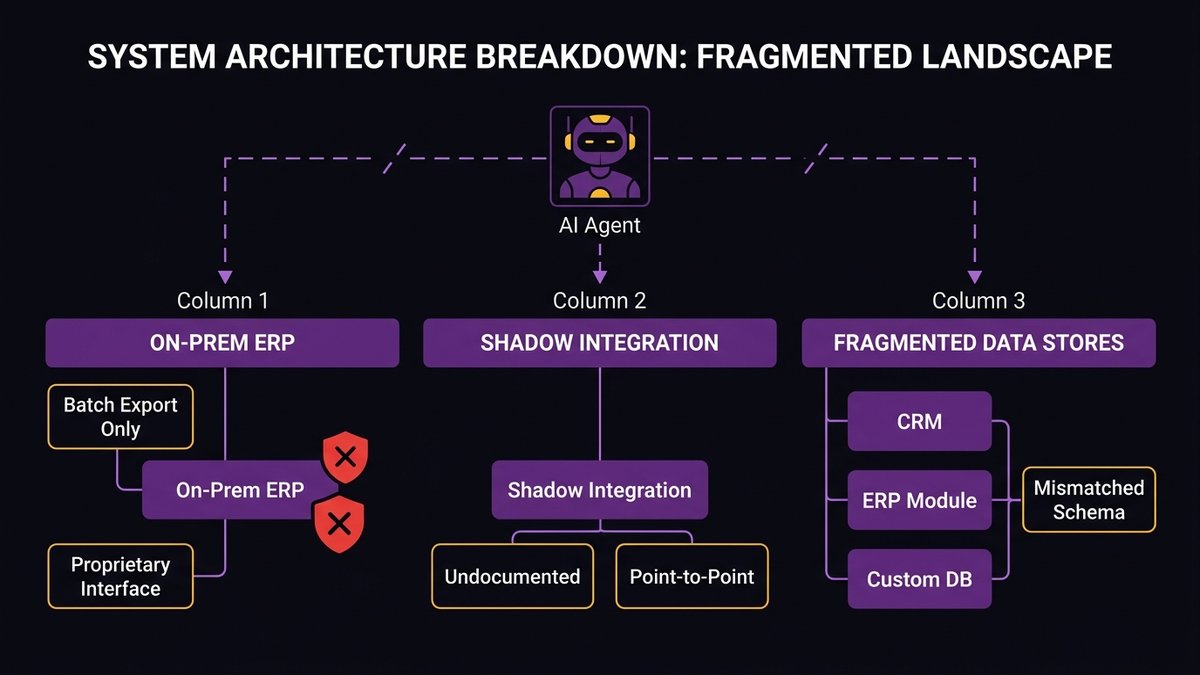
On-prem ERPs without modern APIs
On-premise ERP systems, especially those 10+ years old, were designed for deterministic, sequential workflows executed by human users. They expose data through batch exports, proprietary interfaces, or fragile middleware that was duct-taped together during a previous integration project.
An AI agent trying to query an on-prem ERP for live inventory data, update a purchase order, or retrieve customer history is working against a system that was never designed to be called programmatically at scale. The integration points exist, but they’re brittle, poorly documented, and not built to handle the query patterns that agentic workflows produce.
According to Forrester (2025), 70% of digital transformations are slowed by legacy infrastructure. On-prem ERPs are a primary reason.
Undocumented internal services and shadow integrations
Every mid-market company has them: internal APIs or services that were built by one engineer, used by one team, and never formally documented. They work. But “they work” means “the engineer who built them knows how to use them.” Anyone else, including an AI agent, is operating from guesswork.
Shadow integrations are worse. These are point-to-point data flows that exist outside the main integration layer, usually built by a team that needed something the official system didn’t provide. They’re often stateful, often undocumented, and often load-bearing. An AI agent encountering a shadow integration it can’t traverse will either fail silently or produce actions based on incomplete information.
Fragmented data stores with inconsistent schemas
A mid-market company running for 10+ years typically has customer data in at least three places: the original CRM, the ERP’s customer module, and a database built for a specific product or reporting workflow. The “customer ID” field in each system may refer to different things. Addresses may be formatted differently. Status fields may use different value sets.
For a human, this is annoying but manageable. For an AI agent, it’s a semantic landmine. The agent’s reasoning depends on consistent meaning across the data it processes. When the same concept carries different representations in different systems, the agent’s conclusions can be confidently, systematically wrong.
Why Most Agentic AI Initiatives Stall, And It’s Not the Model
The root cause of agentic AI stalls is architectural mismatch, not model quality. The evidence is consistent across industries and company sizes.
Integration complexity: 42% of enterprises need 8+ data sources for agents to function
According to Arion Research (2026), 42% of enterprises need access to 8 or more data sources to deploy AI agents successfully. That’s not 8 APIs in a clean microservices architecture, that’s 8 data stores that may have different schemas, different access patterns, and different consistency guarantees. Building the integration layer to support that data access cleanly is foundational work. Without it, agents either operate on partial information or require extensive manual preprocessing that defeats the purpose of automation.
According to ITBrief (2026), 57% of enterprises remain in a pilot stage for agentic AI, while only 15% have operationalized agents at scale. The pattern is consistent: pilots work in contained environments; production deployments stall at the integration layer.
The non-determinism mismatch: legacy systems are deterministic; agents are not
Legacy systems were designed for deterministic execution: input A always produces output B. Workflows are sequential, state is managed explicitly, and failures produce clear error codes. An AI agent operating in this environment introduces non-determinism; the agent decides dynamically what action to take based on reasoning, not a fixed flowchart.
Legacy systems weren’t built to handle this. They have no mechanism for an external actor to issue arbitrary tool calls in arbitrary sequences. They have no way to validate that the agent’s intended action is safe before executing it. They have no rollback path if the agent reasons incorrectly.
This isn’t a model problem. It’s an architecture problem. Non-deterministic agents require architectures designed for non-determinism: idempotent operations, reversible actions, and explicit state management.
Compliance and access control gaps that block autonomous execution
Most enterprise access control systems were designed for human users operating through a defined UI. Agent access is fundamentally different: programmatic, potentially high-frequency, and potentially cross-system. The access control model that works for a finance analyst using a dashboard doesn’t work for an agent that needs to read from five systems, write to two, and chain those operations into a single workflow.
This is a compliance risk, not just a technical inconvenience. An agent operating with overly broad access is an audit liability. An agent operating with overly narrow access can’t complete its task. The right answer, granular, task-scoped permissions per agent operation, requires an access control architecture that most legacy systems don’t have.
The Documentation Debt Problem: Agents Can’t Navigate What Isn’t Written Down
This is the gap no competitor covers. Documentation debt directly blocks AI agent deployment, and it’s the most invisible problem on most legacy stacks.
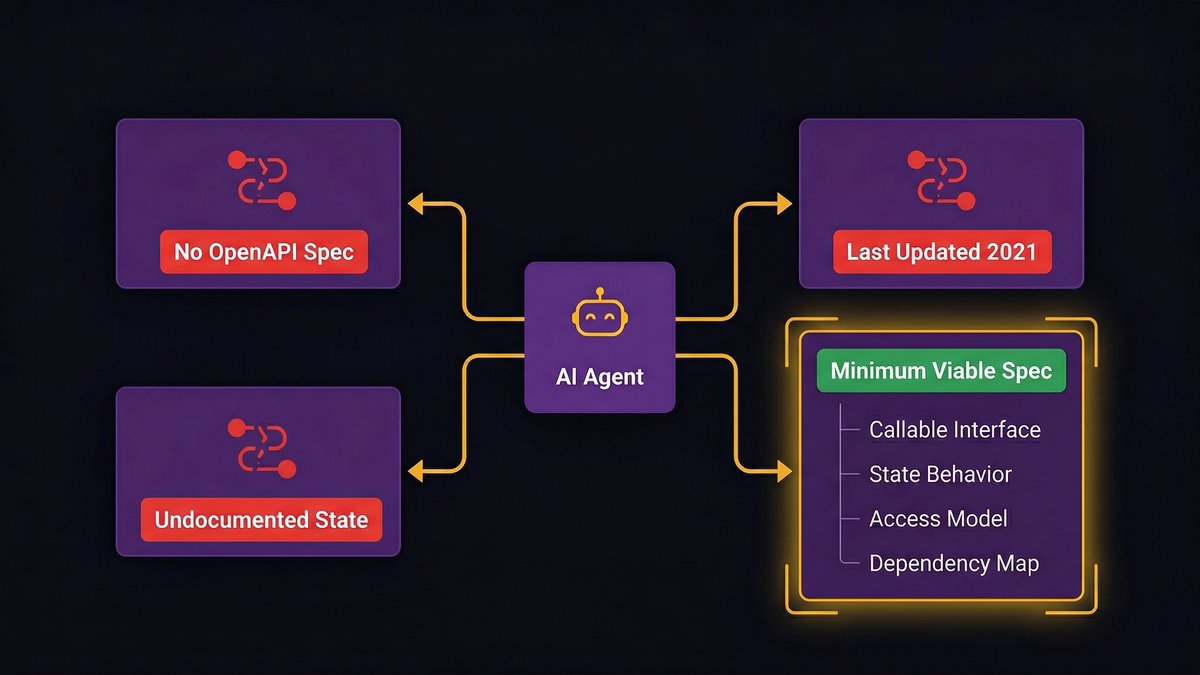
How undocumented systems block autonomous agent traversal
An AI agent navigating your internal systems needs to know what those systems do, what they accept as input, what they return, and what side effects their operations produce. That knowledge has to exist somewhere the agent can access it, in API documentation, OpenAPI specs, system descriptions, or structured tool definitions.
Most mid-market legacy stacks have critical services that exist only in production, documented only in the muscle memory of the engineers who built them. There are no OpenAPI specs. There’s a Confluence page last updated in 2021. There’s a Slack thread from 2019 where someone asked a question that was never fully answered.
An agent trying to traverse an undocumented service faces one of two outcomes: it hallucinates behavior based on partial information, or it fails. Neither is acceptable in a production workflow. The documentation isn’t the nice-to-have that gets done after the real work. It’s a prerequisite.
What system documentation an agentic environment actually needs
For an AI agent to operate reliably on a system, that system needs four things documented:
- Callable interface specification, what endpoints or functions the agent can invoke, with input/output schemas
- State behavior, what the system’s state looks like before and after each operation, including error states
- Access and authorization model, what credentials are required, what scope is granted, and what actions each scope permits
- Dependency map, what other systems this service calls, what it depends on, and what happens when those dependencies are unavailable
This isn’t enterprise documentation theater. It’s the minimum viable surface area for an agent to reason about a system without guessing.
How to Assess Your Stack’s Agentic Readiness Before Spending on AI Tooling
Before you buy agent orchestration platforms, evaluate this. The assessment takes less time than a vendor demo and tells you whether you’re ready to deploy agents at all.
A four-factor readiness checklist: APIs, data quality, observability, documentation
Run your stack against these four dimensions:
1. API coverage and stability
– Do your core business systems expose stable, versioned APIs?
– Are those APIs documented in a machine-readable format (OpenAPI/Swagger)?
– Have the APIs changed in the past 12 months without a versioning strategy?
If your answer to the third question is “yes, and we didn’t version it,” your APIs aren’t stable enough for agent use.
2. Data quality and schema consistency
– Do the same data concepts, customer, product, order, mean the same thing across systems?
– Are there canonical data definitions that all systems adhere to, or are schemas defined per-system?
– Is there a data dictionary, even an informal one?
If your engineering team can’t agree on what a “customer ID” refers to across systems, agents will compound that disagreement at scale.
3. Observability and traceability
– Can you trace the execution path of any system call end-to-end?
– Do your services emit structured logs that capture state changes?
– Do you have alerting on service degradation, not just outright failure?
An agent operating in an unobservable system is a black box inside a black box. Production incidents become impossible to diagnose.
4. Documentation coverage
– What percentage of your internal services have current, accurate API documentation?
– What percentage of your internal services are documented only in someone’s head?
– When was your system architecture documentation last updated?
Be honest with the last question. “Last updated when the system was built” means it’s out of date.
Red flags that indicate your stack will block agent deployment
Some patterns are unambiguous blockers. If your stack shows any of these, agents will fail, and the failure will be expensive to diagnose:
- Point-to-point integrations with no abstraction layer, the integration breaks if either endpoint changes, and agents can’t navigate point-to-point webs reliably
- Batch-only data access, agents need near-real-time data; batch exports introduce staleness that breaks agent reasoning
- No structured error responses, if your services return HTML error pages or unstructured text on failure, agents can’t handle errors gracefully
- Overly permissive service accounts, if the only way to access a service is with an account that has full admin rights, deploying an agent means deploying a full admin into production
According to McKinsey (2025), 62% of organizations experiment with AI agents, yet only 23% successfully scale them. The gap between 62% and 23% lives in exactly these infrastructure gaps.

The Modernization Path: Building an Agentic-Ready Foundation
The path to agentic readiness is incremental, not a rewrite. Three steps, in this order.
As Cesar DOnofrio, CEO and co-founder of Making Sense, states: “When legacy systems limit access to reliable data, slow down integration across workflows, or make change deployment complex and time-consuming, AI initiatives stop being strategic levers and become isolated experiments.”
That’s the problem. Here’s the sequence to fix it.
Step 1: Establish data contracts and API standards
Start with the systems your intended AI agents will actually touch, not your entire stack. Identify the three to five services that represent the highest-value automation opportunity and define data contracts for each:
- Formalize the input/output schema for every endpoint agents will call
- Introduce semantic versioning so schema changes don’t silently break dependent consumers
- Build a thin API gateway or abstraction layer over legacy services that lack stable interfaces, the abstraction layer is what the agent calls; the legacy system sits behind it
This is not a 12-month initiative. For three targeted services, a small team can produce usable data contracts in six to eight weeks. You’re not rewriting the system, you’re defining its interface.
Step 2: Add observability and system traceability
Before you deploy agents, instrument the systems they’ll operate on:
- Add structured logging to every service in the agent’s execution path, capture inputs, outputs, state changes, and error conditions
- Set up distributed tracing so you can follow a single agent-initiated workflow across multiple service calls
- Define alerting on agent-specific failure modes: repeated retry loops, anomalous call volumes, unexpected null responses
Observability isn’t optional. It’s the difference between a production incident that takes four hours to diagnose and one that takes 20 minutes. Deploy agents without it and you’ll spend more time firefighting than the agents save.
Step 3: Incrementally document and rationalize legacy services
Documentation debt compounds. Each undocumented service is a blocker for every future AI agent that might need to interact with it. The solution isn’t a documentation sprint, it’s a documentation discipline built into ongoing engineering work:
- Every service that enters an agent’s scope gets a minimum viable spec: callable interface, state behavior, access model, dependency map
- Engineers working on legacy services document as they go, not at the end of the project
- Shadow integrations get inventoried, documented, and either formalized or eliminated
This is where an AI-augmented development process produces a compounding advantage. Nexa’s engineering workflow produces system documentation as a standard deliverable on every engagement, not as an after-the-fact artifact, but as part of the development cycle itself. That means systems built or modernized under Nexa’s model arrive with the documentation agentic deployments need. Find out more on the AI-augmented SDLC blog post
Why Mid-Market CTOs Need a Different Modernization Model Than Enterprise
Enterprise companies fix this problem by hiring. Mid-market companies can’t. That’s a different constraint, and it demands a different solution.
The talent and capacity constraint: you can’t halt your roadmap for a 2-year rewrite
A Series B SaaS company with 8 engineers carrying a legacy ERP, a live product roadmap, and a growing list of integration requests has a specific problem: there’s no bandwidth to simultaneously maintain current operations and build the agentic-ready foundation. The engineers who know the legacy systems are the same engineers the product roadmap depends on. You can’t pull them off to do modernization work without the product stalling.
A large enterprise can staff a parallel modernization team. It can absorb an 18-month runway on infrastructure investment. It can tolerate the velocity hit while the foundation gets rebuilt. Most mid-market companies can’t do any of those things.
This is not a weakness, it’s a constraint that defines the right approach. The right model for mid-market isn’t a full rewrite. It’s incremental modernization scoped to the highest-value AI use cases, executed in parallel with the ongoing roadmap, producing usable outputs at each phase rather than a single big-bang delivery at the end.
AI-augmented nearshore teams as a force multiplier for legacy modernization
The nearshore model exists precisely to solve the capacity constraint. A dedicated team of senior engineers, operating in your timezone, integrated into your Scrum workflow, can absorb the legacy modernization work that your internal team can’t pick up without stalling the product.
AI-augmented delivery accelerates this further. The same AI-native process that produces clean documentation as a standard output also reduces the time required to understand, assess, and modernize legacy systems. What would take a traditional team 12 months can take an AI-augmented team significantly less. Not because the underlying complexity is different, but because the tooling surfaces that complexity faster, generates the specifications and tests that legacy systems lack, and produces documentation continuously rather than at project close.
Nearshore is not outsourcing. It’s not a vendor that disappears after delivery. Done correctly, it’s an embedded engineering partnership that accumulates institutional knowledge about your systems, the antidote to the key-person dependency that makes legacy modernization so risky in the first place.
If you want to know where your stack stands against the four agentic readiness factors, it starts with exactly that diagnostic. Most CTOs who’ve run one come out with a shorter list of actual blockers than they expected, and a clearer roadmap for removing them.
The Bottom Line
Most CTOs I talk to already know their stack isn’t ready for AI agents. What they’re looking for isn’t a diagnosis, it’s a path forward that doesn’t require pausing everything else to build it.
The path exists. It’s incremental, it’s scoped to the highest-value use cases first, and it produces agentic-ready infrastructure in phases rather than as a single 18-month delivery. The companies that figure this out in 2026 will have a durable advantage over the ones still running pilots in 2027.
Your infrastructure is the variable. Fix that, and the agents work.
Ready to find out exactly where your stack stands? Book a software architecture assessment with Nexa Devs, and we’ll map your environment against the four agentic readiness factors and tell you what needs to change before you spend another dollar on AI tooling.
FAQ
Can AI agents work with legacy systems without a full rewrite?
Yes, but only if specific infrastructure prerequisites are in place first. AI agents need stable API interfaces, observable system state, and documented data contracts. You can build an abstraction layer over legacy systems without rewriting the underlying system. A full rewrite is rarely necessary.
What infrastructure do you need before deploying AI agents in the enterprise?
Three things: clean data contracts (formal, versioned schemas at system boundaries), observable systems (structured logging, distributed tracing, error alerting), and an integration-ready architecture with stable, callable endpoints and granular access control. Missing any one of these causes production failures that are difficult to diagnose.
Why do AI agents fail in production when the demos worked fine?
POC environments are controlled, clean data, documented APIs, narrow scope. Production carries years of complexity: undocumented services, inconsistent schemas, brittle integrations. According to IDC, only 4 of every 33 AI pilots reach production. The demo succeeded because conditions were engineered for success, not because the stack was ready.
How do you assess whether your tech stack is ready for agentic AI?
Evaluate four factors: API coverage and stability, data schema consistency across systems, observability and traceability, and documentation coverage. Red flags include point-to-point integrations, batch-only data access, unstructured error responses, and overly permissive service accounts.
What is the biggest barrier to scaling AI agents in mid-market companies?
Infrastructure, not model capability. According to Deloitte (2025), nearly 60% of AI leaders identify legacy-system integration as the primary barrier to agentic AI adoption. For mid-market companies, the compounding constraint is bandwidth: engineers who know legacy systems are the same ones carrying the product roadmap.
How do undocumented APIs and legacy codebases block AI agent deployment?
An AI agent navigating an undocumented system has no reliable interface specification, no state behavior to reason against, and no dependency map to avoid breaking. It either hallucinates behavior from partial information or fails. Documentation is a deployment prerequisite, not a post-project deliverable.